Download

1 / 22
220 likes | 226 Views
Evolution of the Configuration Database Design. Andrei Salnikov, SLAC For BaBar Computing Group ACAT05 – DESY, Zeuthen. Talk overview. BaBar configuration database Migration of BaBar databases New configuration database API Choice of technologies Implementation dynamic loading

E N D
Evolution of the Configuration Database Design Andrei Salnikov, SLAC For BaBar Computing GroupACAT05 – DESY, Zeuthen
Talk overview • BaBar configuration database • Migration of BaBar databases • New configuration database API • Choice of technologies • Implementation dynamic loading • Lessons learned from migration ACAT 2005
BaBar on-line databases • Conditions database • Calibrations, geometry, alignment, etc. • Data accessed with the event time • Ambient database (simplified conditions) • Time history of the data-taking conditions (voltages, currents, temperatures, etc.) • Part of the on-line detector control • Configuration database • Details follow • Prompt Reconstruction databases • Support for multi-node calibrations • Electronic Logbook • Etc. ACAT 2005
Configuration database • Important part of the on-line system • Configuration database keeps configuration data - detector and software settings for data taking • Support configuration of the on-line hardware and software in preparation for data taking • For more details see CHEP’03 talk • Worked reasonably well since the beginning of Run 1 in 1999 ACAT 2005
BaBar database migration • BaBar was using Objectivity/DB ODBMS for many of its databases • About two years ago started migration from Objectivity to ROOT for event store, which was a success and improvement • No reason to keep pricey Objectivity only because of “secondary” databases • Migration effort started in 2004 for conditions, configuration, prompt reconstruction, and ambient databases ACAT 2005
Scope of the migration • Configuration database currently holds about 60MB (uncompressed) of configuration data • About 30 persistent classes for representation of the configuration data • Rather compact and simple compared to other BaBar databases (e.g. conditions database is 40GB and 400 classes) • Due to its size and simplicity configuration database is a perfect candidate for a pilot project within migration effort ACAT 2005
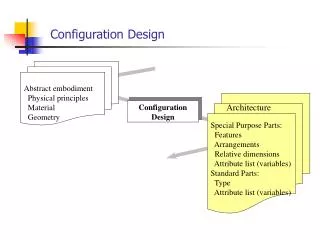
Configuration database API • Main problem of the old database – API exposed too much of the implementation technology: • Persistent object, handles, class names, etc. • API has to change but we don’t want to make the same mistakes again (new mistakes are more interesting) • Pure transient-level abstract API independent on any specific implementation technology • Much easier to re-implement in different technology if we don’t like one particular technology • Can support more than one technology if needed [vital] • Client code independent of any persistency technology ACAT 2005
Prototyping New API • To test the details of new API and one specific implementation, a prototype implementation was built • Great prototyping language used – Python • MySQL used for data storage • Prototype is not “exact” because languages are very different: Python – dynamic, C++ – static • But helped a lot with quick testing of different ideas and optimizing SQL tables ACAT 2005
New Database API • Defining new API is easy – after five years of experience it can’t be done wrong • Expressing this API in C++ is not so easy • one particular problem – how to pass non-polymorphic types through abstract interface • in C++ interfaces and templates do not mix • solution is to use RTTI at transient level • smart AnyPtr (void* with enough RTTI) • mechanism is hidden from client code, clients only see type-safe methods ACAT 2005
API migration – clients • All clients should be changed to use new API • All client code should be made free of the old implementation details • Most time-consuming task in the whole migration • Re-examining dependencies, re-packaging code, re-thinking design at global level • Process is hard, sometimes conflicting with other development, but the result is beneficial for everybody – cleaner code and fewer dependencies ACAT 2005
Bridge Implementation • Having an abstract API we need to build specific implementation(s) • Start with obvious – we still have data in Objectivity. Build bridge implementation on top of old database • proof of a working API • being used until migration is complete • but the goal is to have different technology(-ies) ACAT 2005
Choosing Technology • Time to choose implementation technologies, real alternatives to Objectivity • Many considerations – data access and distribution, reliability, data modeling capabilities, etc. ACAT 2005
Choosing technology • Two classes of clients with different requirements: • production site needs reliable, fault-tolerant, concurrent read-write access to the data • remote sites need zero-management, easy-to-use, fast, scalable read-only access to the data • It should be possible to use different implementation technologies at production and remote sites ACAT 2005
Read-only implementation • ROOT is an obvious decision for storing read-only data: • Data definition using C++ constructs allows easy migration of Objectivity schema • No servers and no management needed for small installations • For large installations xrootd server could be used for load-balancing • BaBar data distribution knows already about ROOT ACAT 2005
Read-only implementation • Migration was straightforward • ROOT-persistent classes are (almost) exact copy of Objectivity DDLs • Data size is small, everything fits in one file • Metadata and data objects are stored in TTrees, à la relational tables in SQL database • Some complications due to lack of proper indexing support in ROOT TTrees, needed some additional structures ACAT 2005
Read-write implementation • Need something more robust for this – real database • Practically only option is relational database – either commercial like Oracle, or free as MySQL • Need to augment it with the object-relational mapping, not quite trivial despite many databases call themselves object-relational • But we could reuse data definitions from ROOT read-only implementation • Not so critical for configuration database, but will be essential for conditions ACAT 2005
MySQL implementation • Initial implementation in MySQL, but can switch to Oracle later if MySQL fails • Configuration objects are self-contained, store them as BLOBs in the relational tables • Need to serialize object data for storage • convert to ROOT object • call Streamer() to stream data into buffer • compress buffer, store as BLOB • De-serialization works in opposite direction • Reuse of the persistent classes from ROOT read-only implementation! ACAT 2005
Building applications • Now we have three implementations: Bridge (temporary), ROOT, and MySQL • Decision on which one to use should be delayed until run time, so that the same application could run everywhere • Should link all implementations into all applications? • Not good, don’t want to install MySQL if need only ROOT read-only • Load implementations dynamically at run time ACAT 2005
Dynamic loading • In principle it should be possible to split things into static/dynamic • In practice it is very complex and needs extreme care • In BaBar we ended up with the dynamic loading of libmysqlclient.so only • ROOT implementation is linked into application • part of MySQL implementation too • but no link dependency on MySQL ACAT 2005
Current Status • New API and all three implementations are now in production • Bridge implementation is what we are currently using in production • Data in two other implementations are constantly updated from production data • Preparing data distribution for ROOT configuration data • Planning to switch production to use MySQL implementation ACAT 2005
Lessons learned • Always make abstract APIs to avoid problems in the future (this may be hard and need few iterations) • Client code should be free from any specific database implementation details • Early prototyping could answer a lot of questions, but five years of experience count too • Use different implementations for clients with different requirements • Implementation would benefit from features currently missing in C++: reflection, introspection (or from completely new language) ACAT 2005
Conclusions • We have redesigned and reimplemented BaBar configuration database • Different alternative implementations exist for clients with different requirements • No specific performance figures, but it should be better than original Objectivity performance • Good experience which will be used in migration of other BaBar databases ACAT 2005