Download

1 / 13
130 likes | 209 Views
Locality Optimizations in OceanStore. An introduction to introspective techniques for exploiting locality in wide area storage utilities. Patrick R. Eaton Dennis Geels. Agenda. OceanStore Review Problem Overview Previous Work Proposed Solution Prefetching Algorithm Preliminary Results

E N D
Locality Optimizations in OceanStore An introduction to introspective techniques for exploiting locality in wide area storage utilities. Patrick R. Eaton Dennis Geels
Agenda • OceanStore Review • Problem Overview • Previous Work • Proposed Solution • Prefetching Algorithm • Preliminary Results • Future Work
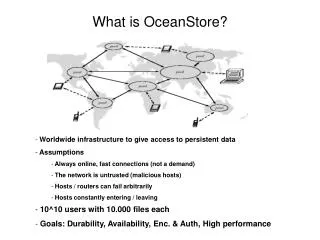
OceanStore Review • Properties of OceanStore relevant to introspective locality optimizations • implemented in the extremely wide area • has many places to put any single piece of data • cannot rely on users to make relationships among data explicit • depends on effective locality optimizations for improved performance • No possible way to solve exactly
Problem Overview • Passively observe data accesses • data shared among multiple users • single users accessing the network from different physical locations • data is replicated across the network • Optimize the location of data to provide quicker access to users • cluster semantically related data • replicate data to move it closer to consumers • migrate primary replicas toward the source of updates
Measurable Attributes • File Temperature • A measure that indicates the frequency of access to the file • A hot file is frequently accessed • Semantic Distance (Kuenning) • Any measure that can quantify relationships between files on the range [0,) • Local distance relates one instance of a file access to another • Reference distance is an aggregate measure that summarizes all local distances for a pair of files • Typical measures use access order or timing information
Prefetching Techniques • Automatic Prefetching (Griffoen and Appleton) • construct a probability graph that records accesses which follow within a lookahead period • predict a prefetch when the chance of an access is above a tunable parameter • Context Modeling (Kroeger and Long) • record in a trie all access sequences which have been observed • maintain pointers to all nodes which represent current contexts • predict a prefetch when the chance of an access to a child of a current context is above a probability threshold
Our Approach • Exploit the ideas of semantic distance to compute relationships among data • Cluster data based on the observed relationships • Store a summary of these relationships with the data • Migrate (prefetch) files based on familiar patterns in the access stream • recognize higher order correlations as in context modeling • tolerate noise in the access stream
Motivation for Prefetching Algorithm A Y Many patterns can be predicted only by observation of higher-order correlation--combining several pieces of past history. K B Z A Other patterns can only be detected through identification and filtering of noise. B C
FHB y B w g o F w K Distance Table (B,F) w K (y,B) w g o F K (o,w) K General Prefetching Algorithm • Update • Record the most recent file accesses in the file history buffer (FHB) • Each time a new file S is accessed, extract all triples of the form (FHB(i), FHB(j)) S from the FHB and update in the second-order distance table • Predict • Each time a new file S is accessed, examine the distance table entries of (FHB(i), S) • Prefetch files that are predicted with confidence above a certain threshold • Problems • O(k2) work to update distance table • Noise infects distance table
y B w g o F K h y B w t o F w K y B w g w K p e Distance Table y B w g t B w g t o w g K t o Optimizations to the Prefetching Algorithm Indicative FHB’s • First-order distance table • Records files that are close, as measured by semantic distance • Allows reverse lookup • Use first-order distance tables to filter out irrelevant file relationships • Update only relevant entries in the second-order distance table • Search for predictions based on only relevant access pairs
Update Extract relevant triples by intersecting the FHB with the results from the reverse lookup in first-order tables FHB 1st Order Table 2nd Order Table y Q t u v R w x S Q a b R c d (Q,R) S a b d f R b S g h t (Q,w) b t S t d e R v (Q,v) t d e Check table for prediction Find parents of S Find parents of R Update table Find parents of R t x b y t Q u v R Prefetching Algorithm Example • Predict • Extract relevant doubles by intersecting the FHB with the results from the reverse lookup in the first-order tables • Prefetch if the second-order table predicts a future access with sufficient confidence
Future Work • Retarget the simulations to model OceanStore • Continue to refine the prefetching algorithm • Examine the potential of higher order prefetching • Combine prefetching and clustering • Look for opportunities to test the ideas on different workloads