Download

1 / 15
150 likes | 247 Views
Analisi monovariata. Lavoro a cura di Sovarino Elisa A.A. 2002-2003.

E N D
Analisi monovariata Lavoro a cura di Sovarino Elisa A.A. 2002-2003
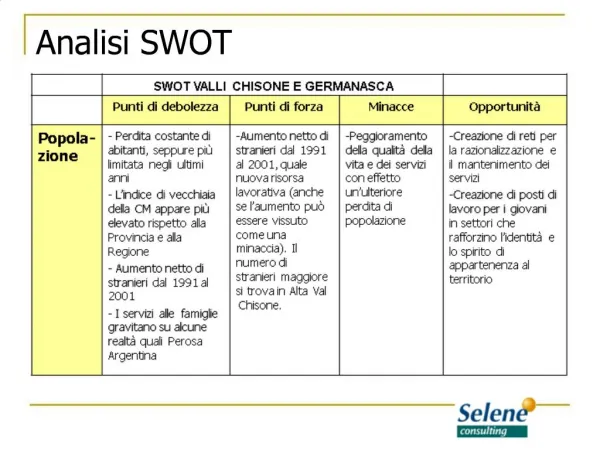
DEFINIZIONE: analisi monovariata studia le distribuzioni di frequenza della variabile oggetto di studio. Fornisce una descrizione completa della variabile, ovvero di come essa è distribuita fra i casi rilevati nel campione. Lo scopo è quello di studiare le variabili prese singolarmente senza metterle in relazione tra loro. ( vedi Corbetta pg 497 ) • Costituisce il punto di partenza per l’analisi bivariata e/o multivariata ( ) studio delle relazioni fra due variabili ( studio delle relazioni intercorrenti tra più di due variabili )
La matrice dei dati Per studiare le variabili singolarmente, si fa uso dei dati ricavati dall’incrocio tra riga e colonna ovvero tra casi e variabili, contenuti nella matrice dei dati. Strumento euristico utile per organizzare il materiale empirico grezzo al fine di analizzarlo con gli strumenti della analisi statistica. A seconda del tipo di variabile variano le procedure di tipo statistico, utilizzate dal ricercatore
Le variabili Le Proprietà si dividono indiscrete( se assumono stati discreti finiti, non frazionabili)e continue( se assumono infiniti stati intermedi in un dato intervallo fra due stati qualsiasi ) Le variabili possono essere classificate in base alle loro caratteristiche logico-matematiche in: • Categoriali • (scala nominale ) 2) Ordinali ( graduatorie ) 3) Cardinali ( Scala ad intervalli/di rapporti ) Ovvero quando la proprietà da registrare assume stati discreti non ordinabili. Le uniche relazioni che si possono stabilire tra le modalità di una variabile nominale sono uguaglianza-diversità Ovvero quando la proprietà assume stati discreti e ordinabili. Fra le modalità di una variabile ordinale è possibile istaurare relazioni di uguaglianza/ordine. Ovvero quando le proprietà sono ottenute mediante un’operazione di misurazione o conteggio. I valori delle variabili fruiscono di un pieno significato numerico. Si effettuano le quattro operazione aritmentiche 4) Variabili quasi cardinali Sottoinsieme delle variabili cardinali; le proprietà non possono essere ottenute mediante mere operazioni di conteggio, ma tramite il ricorso a tecniche di scaling. ( cfr. Corbetta 106-112 ) Le proprietà dei tre tipi di variabili sono cumulative, queste possono essere viste come tre livelli ordinabili gerarchicamente. Inoltre varia tra loro anche il livello di “informatività”, da cui consegue che le tecniche d’analisi delle variabili a livello inferiore siano applicabili anche alle variabili poste su di un livello superiore.
Analisi delle distribuzioni di frequenza Riguardano il modo in cui le modalità della variabile si trovano nel campione Rappresentazioni nelle quali ad ogni valore della variabile, viene associata la frequenza con la quale essa si presenta nei dati analizzati. ( vedi Corbetta pg. 487, 497) TABELLARE: Il ricercatore dovendosi sempre attenere ad un criterio di massima parsimoniosità, presenterà in tabella solo i dati essenziali ( frequenze percentuali ) accompagnate dall’indicazione della base ( N ) del calcolo delle percentuali. GRAFICA: Il ricercatore si serve solitamente di rappresentazioni grafiche per la loro grande efficacia comunicativa, nei confronti di un pubblico che potrebbe avere difficoltà ad interpretare dei numeri.
Rappresentazioni grafiche della distribuzione di frequenza Diagramma a barre:Modo più semplice di rappresentazione grafica. Il ricercatore (supponendo di voler costruire un diagramma a barre a colonne), riporterà su un piano cartesiano i valori delle variabili (asse Y) e le relative frequenze ( asse X). Si noti che solo l’asse dove sono collocate le frequenze presenta una misura continua, e ordinata matematicamente; le modalità invece vengono disposte sull’altro asse, seguendo l’ordine arbitrario del ricercatore. Diagramma di composizione: la distribuzione di frequenza viene rappresentata suddividendo l’area di una figura geometrica in parti proporzionali alle varie frequenze.Fanno parte di questa “ famiglia” il diagramma a torta, e il diagramma a barre suddivise ( figura viene divisa in barre di altezza proporzionale alle frequenze delle variabili. ). Istogramma: quando la variabile oggetto di studio è cardinale. La distribuzione di frequenza viene rappresentata su un piano cartesiano, collocando su un asse la variabile ( continua ) suddivisa in classi, e sull’altro le frequenze, innalzando dei rettangoli di area ad esse proporzionate. Poligono di frequenza: quando la variabile oggetto di studio è cardinale. Lo si ottiene congiungendo i punti medi dei lati superiori dei rettangoli di un istogramma con una linea, per avere infine una “ spezzata ”che si approssimerà sempre più ad una curva continua, man mano che le classi di una variabile cardinale si fanno sempre più numerose. ( cfr. Corbetta 515-520 )
Analisi delle distribuzioni di frequenza 2 Il ricercatore, tramite le distribuzioni di frequenza, dà una rappresentazione sintetica di quanto è codificato nella colonna n°…, della matrice. • Individua modalità di ciascuna variabile es: SESSO M/F 2)Conta quante volte la modalità si presenta nella distribuzione tabellare della matrice es: M = 16 ; F = 24 Frequenze assolute = viene riportato accanto ad ogni valore della variabile, il numero dei casi che presentano quel valore, senza altro intervento ( semplice conteggio ) Il limite delle frequenze assolute è la loro fortissima dipendenza dal contesto in cui sono state rilevate. Impossibile fare un confronto tra distribuzioni. Frequenze relative = tramite riferimento ad un totale comune, viene riportato accanto un valore frutto di una proporzione o percentualizzazione. numero casi della “classe” diviso il n° casi totale. = Lo scopo è quello di svincolarsi dal n° di persone appartenenti al campione, così da poter estendere la frequenza relativa ad ogni tipo di situazione e confrontare diverse distribuzioni. (cfr. Corbetta pg.487 )
La scrematura dei dati: La prima possibile utilizzazione della distribuzione di frequenza. Ricognizione sui valori per identificare gli eventuali errori a partire da incongruenze logiche( crf. Corbetta pg. 494-497) controlli di plausibilitàcontrolli di congruenza Controllare che tutti i valori delle variabili siano plausibili, appartengano cioè al ventaglio dei valori previsti dal codice Confrontare le distribuzioni di due variabili per far emergere eventuali incongruenze ••• valori mancantiponderazione Procedura tramite cui si può ricondurre la distribuzione di una data variabile nel campione a quella della popolazione. Con una proporzione viene calcolato il peso dell’ unità campionaria, dato dal rapporto fra frequenza nella popolazione e frequenza nel campione. Si tratta di un operazione da compiersi nella fase precedente l’analisi dei dati; cercando di non alterare in modo eccessivo i dati originari. ( cfr. Corbetta pg. 496, 352-356 ) Ad un certo caso, in una certa variabile viene assegnato “valore mancante” se quel caso è privo di informazione su quella variabile
Misure di tendenza centrale e variabilità Di tutte le caratteristiche di una distribuzione di frequenza due sono le più importanti: misure di tendenza centrale misure di dispersione/variabilità Ci segnalano quella che è la modalità centrale di una distribuzione di frequenza Ci segnalano come si collocano le altre modalità attorno questo centro Diciamo che una variabile nominale ha una distribuzione massimamente omogenea quando tutti i casi si presentano con la stessa modalità. Viceversa è massimamente eterogenea se i casi sono equidistribuiti tra le modalità. (cfr. Corbetta pg. 504) Modalità di una variabile che si presenta nella distribuzione con maggiore frequenza Modalità del caso che occupa il posto di mezzo nella distribuzione ordinata dei casi secondo quella variabile Se dividiamo i casi di una distribuzione in quattro punti di eguale numerosità, i valori che segnano i confini sono detti quartili, e la differenza fra terzo e primo è la c.d. diff. interquartile E’ data dalla somma dei valori assunti dalla variabile su tutti i casi divisa per il numero dei casi. Tali indici sfruttano tutte le informazioni raccolte su variabili cardinali
Annotazioni Moda se la distribuzione presenta due valori elevati che si distaccano dagli altri, la distribuzione prenderà il nome di bimodale. Mediana per poter calcolare la mediana bisogna anzitutto calcolare le percentuali cumulate (v.6) Es: distribuzione cumulata di frequenza: nella quale in corrispondenza di ogni valore della variabile, viene riportata non la sua frequenza ma la somma delle frequenze corrispondenti a quel valore e a tutti quelli inferiori. mediana Media è uguale alla sommatoria di i che va da 1 ad n per Xi fratto N; si può calcolare solo se la variabile è cardinale; tuttavia vi sono alcune situazioni nelle quali anche se la variabile è cardinale, si preferisce ricorrere alla mediana piuttosto che alla media ( v. Corbetta pg. 503 ) n * Xi i = 1 X = Con X indico una generica variabile, con Xi il valore che assume sull’unità iesima, con N il numero totale dei casi N
Misure di dispersione o variabilità n X – Xi S. S. M. Scostamento semplice medio i = 1 N Modo molto semplice di calcolare la variabilità di una variabile cardinale potrebbe essere costituito dalla media aritmetica degli scarti di ogni singolo valore dalla media. Infatti se calcolo la media delle differenze ( ovvero quanto mi allontano dalla media per ciascuna risposta otterrò un indicatore più o meno fedele di quanto accade nelle popolazione Il valore assoluto è necessario per non considerare il segno e per non incorrere nel 1° teorema fondamentale delle medie ( la media degli scarti dei valori dalla media è sempre uguale a ZERO.) MA per annullare il segno si può in alternativa elevare al quadrato, otteniamo così: n 2 X – Xi La varianza i = 1 S2= N La deviazione standard : infine estraendo la radice si ottiene il c.d scarto quadratico medio ovvero La deviazione standard risente della grandezza della media della variabile; per tanto se si vogliono confrontare fra loro le variabilità di distribuzioni aventi medie fortemente diverse, conviene utilizzare un indice di variabilità che ne tenga conto, ovvero il coefficiente di variazione. ( cfr Corbetta pg.510) n 2 X – Xi S = i = 1 N S Cv = X
Quando la variabile è cardinale e consiste in quantità possedute dalle unità d’analisi si può calcolare la concentrazione di questa variabile nelle unità studiate. equidistribuzione vs ammontare complessivo di A è attribuito ad una sola unità Se il suo ammontare complessivo A è distribuito in parti uguali fra N unità, cioè se ogni unità possiede 1/N di A La concentrazione è un modo particolare di guardare alla variabilità: tanto più una variabile è concentrata, tanto più elevata è la variabilità di quella variabile. ( si possono calcolare diversi indici di concentrazione ) Gini: rapporto di concentrazione Si calcolano le proporzioni cumulate dei soggetti e della variabile in esame ( reddito ) Se il “reddito“ fosse equidistribuito queste proporzioni sarebbero uguali, e se riportate su un piano cartesiano sarebbero allineate sulla bisettrice=segmento di equidistribuzione Se non c’è equidistribuzione si darà luogo ad una spezzettata=curva di Lorenz. L’area compresa fra la spezzettata e il segmento di equidistribuzione=area di concentrazione ( cfr. Corbetta pg. 512 )
Notevoli sono i vantaggi nel condurre delle analisi sulle righe di una matrice dati, ovvero a partire dai casi: È possibile infatti confrontare due righe della stessa matrice dei dati e calcolare l’indice di somiglianza fra i profili dei due casi tramite il calcolo matematico della distanza Indice di distanza e dissimilarità Diverse e utili applicazioni Es: i casi possono essere rrappresentati da aggregati territotiali, le variabili invece dai risultati territoriali, si possono calcolare le distanze fra le regioni prese a due a due, oppure le distanze di ogni singola regione dalla media nazionale. ( cfr. Corbetta pg. 526) Dij = 2 2 2 + + Xi1 - Xj1 Xi2 - Xj2 Xin - Xjn NB. È possibile calcolare le distanze fra i casi solo se le variabili sono cardinali ( la formula implica operazioni aritmetiche fra i valori delle variabili. ) Se le variabili sono nominali si può procedere tuttavia in maniera simile, ovvero trasformando le variabili nominali in tante variabili dicotomiche 0/1.
Classificare Per classificazione intendiamo il processo secondo il quale i casi studiati vengono raggruppati in sottoinsiemi ( “ classi ” ) sulla base delle loro similarità. Tramite una specifica procedura ( calcolo degli indici di similarità/dissimilarità fra due distribuzioni di frequenza ) otteniamo un unico numero, in cui sono sintetizzate le differenze esistenti fra due distribuzioni di frequenza della stessa variabile. Le classi presentano 3 fondamentali requisiti. Devono essere: Esaustive tutti i casi devono trovare collocazione in una classe, nessuno può esserne escluso. Mutualmente esclusiveun caso può appartenere ad una sola classe. Garanti dell’ unicità del fundamentum divisionisil criterio rispetto al quale facciamo le distinzioni ovvero rispetto al quale costruiamo le classi deve essere unico.
Classificazione unidimensionaleaggregazione delle modalità in classi Più semplice dei processi classificatori; i casi vengono classificati per la loro somiglianza relativamente ad una sola variabile. In questi termini il problema della classificazione si riduce a quello delle modalità delle variabili. Problema già risolto nella fase precedente la rilevazione dei dati e nella fase di codifica, MA per molte variabili nella fase di analisi dei dati deve essere perfezionata mediante l’operazione di aggregazione di alcune modalità. variabile nominale aggregazione fra modalità è necessaria per l’analisi bivariata,la quale necessitaper ogni modalità un numero sufficiente di casi e dunque che le frequenze delle varie modalità siano fra loro wquilibrate Variabile cardinale aggregazione delle modalità consiste in un raggruppamento in classi di maggiore ampiezza ed avviene secondo tre criteri: 1) raggruppamento dei valori della variabile in intervalli di uguale ampiezza 2)raggruppamento dei valori assume a riferimento il loro significato 3) raggruppamento dei valori assume a riferimento la sua distibuzione di frequenza. Classificazione multidimensionaletipologie e tassonomie I casi possono essere classificati sulla base di più variabili, cosicchè possano essere classificati mettendo in relazione (es) reddito e occupazione Tassonomia: è una classificazione nella quale le variabili che la costituiscono sono considerate in successione gerarchica per variabili di generalità decrescente. Sono molto comuni nelle scienze naturali,e poco in quelle sociali. Tipologia: è una classificazione nella quale le variabili che la compongono sono considerate simultaneamente / congiuntamente. Le classi di una tipologie sono dette tipi. Lo scopo: interpretativo ed esplicativo, finalità euristiche. La tipologia deve essere feconda, deve fornire qualcosa di aggiuntivo rispetto a ciò che ci dice la combinazione delle singole variabili. Esempio di tipologia è quella proposta da BECKER sull’atteggiamento dei genitori nei confronti dei figli. ( cfr. Corbetta pg. 529-534 ) Tipi di classificazione