Download

1 / 1
10 likes | 133 Views
Learn about the development of a Beowulf cluster for scientific modeling at the University of Maine, using the Princeton Ocean Model parallel version for Penobscot Bay. Explore the challenges, progress, and future work in optimizing the cluster for efficient performance.

E N D
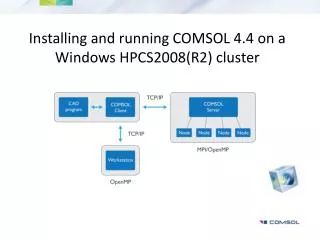
Linux based Beowulf clusters provide a relatively inexpensive way to achieve high-performance computing for scientific modeling. Funded by a grant from the Maine Science and Technology Foundation (MSTF), a joint project between the Computer Science department and the School of Marine Sciences at the University of Maine has been in progress since January of 2000. The goal of this project is to create a parallel version of the Princeton Ocean Model (POM) to run on a Beowulf cluster. Specifically, the model is of Penobscot Bay on the coast of Maine. What is a Beowulf Cluster? The Beowulf FAQ* states: “It's a kind of high-performance massively parallel computer built primarily out of commodity hardware components, running a free-software operating system like Linux or FreeBSD, interconnected by a private high-speed network. It consists of a cluster of PCs or workstations dedicated to running high-performance computing tasks. The nodes in the cluster don't sit on people's desks; they are dedicated to running cluster jobs. It is usually connected to the outside world through only a single node.” The key points of a Beowulf cluster are that it is made of low cost, easily available parts and software when possible. Our Beowulf Cluster: Status: Although the model runs on the Beowulf cluster, we are still seeing differences in results between the Serial model and the Parallel model as seen in Figure 5. It appears that boundary conditions are propagating into the model at an accelerated rate. This most likely is due to inconsistencies in the overlap regions. Even with the Totalview parallel debugger, this has been a difficult problem because there is a tremendous amount of data to analyze. It is this sort of problem that makes shared memory parallel systems so attractive, since it is much easier to parallelize a program on a shared memory system. However, the benefit to solving this problem is that the program can be run on a very large cluster at a relatively low cost. Going Parallel: The starting point for this code came from the TOPAZ† project at the University of Minnesota. “TOPAZ is a compiler tool that helps in the conversion of serial codes to parallel form.”†† TOPAZ was used to help create a parallel version of the POM97 code and the resulting code was called MP-POM (Massively Parallel Princeton Ocean Model) and made available on the web†††. The code was ported to be used on either a Cray T3E or a SGI Origin 2000. The Penobscot Bay code also had its origin stemming from the POM97 code. Multiple comparisons were made to change the serial Penobscot Bay code into its parallel form. In general, the serial Penobscot Bay code was checked against the POM97 code, to see what changes were made specific to Penobscot Bay. Similarly, the MP-POM code was compared to the POM97 to see what changes were made specific to MP-POM. Changes were then made to the MP-POM code to incorporate the Penobscot Bay specific changes. Figure 5 Parallel-Serial Difference Future Work: We intend to fix the current problems to the point where we get results consistent with the serial code. At that point we will increase the resolution of the model to 125 meters. Without the Beowulf system it would take roughly two and one half days to compute one day of the model. With the Beowulf system we hope to compute one day of the model in six hours. We also plan to explore different decomposition schemes in order to improve the performance. Currently, the domain is broken into uniform sub-domains. Some of these sub-domains have just a small amount of water in them, while others are all water. By changing the decomposition rules it should be possible to create sub-domains with more equal sized areas of water. This should result in a more even load across processors which should improve performance. We plan to convert the cluster into single CPU nodes and hope to get better performance with this because of reduced memory traffic from having only one process per node as opposed to two. Domain Decomposition: In order to run the Princeton Ocean Model on a Beowulf cluster using distributed memory, a technique called Domain Decomposition is used. The idea is to break up the grid into smaller sections. Each section is assigned to a separate process and each process runs the Princeton Ocean Model on its sub-domain. In turn, each process is assigned to a separate processor. When calculations are performed at the borders of the sub-domain, communication with bordering processes is required to be consistent with the serial code. To reduce communication between processors, each process keeps an “Overlap”†††† region around its sub-domain that contains a few rows and columns of data from neighboring processes. When calculations are performed at the borders of the sub-domain, the process can consult the overlap region rather than having to spend the time to communicate with its neighbor. Figure 1. Our Beowulf Cluster All nodes have dual Pentium III 600 Mhz processors running Redhat Linux 6.1, kernel 2.2.14 SMP. The Slave nodes boot from their own disks but mount their home directories from the Master node. The Master node is used as the login machine. Programs are started from this machine and processes are distributed to the Slave nodes. The Beowulf system has a distributed memory architecture with each node having its own memory. Only certain programs are good candidates for use on a Beowulf system. The program must be easily broken down into sections such that communication between the sections is at a minimum. Each section is then assigned a processor. The reason that communication between each section should be minimized is that it has to be done over the network which is very slow in comparison to direct memory communication. The mechanism that is used for communication is called Message Passing. Message Passing calls are put in the code to send data between the nodes. It is the task of the programmer to make sure that the variables are up to date when they are needed. Running the Princeton Ocean Model on a Beowulf Cluster Stephen Cousins and Huijie Xue School of Marine Sciences University of Maine, Orono Figure 3. Domain Decomposition Acknowledgements: * http://www.dnaco.net/~kragen/beowulf-faq.txt † TOPAZ compiler tool developed by Aaron C. Sawdey †† This sentence is from “Parallelizing the Princeton Ocean Model Using TOPAZ”: Wade Oberpriller, Aaron C. Sawdey, Matthew T. O’Keefe, Shaobai Gao, and Steve A. Piacsek †††http://www.borg.umn.edu/topaz/mppom †††† This term is from “Parallelizing the Princeton Ocean Model Using TOPAZ”: Wade Oberpriller, Aaron C. Sawdey, Matthew T. O’Keefe, Shaobai Gao, and Steve A. Piacsek Many thanks to Jon Thomas who built the Beowulf Cluster. Web Links: Ocean Modeling Group, University of Maine School of Marine Sciences: http://www.umeoce.maine.edu UMaine Beowulf project: http://typhon.umcs.maine.edu/beowulf University of Maine: http://www.umaine.edu Maine Science and Technology Foundation: http://www.mstf.org Princeton Ocean Model: http://www.aos.princeton.edu/WWWPUBLIC/htdocs.pom Email addresses: Stephen Cousins: cousins@umit.maine.edu Huijie Xue: hxue@maine.edu Performance Results: Currently, when running with 16 single-CPU nodes, the Beowulf version of the Princeton Ocean Model runs about six times faster than the Serial version of POM running on a similar speed processor. As can be seen by the chart below, we would probably see significantly higher performance if our Beowulf Cluster was configured as 32 Uni-processor nodes as opposed to 16 Dual-processor nodes. This is believed to be due to memory bandwidth issues in Dual-PIII systems. The Penobscot Bay Model: The model that we are working on is of the Penobscot Bay on the Coast of Maine. Penobscot Bay is the largest estuarine embayment in the Gulf of Maine, the second largest on the U.S. east coast. The Bay has been historically and remains a very important fishery ground. It harbors the most productive lobster habitat and accounts for roughly 50% of the lobster landings for the entire state of Maine. The model is a Princeton Ocean Model at roughly a 500 meter resolution in a 151 by 121 horizontal grid with 15 sigma levels. It receives daily fresh water discharge rates for the Penobscot river as well as hourly wind readings at Matinicus rock. Figure 4. Performance Figure 2. Penobscot Bay 2001 Terrain-Following Coordinates User's Workshop Boulder, Colorado, August 20-22