Download

1 / 22
220 likes | 363 Views
Crossing the Structure Chasm. Jayant Madhavan Database Group University of Washington. The Structured Realm. Conventional Wisdom Data Management: all about relational databases, OODBs, … Schemas: define structure of the data, are strictly adhered to.

E N D
Crossing the Structure Chasm Jayant Madhavan Database Group University of Washington
The Structured Realm • Conventional Wisdom • Data Management: all about relational databases, OODBs, … • Schemas: define structure of the data, are strictly adhered to. • Querying using expressive languages such as SQL. • Implications • Significant design and maintenance effort. • Data sharing requires knowledge and understanding of schemas. • Very precise answers to fairly rich queries. • Most of the data is NOT in the structured realm. Crossing the Structure Chasm
The Unstructured Realm • Text documents, flat files, web-pages, … • No schema easy to author – just write text • Sharing is very simple • Simple querying – keyword queries like in Google • Very limited query model • Keyword queries are not expressive enough Crossing the Structure Chasm
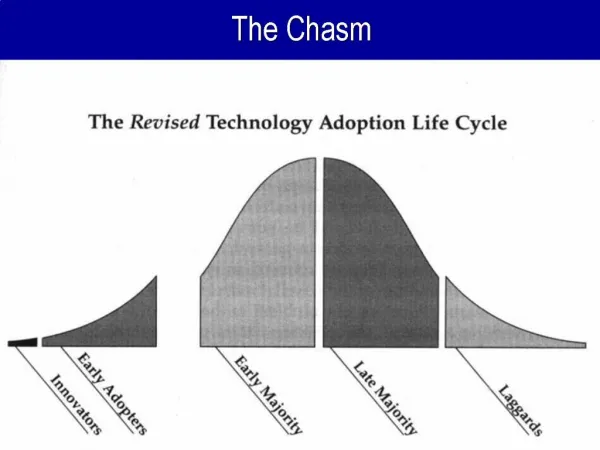
The Chasm Crossing the Structure Chasm
Crossing the Chasm • Import properties from U-WORLD to S-WORLD • Make it easier to create structured data • Make it easier to query and share structured data • Make it easier to handle schema and model heterogeneity Crossing the Structure Chasm
Outline • The Structure Chasm • Three research directions • Authoring using Mangrove • Peer-based data sharing using Piazza • Schema matching solutions • Summary Crossing the Structure Chasm
Mangrove • Goals: • Encourage the creation of structured data • Incremental creation of the semantic web • Mechanisms: • Make it easy to add structure to existing data • Provide instant gratification • Status: • Local prototype implementations, e.g. UW CSE semantic calendar Crossing the Structure Chasm
Piazza • Goal: • Large scale autonomous sharing of structured data • Peer data management system (PDMS) • Autonomous Peers export data in their own schemas • Pair-wise mappings between peers • Generalization of a Data Integration system • NOT a P2P file sharing system Crossing the Structure Chasm
Area(areaID, name, descr) Project(projID, name, sponsor) ProjArea(projID, areaID) Pubs(pubID, projName, title, venue, year) Author(pubID, author) Member(projName, member) Members(memID, name) Projects(projID, name, startDate) ProjFaculty(projID, facID) ProjStudents(projID, studID) … Direction(dirID, name) Project(pID, dirID, name) … Project(projID, name, descr) Student(studID, name, status) Faculty(facID, name, rank, office) Advisor(facID, studID) ProjMember(projID, memberID) Paper(papID, title, forum, year) Author(authorID, paperID) Area(areaID, name, descr) Project(projID, areaID, name) Pub(pubID, title, venue, year) PubAuthor(pubID, authorID) PubProj(pubID, projID) Member(memID, projID, name, pos) Alumn(name, year, thesis) Peer Data Management • Mappings are query expressions • DbResearcher(x)Researcher(x),Area(x,DB) • DbResearcher(x), Office(x,DBLab)=DbLabMember(x) DB Projects MIT UW Stanford UCB Crossing the Structure Chasm
Query Answering • Problem • Evaluate query Q at P1 given a network of mappings • Reformulate the query over all relevant peers • Chaining of mappings using a combination of query composition and query rewriting • QP1(x) :- DbResearcher(x) • Query Composition • M: DbResearcher(x)Researcher(x),Area(x,DB) QP2 (x) Researcher(x),Area(x,DB) • Query Rewriting • M: DbResearcher(x), Office(x,DBLab)=DbLabMember(x) QP3 (x) DbLabMember(x) • [Halevy, Ives, Suciu, Tatarinov, ICDE 2003] Crossing the Structure Chasm
Mapping Composition • Problem • Given a mapping between PMIT and PUCB, PUCB and PUW • Compute an equivalent mapping between PMIT and PUW • Why bother? • Tolerate network failure – peers might not be forever • Query and network optimization – caching paths • Theoretical results • Composition can be infinite even for very simple cases !!! • Can be finitely encoded if query language is restricted Crossing the Structure Chasm
Current and the Future • Current status • Demo scenario using XML • Looking at real domains (Bio dbs, NASA dbs) • [Halevy, Ives, Mork, Tatarinov, WWW 2003] • Future Work • More efficient reformulation algorithm • Semantic network analysis – eliminate redundant mappings and inconsistent mappings • Query caching to speed up query evaluation Crossing the Structure Chasm
Outline • The Structure Chasm • Three research directions • Mangrove: making authoring easier by instant gratification • Piazza: making querying and sharing easier though pairwise mediation between autonomous peers • Schema matching solutions • Summary Crossing the Structure Chasm
Semantic Interoperation Tools • Autonomous structured data creation proliferation of schemas • Support tools • Schema Matching: create the mappings in Piazza • Schema Creation: auto-complete a partial schema • … Crossing the Structure Chasm
Corpus of Structured Data • Document corpora in the UWORLD • Key to many Information Retrieval techniques, e.g. word statistics for keyword queries • Analog in the SWORLD • Corpus of Structured Data: collection of schemas, mappings, data instances, any other type of meta-data • Statistics can be computed over the schemas • Tools can leverage the computed statistics • Schema Matching tool that leverages a corpus of structured data Crossing the Structure Chasm
Schema Matching • First step towards generating semantic mappings • Identifying the similar elements in different schemas Books Title ISBN Price DiscountPrice Edition Authors ISBN FirstName LastName BookCategories ISBN Category BooksAndMusic Title Author Publisher ItemID ItemType SuggestedPrice Categories Keywords CDCategories ASIN Category CDs Title ASIN Price DiscountPrice Studio Artists ASIN ArtistName GroupName Crossing the Structure Chasm
Learning tools:extract knowledge from schemas and mappings. Learned models:for each unique element in any schema. Schemas and mappings: added with each mapping task Mapping Knowledge Base • Mapping tasks can be repetitive • Extract knowledge from schemas and validated mappings • Reuse the knowledge for new matching tasks Data Instances Learner Structure Learner Name Learner Data Type Learner Description Learner Meta Learner C1 CN NL:… DIL:… DTL:… DL:… SL:… ML:… NL:… DIL:… DTL:… DL:… SL:… ML:… Crossing the Structure Chasm
Name Learner BooksAndMusic/Publisher CDs/Studio Positive examples Inventory Database A Meta Learner BooksAndMusic/Title,… Books/Title,… CDs/Title, CDs/ASIN,… Artists/Name,… … Negative examples Inventory Database B Structure Learner Extracting Schema Knowledge • Each learning tool is trained to identify each element • Training data extracted from schemas and mappings CBooksAndMusic/Publisher • Name : Pathname typically contains the word “book” and “pub” • Data Type : Usually a string or a varchar • Structure : Co-occurs with “Edition” and “Year of Publication” • Meta Learner: <NL:0.45, DTL: 0.3, SL: 0.35> Crossing the Structure Chasm
Matching Schemas • Elements are similar is they cannot be distinguished using the learned models • Estimate similarity of each element to all elements in the MKB Interpretation I(si) = element si Schema S Pik= Probability (si ~ ck ) • Estimate similarity of si schema S, tj schema T I(si) Sim(si,tj) I(tj) Crossing the Structure Chasm
Current and the Future • Initial results look promising. • Building on previous machine learning systems built by us • LSD [Doan, Domingoes, Halevy, SIGMOD 2001] • Glue [Doan, Madhavan, Domingoes, Halevy, WWW 2002] • Future work • Evolution performance of the MKB • Combination with other schema matching solutions • Other corpus based applications Crossing the Structure Chasm
Summary • The Structure Chasm • There are huge amounts of data out there - the more structured it is the better • Three research directions • Mangrove: making authoring easier by instant gratification • Piazza: making querying and sharing easier though pair wise mediation between autonomous peers • Schema Interoperation Tools like the MKB: making it easier to make sense of innumerable schemas Crossing the Structure Chasm
The Crew • Mangrove • Oren Etzioni, Steve Gribble, Alon Halevy, Hank Levy, Luke McDowell, William Pentney, Deepak Verma, Stani Vlasseva • Piazza • Luna Dong, Alon Halevy, Peter Mork, Dan Suciu, Igor Tatarinov • MKB • Phil Bernstein, Kuang Chen, Eric Chu, Alon Halevy, Jayant Madhavan, Pradeep Shenoy Crossing the Structure Chasm