Download

1 / 73
730 likes | 940 Views
05 MUESTREO APLICADO EN LAS ENCUESTAS. Mag. Renán Quispe Llanos Enero, 2005. VARIABLE ALEATORIA DISCRETA. Una variable Aleatoria Discreta tiene la forma: X = {. X1 con probabilidad p1 X2 con probabilidad p2 X2 con probabilidad p2 . . . Xn con probabilidad pn.

E N D
05 MUESTREO APLICADO EN LAS ENCUESTAS Mag. Renán Quispe Llanos Enero, 2005
VARIABLE ALEATORIA DISCRETA Una variable Aleatoria Discreta tiene la forma: X ={ X1 con probabilidad p1 X2 con probabilidad p2 X2 con probabilidad p2 . . . Xn con probabilidad pn Una Función de Probabilidad Discreta P (X) Se define como: P (X=x) = a alguna expresión que contiene a x y que produce la probabilidad de observar a x, =P (x)
VARIABLE ALEATORIA CONTINUA Una variable aleatoria Continua está dada sobre un rango continuo de valores, donde una Función de Probabilidad Continua P (X), se define como: 1. P (x) es un valor entre 0 y 1 para todo rango de x de la forma a ≤ x ≤ b. 2.
FUNCION DE DENSIDAD Definición: Es una función no negativa de integral 1. Se puede pensar como la generalización del histograma con frecuencias relativas para variables continuas. b a
La curva normal adopta un número infinito deformas, determinadas por sus parámetros y expresada por la función de densidad:f(x) = 2 x e (media) y(desviación típica) son parámetros de la distribución donde: e = 2.718 (base de Ln) x= valores observados de la variable en estudio
Características de la distribución Normal • Tiene forma de campana, es asintótica al eje de las abscisas (para x = ) • Simétrica con respecto a la media () donde coinciden la mediana (Mn) y la moda (Mo ) • Los puntos de inflexión tienen como abscisas los valores + + - ,Mo, Mn
¿Cómo calcular probabilidades asociadas a una curva normal específica? Dado que tanto como pueden asumir infinitos valores lo que hace impracticable tabular las probabilidades para todas las posibles distribuciones normales, se utiliza la distribución normal reducida o tipificada ?? x - Se define una variablez = Es una traslación , y un cambio de escala de la variable original
La nueva variable z se distribuye como una NORMAL con media = 0 y desviación típica = 1 Una regla empírica indica que en cualquier distribución normal las probabilidades delimitadas entre : 1 68 % 2 95 % 3 99 % 99% 68% 95% z 99% -3 -2 -1 0 1 2 3
Pero para valores intermedios esta regla es insuficiente. Las probabilidades de la variable tipificada (z) están tabuladas para los diferentes valores de la variable. Entonces una vez transformada la variable a valores de z se busca en la tabla el área correspondiente
Hay varios tipos de tablas de la distribución normal La que se explica aquí representa las áreas para los diferentes valores de z desde 0 hasta + Los valores negativos de z NO están tabulados, ya que la distribución es simétrica + 0
*Margen izquierdo : Los enteros de z y su primer decimal la tabla consta de: * Margen superior: segundo decimal * Cuerpo de la tabla: áreas correspondientes, acumuladas, desde 0 hasta 3.99 0 1 2 3 4 5 6 7 8 9 0.0 0.1 0.2 0.3 0.4 0.5 .0000 .0040 .0080 .0120 .0160 .0199 .0239 .0279 .0319 .0359 .0398 .0438 .0478 .0517 .0557 .0596 .0363 .0675 .0675 .0754 .0793 .0832 .0871 .0910 .0948 .0987 .1026 .... ...... ...... .1179 ..... ...... ...... ...... .1554 .... ..... .... .1915 ....
EJEMPLOS: 1.-¿Cuál es la probabilidad de que un valor de z esté entre 0 y -2.03? 2.-¿Cuál es la probabilidad de que un valor de z esté entre -2.03 y +2.03? 4. Hallar P ( -0.34 < z < ) 3. Hallar P( z >1.25 ) 5. Hallar P ( 0.34 < z < 2.30 )
ejemplo 1 ¿Cuál es la probabilidad de que un valor de z esté entre 0 y -2.03? ? Cómo la curva es simétrica P (-2.03 < z < 0) = P (0 < z < 2.03) z -3 -2 -1 0 1 2 3
ejemplo 1 ¿Cuál es la probabilidad de que un valor de z esté entre 0 y -2.03? Se busca en la tabla el área correspondiente a z = 2.03 0.47882 47. 88% z -3 -2 -1 0 1 2 3
ejemplo 2 ¿Cuál es la probabilidad de que un valor de z esté entre -2.03 y 2.03 ? En el ejemplo 1, vimos que la probabilidad de que z estuviera entre 0 y 2.03= 0.47882 La misma área hay entre 0 y -2.03 , por lo tanto P ( -2.03< z< 2.03) = 0.95764 ? 47.88% 47.88% 95.76% z -3 -2 -1 0 1 2 3
ejemplo 3 ¿Cuál es la probabilidad de que un valor de z sea mayor a 1.25 ? 1.- La probabilidad de 0 < z < + = 0.500 2.- La probabilidad de 0 < z < 1.25 = 0.39435 3.- La probabilidad de z > 1.25 = 0.500 - 0.39435= 0.10565 50% 39.44% 10.56% ? z -3 -2 -1 0 1 2 3
ejemplo 4 Hallar P( -0.34 < z < ) 63.31% P(0 < z <0.34) = 0.13307 = P(-0.34 < z < 0) P (0 < z < ) = 0.50000 P( -0.34 < z < ) = 0.13307 + 0.50000 = 0.63307 13.31% 50% z -3 -2 -1 0 1 2 3
ejemplo 5 Hallar P( 0.34 < z < 2.30) P(0< z <0.34) = 0.13307 P( 0 < z < 2.30) = 0.4893 P (0.34 < z < 2.30) = 0.48930 - 0.13307 = 0.35623 35.62% z -3 -2 -1 0 1 2 3
EJEMPLO Sea una variable distribuida normalmente con media = 4 y desviación típica = 1.5. ¿Cuál es la probabilidad de encontrar un valor x 6 (P(x 6 ))?
= 4 = 1.5 Hallar P ( x > 6 ) 1.- transformar x en un valor de z z = (6 - 4)/1.5= 1.33 2.- Hallar P ( 0 < z < 1.33) = 3.- 0.5000 - 0.40824 = 0.5 0.40824 ? 0.09176 x 6 -0.5 1 2.5 4 5.5 7 8.5 -3 -2 -1 01 1.33 2 3 z
Hasta ahora vimos como dado un valor x de la variable, hallar probabilidades transformando (estandarización) la variable en valores de x - z = ¿Cómo hallar un valor de x, dada la probabilidad? Ejemplo: Sea una variable distribuidanormalmente con =4y =2 . Hallar el valor de x que deja por encima de él un 38.20% (0.3820) Se debe desestandarizar : x = z + Se busca en la tabla de acuerdo al área. Con su signo 0.5000 - 0.382 = 0.118 Se busca en la tabla el valor más aproximado :0.1179 corresponde a z=+ 0.30 38.20% Sustituyendo en la fórmula 0.30x2+4 =4.60 x = ? 4.60
TEORIA DE LA ESTIMACION La estadística aborda dos tipos de problemas: La Teoría de la estimación es parte de la inferencia estadística que sirve para determinar el valor de los parámetros poblacionales Estas formas de estimación son complementarias. La estimación puntual representa el primer paso para obtener la estimación por intervalos, que es la que siempre se debe de obtener
El Concepto de Distancia para un Estimador • El “mejor” estimador es el que está más cercano al parámetro de la población que es estimado.
Cuándo un estimador es bueno? Cuando su varianza y el sesgo al cuadrado son pequeños.
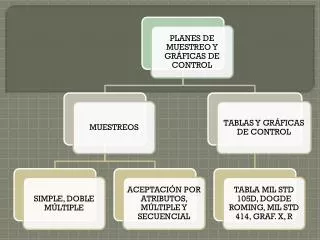
Contraste de Hipótesis Contrastar una Hipótesis Estadísticamente es juzgar si cierta propiedad supuesta para una población es compatible con lo observado en una muestra de ella. Alternativas: Hipótesis A v/s Hipótesis B, donde A y B no pueden cumplirse simultáneamente. • Tipos de Hipótesis: • Hipótesis Alternativas • Hipótesis Anidadas Anidadas: Hipótesis A y B, donde A es un caso especial de B.
HIPOTESIS A CONTRASTAR Se definen: medida de discrepancia con una distribución de probabilidad conocida Regla de decisión(nivel de significación a) Valor crítico o tabulado datos de la muestra Se calcula una medidade discrepanciaValor calculado Se comparan los valores calculado con tabulado ¿se rechaza Ho? H1 SI NO Se extraen conclusiones
Población (podría ser una distribución de cualquier forma, como está) Media = $15,000
Población y Muestra Se tiene información sobre los ingresos mensuales en soles correspondientes una población de 6 personas que trabajan en la pequeña empresa CVC. Se desea conocer el ingreso promedio y la dispersión de los datos alrededor del promedio (desviación standart): • Varianza: • Desviación estándar: • Coeficiente de Variación: El ingreso promedio de las 6 personas es de 2,400 nuevos soles mensual con una desviación típica de 1264.91 que al comparar con el ingreso promedio nos muestra una elevada dispersión que en términos relativos representa el 52.7%.
La cuasivarianza de la población es de la siguiente manera: La cuasivarianza se aplica para fines de utilizarlo como alternativo de la varianza por las propiedades estadísticas relacionadas con su estimador. La cuasivarianza en la muestra es un estimador insesgado de la cuasivarianza poblacional.
Con el propósito de analizar la relación entre todas las muestras posibles y la población se realiza el siguiente ejercicio. La muestra podría ser de tamaño 2, 3 o 4, pero se trabajará con una muestra de tamaño 3. Se halla todas las muestras posibles de tamaño 3 sin reposición y se calcula su respectiva media: Siendo los ingresos de la población lo siguiente: Se trabajará con las 20 muestras posibles de tamaño 3
Promedio de Varianzas Promedio de medias Suma
Al calcular el valor promedio (valor esperado) de las medias muestrales de todas las muestras posibles su valor reproduce el promedio poblacional. El error de muestreo de estimar la media poblacional
Al calcular el valor promedio (valor esperado) de las medias muestrales de todas las muestras posibles su valor reproduce el promedio poblacional. El error de muestreo de estimar la media poblacional
Estimación del Error Muestral Una forma alternativa de obtener el error de estimación es a partir de la fórmula siguiente, para lo cual se requiere conocer, el tamaño de la población N, el tamaño de la muestra n, y el valor de la varianza poblacional :
Entonces, tanto el promedio poblacional como el proveniente de todas las muestras posibles son iguales. Del mismo modo hay una igualdad entre la desviación estándar de la media muestral respecto a la media poblacional y el error estándar de la media muestral o error de muestreo. Como en la práctica sólo se dispone de información de una muestra, se procede a estimar la cuasivarianza poblacional con la muestra , y luego se reemplaza como estimador de la Cuasivarianza poblacional en la formula del Sx
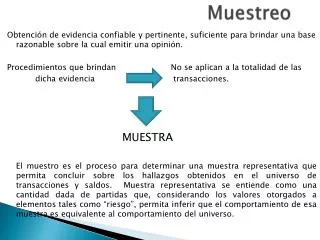
Qué es el “error muestral”? • La magnitud de esa variación se la denomina Error Muestral, para un estadístico, un tamaño de muestra y un tipo de diseño dados. • Muestra 1 • Muestra 2 • Muestra 3 • Muestra .. • . . . . • Promedio muestral • Parámetro
Estimación Muestral Parámetro Qué es el “error muestral”? • El Error Muestral para un estadístico y un tipo de diseño dado disminuye según aumente el tamaño de la muestra A) B) Tamaño de muestra de A menor que de B
Error de muestreo (SX): Es el error muestral expresado en unidades de la variable que se está analizando. Es calculada con los datos de una muestra. Es una medida de su variación en todas las muestras posibles. Mide el grado de precisión de la estadística basado en la muestra • Coeficiente de Variación (CV): Es el error muestral expresado en términos relativos.
Distribución muestral de las medias del tamaño muestral n = 400 Distribución normal Media = $ 15, 000
Cómo se estima el “Error Muestral”? • A partir de la desviación estándar estimado con los datos de la muestra.
Cómo se estima el “Error Muestral”? • A partir de la desviación estándar estimado con los datos de la muestra.
Cuando tendremos “buena” precisión? dispersión débil tamaño de muestra grande tasa de muestreo cercana a 1