Download

1 / 42
420 likes | 594 Views
Title Bayesian Estimates of Potential Output and NAIRU for Taiwan. Shin-Hui Chen (陳馨蕙) Department of Economics, National Dong Hwa University. Jin-Lung Lin ( 林金龍 ) Department of Finance National Dong Hwa University. Introduction. 1. Econometric Models. Section. 2.

E N D
TitleBayesianEstimates of Potential Output and NAIRU for Taiwan Shin-Hui Chen (陳馨蕙) Department of Economics, National Dong Hwa University • Jin-Lung Lin (林金龍) • Department of Finance • National Dong Hwa University
Introduction 1 Econometric Models Section 2 Sampling Algorithms for Bayesian State Space Models 3 The Monte Carlo Simulation 4 Application to Taiwan’s Seasonally Unadjusted Data 5 Motivation and Framework • This paper aims to develop the corresponding Bayesian • sampling algorithms for Watson’s decomposition method • and Apel and Jansson’s systems approach. Section 3 Section 4 e Section 5 le Section 2
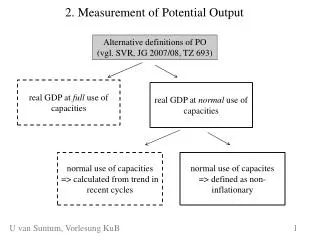
2. Econometric Models 2.1 A Summary of SSM and Kalman Filter 2.2 Watson’s Decomposition 2.3 Apel and Jansson’s decomposition
A Brief Summary of SSM and Kalman Filter Observation Equation • A general state space model can be written as: where θt, Yt, Vt, Wt are the state variables, observed variables measurement error terms, and disturbance terms, respectively. Ft and Gt are known matrices and could be time-varying or time-invariant. • The state variables t is assumed to follow Gaussian distribution and 0 has initial prior System Equation Dt−1 denote the information provided by set of past observations Y1, · · · , Yt−1
A Summary of SSM and Kalman Filter (Cont.) • Our interest is to compute the conditional densities p(θs|Dt). • When s = t, the Kalman Filter recursion is applied to compute the conditional densities, p(θs|Dt). • If θt−1|Dt−1~N(mt−1,Ct−1), then the Kalman Filter for model (1) is
A Summary of SSM and Kalman Filter (Cont.) • When s < t, the concept of smoothing is applied. If then the smoothing recursion for model (1) is Excellent exposition of DLM can be found in West and Harrison (1997), Koopman and Ooms (2006) and Petris, Petrone and Campagnoli (2009).
Watson’s Decomposition • Watson (1986) decomposed observed GDP as the sum of potential GDP and output gap and the model is listed below • For seasonally unadjusted series, we frequently observe seasonal unit root rather than regular unit root We replace the random walk equation with seasonal unit root equation and keep the specification of output gap unchanged
Apel and Jansson’s Decomposition Apel and Jansson (1999) added inflation rates and unemployment to the model. Output and employment is linked via Okun’s law while the relationship between output and inflation is governed by Phillips curve.
3. Sampling Algorithms for Bayesian State Space Models 3.1 Sampling the States from p(θ0:T |ψ, y1:T ):FFBS Algorithm 3.2 Sampling the Unknown Parameters from p(ψ|θ0:T , y1:T ) 3.3 Algorithm for Watson’s Model 3.4 Algorithm for Apel and Jansson’s Model
MCMC and Gibbs Sampling • Consider a general DLM model as model (1), our primary interest is the joint conditional distribution of the state vectors and the unknown parameters given the data where y1:T and θ0:T denote the data (y1, · · · , yT) and (θ0, · · · , θT), respectively. • To achieve greater efficiency, Markov Chain Monte Carlo (MCMC) and in particular Gibbs sampling algorithm are used for approximating the joint posterior p(θ0:T , ψ|y1:T ).
Algorithm 1 Gibbs Sampling Algorithm FFBS Conjugated Priors M-H Algorithm
Forward Filtering Backward Sampling (FFBS) The Forward Filtering Backward Sampling (FFBS) algorithm (Carter and Kohn,1994; Fruhwirth-Schnatter,1994) provides a more efficient way to sample the full set θ0:T from the complicated and high-dimensional full posterior. Note that the last factor in the product, p(θT |DT ), is exactly the Kalman filter.
Algorithm 2: FFBS Algorithm FFBS Conjugated Priors M-H Algorithm FFBS is essentially a simulation version of the smoothing recursions. Excellent summaries of FFBS can be found in Doucet, Logothetis and Krishnamurhty (2000), Petris, Petrone and Campagnoli (2009) and Cargnoni, Muller and West (2010).
Conjugate Priors—Normal Gamma Priors • Typically, we can decompose the unknown parameters into two components, the unknown coefficients (β)and the disturbance (σ2). • When were known (drawn by FFBS algorithm), the state space model would reduce to a normal linear regression model and the unknown parameters are conditionally conjugated (see e.g., Durbin and Koopman, 2002; Koop, 2003 §4).
The Metropolis-Hastings Algorithm • However, in practice the unknown coefficients (β) can be multidimensional and their posterior distribution depends heavily on the model specification. • In Stock and Watson’s model, for example, the potential GDP follows a random walk while the output gap is an AR(2) process. • In this case, p(1|2) does not have a standard form and is difficult to simulate from.
Algorithm 3 Metropolis-Hastings Algorithm This is not the first paper that samples an intractable posterior distribution arises in a stationary AR(2) process by Metropolis-Hastings algorithm. For example, see Chib and Greenberg (1994).
3.4 Algorithm for Apel and Jansson’s Model • Empirical analysis indicates that inflation and output depend negatively on lagged cyclical unemployment by the parameters (η1, η2) and (1, 2), respectively (see e.g., Apel, 1999; Schumacher, 2008).
4. The Monte Carlo Simulation 4.1 A Simulation Study for Watson’s Model 4.2 A Simulation Study for for Apel and Jansson’s Model
Fig 1: Estimated results of Watson’s model with simulated data Estimated Simulated
Table 2: Model Calibration and the Estimating Results of Apel’s model
Figure 3: Estimated Results of Simulated Apel and Jansson’s model Simulated unemployment gap Simulated output gap The evolution of estimated the output gap and the unemployment gap are almost identical to their respective simulated series. Estimated Estimated
Table 2: Model calibration and the estimating results of Apel’s model Second, the ML estimates of the standard deviations, σ’s, tend to be smaller than their corresponding posterior means. This example indeed shows that our Bayesian sampling algorithms are practical and flexible and do not merely duplicate the ML estimates. First note that the posterior means of δ’s, η’s and ’s are much closer to their true values than the ML estimates.
Figure 4: Prior and posterior distribution of parameters • The bivariatescatterplots of (1, 2), (δ1, δ2) and • (η1, η2), together with their corresponding marginal • histograms show that there is a strong dependence • between (1, 2), (δ1, δ2) and (η1, η2). • This confirms that drawing these pairs of parameters • simultaneously is essential in improving the mixing of • the chain. These summaries demonstrate that the initial prior brief has only a modest effect on the posterior shrinkage.
5 Application to Taiwan’s Seasonally Unadjusted Data 5.1 Results for Watson’s Model 5.2 Results for Apel and Jansson’s Model
Previous Literature on Taiwan’s Potential Output and NAIRU • Lin and Chen (2010) document that there appears to be a rising trend in the Taiwan’s unemployment gap, possibly as a result of structural changes or the periodicity of the cycle become longer. • Distinct classes of NAIRU specifications are implemented to mitigate the concern about implausible estimates and misspecification. • Lin and Chen (2010) documented that specifying the unemployment gap as an integrated AR(1) process leads a dramatic decline in the sum of δ’s and both the unemployment gap and output gap became more stable. . Estimating potential output and NAIRU for Taiwan with conventional, methods is problematic !!!
The Application to Taiwan • With appropriate priors, prior information about the structure of the economy based on theory and country-specific circumstance can be embedded in models (Waliszewski, 2010) • We take Lin and Chen’s (2010) estimates as a reference for the prior means but leave a considerable amount of uncertainty around the prior variances.
Results of Watson’s model with real data—Table3 and Figure 5 Comparison of the posterior means of σz and σy show that the transitory component plays a major role in the output fluctuations. First, when seasonal unit root is explicitly considered, the estimates of the states exhibit no seasonal fluctuation.
Figure 6: Estimated Results of Apel and Jansson’s Model with Real Data The recession in the 2000s appears to be very severe compared to Watson’s univariate model. The financial crisis of 2008 further induced sharp increase in the NARIU. First, when seasonal unit root is explicitly considered, the estimates of the states exhibit no seasonal fluctuation.
Table 4: Empirical results of Apel’s model Table 4 shows that the 95% posterior interval traps the ML estimates for most unknown coefficients (δ’s, η’s, ’s and α). The posterior standard deviations of unknown parameters and their corresponding standard errors generally exceed the standard errors reported by the ML
Table 4: Empirical results of Apel’s model 1. Traditional Kalman filter (ML) puts too little weight on the variance of the permanent component. 2. Bayesian estimates also allow for more stochastic variation in the cyclical component, the unemployment gap and output gap.
Red line : Bayesian(AR2), the Bayesian estimates with AR(2) cyclical unemployment. • Black line : ML(AR2) denotes the maximum likelihood estimates with AR(2) cyclical unemployment. • Blue line: ML(DAR1) the maximum likelihood estimates with an integrated AR(1) process. Figure 7: Comparison between the Bayesian State Estimates and the ML State Estimates
The similarity between the Bayesian output gap and the ML(DAR1) output gap demonstrates that the Bayesian framework is rich enough to cope with model misspecification and identification problems. • Compared to the ML(AR2) output gap (black line), the Bayesian(AR2) output gap is slowly trending downwards and contains a more pronounced cyclical pattern. • What is particularly striking is that without any particular model specification, the path of the Bayesian output gap is almost the same as the path of ML(DAR1) output gap (the blue line). Figure 7: Comparison between the Bayesian State Estimates and the ML State Estimates
Comparison between the Bayesian State Estimates and the ML State Estimates Although the posterior means of δ’s are almost the same as the ML estimates, we find that the posterior distribution indeed allows for more parameter uncertainty
Even with same model specification, the Bayesian(AR2) output gap is slowly trending upwards and presents a significantly more negative unemployment gap during 1987 to 1999. Figure 7: Comparison between the Bayesian State Estimates and the ML State Estimates All the unemployment gap estimates show that the economy has experienced a significant increase in the unemployment gap during 2000s.
Summary • This paper develops the corresponding Bayesian sampling algorithms for Watson’s decomposition method and Apel and Jansson’s system approach. • Simulation and empirical analyses show that our Bayesian sampling algorithms are flexible and do not merely duplicate the maximum likelihood estimates. • We find that the maximum likelihood generally understates the parameter variability and puts too little weight on the variance.
Summary • While a Bayesian approach allows for more stochastic variation in the permanent and cyclical component • Our results demonstrate that the posterior distribution facilitates assessment of the parameter uncertainty. • A Bayesian approach is rich enough to cope with model specification issues and provides more relevant information for conducting monetary and fiscal policies .