Download

1 / 25
250 likes | 346 Views
Performance Considerations of Data Acquisition in Hadoop System. Baodong Jia , Tomasz WiktorWlodarczyk , Chunming Rong Department of Electrical Engineering and Computer Science University of Stavanger Namrata Patil. Contents…. Introduction Sub projects of Hadoop

E N D
Performance Considerations of Data Acquisition in Hadoop System BaodongJia, Tomasz WiktorWlodarczyk, ChunmingRongDepartment of Electrical Engineering and Computer ScienceUniversity of Stavanger NamrataPatil
Contents….. • Introduction • Sub projects of Hadoop • Two solutions for data acquisition • Workflow of Chukwa system • Primary components • Setup for Performance Analysis • Factors Influencing Performance Comparison • Conclusion Department of computer science & Engg
Introduction • Oil and Gas Industry • Drilling done from service companies http://bub.blicio.us/social-media-for-oil-and-gas/ Department of computer science & Engg
Continued… • Companies collect drilling data by placing sensors on drilling bits and platforms and make it available on their servers. Advantages • Drilling status • Operators can get useful information on the historical data Problems • Vast amounts of data are accumulated • Infeasible or very time consuming to perform • reasoning over it Solution Investigate application of MapReduce system Hadoop http://bub.blicio.us/social-media-for-oil-and-gas/ Department of computer science & Engg
Sub projects of hadoop 1. Hadoop Common 2. Chukwa 3. Hbase 4. HDFS HDFS - Distributed File System • stores application data in a replicated way • high throughput Chukwa - An open source data collection system • designed for monitoring large distributed system. Department of computer science & Engg http://hadoop.apache.org/
Two solutions for data acquisition.. Solution 1 Acquiring data from data sources, and then copying the data file to HDFS Solution 2 Chukwa based Solution Department of computer science & Engg
Solution 1 • Hadoop runs MapReduce jobs on the cluster • Stores the results on HDFS Steps • Prepare the required data set for the job • Copy it to HDFS • Submit the job to hadoop • Store the result in a directory specified by user on HDFS. • Get the result out of HDFS Department of computer science & Engg
Pros & Cons… Pros… • Works efficiently for small number of files with large file size Cons… • Takes a lot of extra time for large number of files with small file size • Does not support appending file content Department of computer science & Engg
Solution 2 • Overcome the problem of extra time generated by copying large file to HDFS • Exists on top of Hadoop • Chukwa feeds the organized data into cluster • Uses temporary file to store the data collected from different agents. http://incubator.apache.org/chukwa/ Department of computer science & Engg
Chukwa • Open source data collection system built on top of Hadoop. • Inherits scalability and robustness • Provides flexible and powerful toolkit to display, monitor, and analyze results http://incubator.apache.org/chukwa/ Department of computer science & Engg
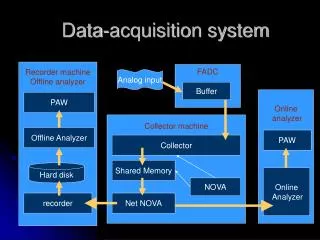
Workflow of Chukwasystem Department of computer science & Engg
Primary components….. • Agents - run on each machine and emit data. • Collectors -receive data from the agent and write it to stable storage. • MapReduce jobs - parsing and archiving the data. • HICC - Hadoop Infrastructure Care Center a web-portal style interface for displaying data. http://incubator.apache.org/chukwa/docs/r0.4.0/design.html Department of computer science & Engg
Continued… Agents • Collecting data through their adaptors. • Adaptors - small dynamically-controllable modules that run inside the agent process • Several adaptors • Agents run on every node of hadoop cluster • Data from different hosts may generate different data. http://incubator.apache.org/chukwa/docs/r0.4.0/design.html Department of computer science & Engg
Collectors • Gather the data through HTTP • Receives data from up to several hundred agents • Writes all this data to a single hadoop sequence file called sink file • close their sink files, rename them to mark them available for processing, and resume writing a new file. Advantages • Reduce the number of HDFS files generated by Chukwa • Hide the details of the HDFS file system in use, such as its Hadoop version, from the adaptors http://incubator.apache.org/chukwa/docs/r0.4.0/design.html Department of computer science & Engg
MapReduce processing Aim • organizing and processing incoming data MapReduce jobs Archiving- take chunks from their input, and output new sequence files of chunks, ordered and grouped Demux - take chunks as input and parse them to produce ChukwaRecords ( key – value pair) http://incubator.apache.org/chukwa/docs/r0.4.0/design.html Department of computer science & Engg
HICC - Hadoop Infrastructure Care Center • Web interface for displaying data • Fetches the data from MySQL database • Easier to monitor data http://incubator.apache.org/chukwa/docs/r0.4.0/design.html Department of computer science & Engg
Setup for Performance Analysis • Hadoop cluster that consists of 15 unix hosts that existed at the unix lab of UIS • One tagged with name node and the others are used as data nodes. • Data stored at data nodes in replicated way Department of computer science & Engg
Factors Influencing Performance Comparison • Quality of the Data Acquired in Different Ways • Time Used for Data Acquisition for Small Data Size • Data Copying to HDFS for Big Data Size. Department of computer science & Engg
Quality of the Data Acquired in Different Ways • Sink file size = 1Gb • Chukwa agent check the • file content every 2 seconds The Size of Data Acquired by Time Department of computer science & Engg
Time Used for Data Acquisition for Small Data Size • Time used to acquire data • from servers • Put acquired data into HDFS Actual Time Used for Acquisition in a Certain Time Department of computer science & Engg
Data Copying to HDFS for Big Data Size. • Slope of line is bigger when replica number is bigger Time Used to Copy Data Set to HDFS With Diferent Replica Number Department of computer science & Engg
Critical Value of Generating Time Differences Critical value Corresponding size of data file for generating time difference of data acquisition Time used for copying according to the size of data set with replica number of 2 Department of computer science & Engg
Continued… Time used for copying according to the size of data set with replica number of 3 Department of computer science & Engg
Conclusion….. Chukwa was demonstrated to work more efficiently for big data size, while for small data size there was no difference between the solutions Department of computer science & Engg
Thanks.. Department of computer science & Engg