Download

1 / 21
320 likes | 567 Views
Distributed Arithmetic. A Bit-Serial Method of Improving Computational Efficiency of Dot-Products. What is Distributed Arithmetic?. DA is a bit-serial technique to greatly reduce resource requirements for the dot product calculation

E N D
Distributed Arithmetic A Bit-Serial Method of Improving Computational Efficiency of Dot-Products
What is Distributed Arithmetic? • DA is a bit-serial technique to greatly reduce resource requirements for the dot product calculation • So-called because the resources are not easily recognizable: “Where’s the MAC module?” • Takes advantage of small tables of pre-computed coefficients and clever rearrangement of the math
Why use Distributed Arithmetic? • In signal processing the most common operation is the dot product • DA lends itself well to FPGA implementation due its use of lookup tables • DA can reduce gate count by 50%-80% in signal processing arithmetic!
Recall: The Dot Product • It turns out that the dot product is used extensively in DSP (FIR, FFT, etc) • Recall that dot product is a sum of products: • Written as a summation:
Why is the Dot Product important? • Simple example: smoothing data via DSP (low-pass filter) • Accomplished with an FIR filter. General form: • So we could implement a “3-tap (K=4) moving average filter”: (In this special case, A1=A2=A3=0.33)
Developing the Math • Recall the goal: • X is the filter input, (digital!), so let’s consider two’s complement representation (scaled x<1 for cleanliness) • Putting them together N – total bits
Developing the Math • Expand the summation: • We can precompute all terms that depend on the input data (bk0..bkK) and store them in a ROM of size 2K+1 • The x inputs can then be used to address the ROM directly: LUT! Since bknis 0 or 1, this has only 2K possible values Two possible values
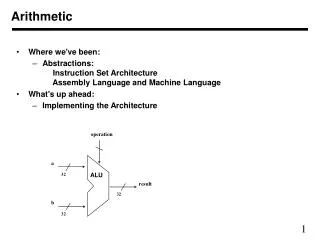
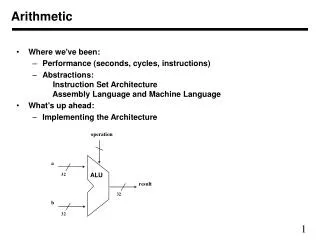
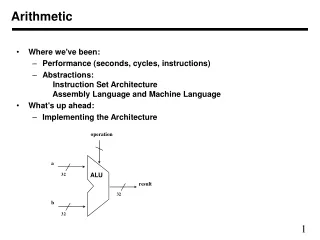
Developing the Hardware • Non-DA Hardware Implementation 8-bit Adder Based on the original equation 8-bit Multiplier
The Scaling Accumulator Multiplier • We said this is ‘bit-serial’ technique, so how can we perform multiplication? Here, x is 4-bit input and A is 8-bit constant Shift right by 1 AND with 1 parallel and 1 serial input ExampleMultiplication x = 1011 A = 10110011 10110010 0000000 1 1011001 1 +1011001 10010000101 A x Result register
Developing the Hardware • So, now we substitute the scaling accumulator into our original design. Getting closer...
Developing the Hardware • Let’s rearrange the hardware to match our expanded eqn: We first sum the products of each input bit and its constant Then we add and scale each of those terms
Developing the Hardware • Now recall that we had the clever idea to use pre-computed sums in a LUT for the bitwise addition
HW Finishing Touches • We need to accommodate the negative term, so we add one more address line to the LUT called Ts. ROM size now 2K+1 • Ts is a timing signal. Ts =1 during sign bit time, 0 otherwise • We also need this bit to know when the final result is ready For all Ts = 1 the ROM contains the negative of the appropriate sum
Complete DA Hardware! This is an example of K=4 DA dot-product hardware ROM Size = 2K+1=25=32 Here is our scaling accumulator Switch SWA in pos 2 after Ts=1, at which point y contains final result
Performance • Computes N-bit dot product in N cycles • Reduced area and high speed due to the ROM • However, requires 2K+1 size ROM (grows exponentially with input lines) • Input sizes often 16 bits -> Need 128K ROM!
Distributed Arithmetic Speed • Bit-serial means N-bit dot product requires N cycles... Slower than parallel? • N HW multipliers not generally practical due to large area\power! • Time-multiplexing your parallel HW multiplier means you lose the speed gain: N vs K • Example: K=8, N=8 takes the same time on time multiplexed parallel HW vs DA bit-serial
Improving our HW: ROM size • We can reduce the ROM size to 2K with some tricks • There are other math tricks to reduce the size further to 2K-1 Replace adder with adder/subtractor Ts becomes control line for adder/subtractor ROM size is reduced by half
Improving our HW: Speed • Speed determined by serial nature of input – 1 BAAT • We can expand the HW to do multi-bit at a time Introduce input as bit pairs x10x11, x12x13, etc Shift LSB of pair result by 1 Shift accumulator feedback by 2 Requires 2 ROMs instead of 1
When to use Distributed Arithmetic • DA lends itself easily to DSP because of its easy application to the dot product • DA is easily implementable on FPGA because of the similar architecture-> LUTs (of course better on custom hardware) • DA is not limited to dot product; will work for any algorithm where pre-computed values can be leveraged
Conclusion • DA is a very efficient means of mechanizing the dot product • The use of DA can save 50-80% area over the parallel approach • Like everything, DA has tradeoffs: ROM size input lines Speed area (multi ROM)
References & Further Reading • Application of Distributed Arithmetic to Digital Signal Processing: A Tutorial Review. White, Stanley. IEEE ASSP Magazine July 1989 (I pulled most of the basic talk info from here) • Parallel and Pipelined Architecture Designs for Distributed Arithmetic-Based Recursive Digital Filters. Hwang, H. and Su. C. IEEE Xplore VLSI Signal Processing IX, 1996 35-44 (this has some slight remarks about bit parallel vs bit serial, also auto-regressive moving average filter example) • Distributed Arithmetic for Efficient Base-Band Processing in Real-Time GNSS Software Receivers. Waelchli, G et al. Journal of Electrical and Computer Engineering volume 2010 (application to GPS) • An FPGA-Based Parallel Distributed Arithmetic Implementation of the 1-D Discrete Wavelet Transform. Al-Haj, Ali. Informatica 29 (2005) 241-247(DSP example using a Virtex FPGA)