Download

1 / 16
160 likes | 330 Views
Maschinelles Lernen. Self Organizing Maps (SOMs). map(p). (map). p. Input Space. Self Organizing Maps. Teuvo Kohonen (~1982): Self Organizing Map (SOMs), Kohonen Feature Maps. Topologie erhaltende Projektion hochdimensionaler Datenmengen auf niedrig dimensionale „Karten“

E N D
Maschinelles Lernen Self Organizing Maps (SOMs)
map(p) (map) p Input Space Self Organizing Maps Teuvo Kohonen (~1982): Self Organizing Map (SOMs), Kohonen Feature Maps • Topologie erhaltende Projektion hochdimensionaler Datenmengen auf niedrig dimensionale „Karten“ • Erkennung von Strukturen, Klassen, Clustern in hochdimensionalen Datenräumen Teuvo Kohonen
Analogie: Der sensorische/motorische Homunculus Topologieerhaltende, jedoch nicht abstandstreue Abbildung: Benachbarte Punkte des Körpers werden meist auf benachbarte Punkte der Hirnrinde abgebildet Blickrichtung
Analogie: Primäre Sehrinde 3-dimen-sionales Gesichts-feld 2-dimen-sionale primäre Sehrinde f A B
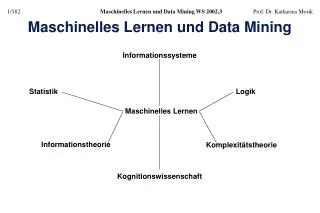
Verwandte Verfahren Es gibt neben SOMs etliche Verfahren, die mit dem Namen „Kohonen Feature Map“ bezeichnet werden, z.B. die Vektorquantisierung Vektorquantisierung ist ein unüberwachtes Lernverfahren, das mit dem k-means Verfahren verwandt ist. Training:Sei X |Rn eine Menge von Trainingsdaten und V |Rn eine Menge von Referenzvektoren, |V| ≪ |X|. In jedem Lernschritt t wird ein Trainingspunkt xt∊X ausgewählt und der nächstliegende Referenzvektor v∊V (sog. Codebook-Vektor) ermittelt. Der Referenzvektor wird dann in Richtung xt verschoben. Wie weit genau, wird durch die Lernrate bestimmt. Die Lernregel lautet dabei ist η(t) ∊[0,1] die Lernrate, welche mit der Zeit t gegen Null geht. „Clustering“:Zu einem neuen Datenpunkt x |Rn bestimme den Codebook-Vektor v∊V.
SOMs, Definition Sei X |Rn eine Menge von Trainingsdaten und K eine Karte. Eine Karte ist eine Menge von Punkten V = {vj | j∊J} |Rn , zusammen mit einer Nachbarschaftsfunktion N: J x J→[0,1] Üblicherweise ist N(j,j)=1, und N(j,k) ist um so größer, je „näher“ v an w liegt. Die Nachbarschaftsfunktion bestimmt die Topologie der Karte, legt insbesondere (implizit) deren Dimension fest. Gebräuchliche Kartentopologien: N(k,j) = 0.25 = N(k,j) = 0.5 N(j,j) = 1 N(k,j) = 0 1-dim., Linie 1-dim., Kreis 2-dim., Ebene 2-dim., Torus
SOMs, Definition Training (ähnlich wie bei der Vektorquantisierung): In jedem Lernschritt t wird ein Trainingspunkt xt∊X ausgewählt und der nächstliegende Referenzvektor vj∊V (sog. Codebook-Vektor, best matching unit (BMU)) ermittelt. Die Karte wird verändert nach der Lernregel dabei ist η(t) ∊[0,1] die Lernrate, welche mit der Zeit t gegen Null geht. Bsp.: Veränderung der Gewichtsvektoren durch Training BMU alt und neu übereinander gelegt neu alt „Clustering“:Zu einem neuen Datenpunkt x |Rn bestimme die best matching unit v∊V.
Beispiele Training der Karte auf einem uniformen Rechteck.
Eigenschaften, Anwendungsgebiete von SOMs Für sehr kleine Karten ( |V| <10 ) verhalten sich die Referenzpunkte der SOMs ähnlich wie die Zentren des k-means Algorithmus. Für große Karten ergeben SOMs eine (niedrigdimensionale) Abbildung der Daten. Demnach sind die natürlichen Anwendungsgebiete von SOMs • Dimensionsreduktion • Datenvisualisierung Jedoch NICHT: • Clustering (k-means ist in aller Regelvorzuziehen) Bsp.: SOM Clustering von Genen (ca. 900), bzgl. ihrer Expression in verschiedenen Samples (n = 7). Aus der Stanford Microarray Database (SMD), Data Analysis and Clustering Help
Details beim Lernen von SOMs Initialisierung der Karte: • Zufallswerte für alle Vektoren • Feste Werte für alle Vektoren • PCA (Hauptkomponentenanalyse) • Repräsentative Trainingsvektoren als Initialisierungshilfe Wahl der Lernrate η(t): • Zu Beginn hoher Wert von η(t): schnelle, grobe „Entfaltung“ • Gegen Ende kleiner Wert von η(t): Feinjustierung der Karte Beispiele für die Lernrate linear: , ist Startwert, Endzeitpunkt exponentiell:
Details beim Lernen von SOMs Zeitabhängige Wahl der Nachbarschaftsfunktion Zu Beginn großer Nachbarschaftsradius, später kleiner (analog zur zeitabhängigen Wahl Lernrate soll erst die grobe Topologie gelernt werden) Gitter „frühe“ Nachbarschaftsfkt. „späte“ Nachbarschaftsfkt. Bsp.: wobei d(k,j) der Gitterabstand im obigen Graphen ist. Beachte: Die Nachbarschaftsfunktion N(k,j) hängt NICHT von den Referenzvektoren vk,vj ab, sie gibt die Topologie er Karte fest vor!
Nachteile von SOMs • SOMs maximieren keine Zielfunktion (d.h. es ist schwierig zu sagen, was überhaupt gelernt wird) • Es ist deshalb nicht klar, nach welchen Kriterien das Lernen abgebrochen werden soll, und wann ein solches Netz konvergiert • Die Topologie des Datenraumes wird meist, aber nicht notwendig richtig abgebildet • Die Wahl der Nachbarschaftsfunktion beeinflusst hochgradig das Lernergebnis (“Dimension” der Datenmenge muss evtl. vorher geschätzt werden) • Es wird keine Wahrscheinlichkeitsdichte gelernt • Ein Vergleich verschiedener Modelle (SOMs untereinander, SOMs mit Dichte-Lernverfahren) ist schwierig • Insgesamt: Es handelt sich lediglich um eine Heuristik, eine theoretische Motivation bleibt aus