Download

1 / 43
430 likes | 602 Views
Backpropagation. Backpropagation (MLP). 1.- Las redes de 1 sólo nivel Número muy limitado de representaciones. 2.- No ha existido un algoritmo multinivel de aprendizaje. 1969 1 + 2 “Perceptrons” (Minsky & Papert). 1970 1982, Eclipse / invierno de las NN 1974 Werbos 1982 Parker

E N D
Backpropagation (MLP) 1.- Las redes de 1 sólo nivel Número muy limitado de representaciones. 2.- No ha existido un algoritmo multinivel de aprendizaje. 1969 1 + 2 “Perceptrons” (Minsky & Papert). 1970 1982, Eclipse / invierno de las NN 1974 Werbos 1982 Parker 1986 Rumelhart, Hilton, Williams
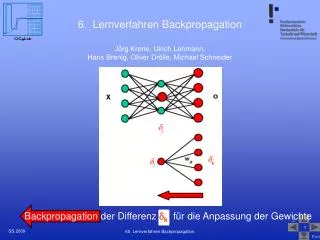
Elemento neuronal vector de entrada vector de pesos -1 x1 w1 . . . wj net y=fa(net) xj fa . . . wn xn
Función de activación umbral / escalón y 1 net
Función de activación umbral bipolar y 1 net -1
Función de activación sigmoidea Si Función umbral y =50 1 =5 0.5 net
Función de activación sigmoidea • Introduce la no-linealidad. • Derivable y de derivada simple. • Control automático de la ganancia: 1 Ganancia alta 0.5 Ganancia estable Ganancia estable net 0
Función de activación sigmoidea bipolar f(x) 1 x -1
Función de activación tangente hiperbólica f(x) 1 x -1
Características BPN • Arquitectura: • Multilayer perceptron. • Full conected. Feedforward • Aprendizaje supervisado. • Función de activación
Arquitectura BP Vector de entrada 0 l m 1 m -1 1 1 i h g j nm-1 n1 nm nl n0 Capa de puntos de entrada Capa de Salida Vector de salida Salida Deseada Capas Ocultas
Regla Delta generalizada m-2 m-1 m 1 h i j dj donde
Regla Delta generalizada El error para cada patrón será: El error total: Derivando respecto a ij según la regla de la cadena donde es el término de error por tanto los pesos de la capa de salida se actualizan
Regla Delta generalizada donde es el término de error Los pesos se actualizan como: Para las capas ocultas
Algoritmo de aprendizaje 1.- Se inicializan con valores aleatorios y pequeños (< 1) 2.- Se entra un patrón 3.- Se calcula la entrada neta para la primera capa oculta. 4.- Se calcula la salida de la primera capa oculta.
Algoritmo de aprendizaje 5.- Repetir 3 y 4 para todas las capas ocultas y para todas la neuronas 6.- Se calcula la entrada neta a la capa de salida. 7.- Se calcula la salida de la red. 8.- Se calcula el término de error para las unidades de salida.
Algoritmo de aprendizaje 9.- Se calcula el término de error para las unidades ocultas. 10.- Se actualizan los pesos de la capa de salida. 11.- Se actualizan las capas ocultas.
Notas 1.- Los términos de error de una capa se calculan antes de actualizar los pesos de la capa anterior. 2.- El orden de actualización de los pesos dentro de una capa no importa. 3.- Se considera que la red ha aprendido cuando Ees suficientemente pequeño p. 4.- No suele ser necesario probar todos los vectores de entrenamiento. 5.- Se pueden usar vectores con ruido para entrenar la red. A veces va bien aunque tengamos patrones correctos. 6.- La red permite la generalización. 7.- Los patrones NO se deben entrar clase a clase sino de forma doblemente o aleatoria de clases y patrones. En caso contrario la red podría “olvidar”.
Inicialización Nguyen-Widrow n = Unidades de entrada p = Unidades ocultas = Factor de escala Más velocidad N-W Mejor convergencia
Inicialización Nguyen-Widrow Función de Activación = E < 0.05
Inicialización de los pesos • Aleatoriamente [-0.5 , 0.5]. • Método Nguyen-Widrow. • La inicialización de los pesos afecta a: • Si se llega a un mínimo (local o global). • La velocidad de convergencia.
Fin del entrenamiento • Si el error (E) o la variación del error (E) es suficientemente pequeña. • Realizar un número mínimo de iteraciones (NF). • Validación por cruces: Disponer de dos conjuntos de patrones, uno de entrenamiento y otro de test. (A veces son tres conjuntos: Entrenamiento, Validación y Test con una relación 1:1:1 )
Número de parejas de entrenamiento • = Número de pesos. • = Porcentaje de patrones mal clasificados.
Representación de los datos • Binarios o Bipolares. Con entradas bipolares, todas tienen efecto sobre el cálculo de la net. • Continuos. Más fáciles de actualizar.
Número de capas ocultas • Una capa oculta suele ser suficiente para solucionar la mayoria de problemas. • Dos niveles de capas ocultas hacen que la red aprenda más rápido.
Valor de • Fijo. • - Para evitar que oscile mucho (0.05 < < 0.25) • Variable. • - Ha de disminuir a medida que disminuye el error.
Número de nodos • En las capas de entrada / salida, determinados por el problema. • En las capas ocultas poner el mínimo número de nodos posible. • Si la red no aprende Añadir nodos en las capas ocultas. • Si la red converge y rápido probar con menos nodos en las capas ocultas. • Si ciertos pesos no se modifican se pueden eliminar nodos.
Heurísticas para mejorar el algoritmo BP • 1.- Secuencial versus “BATCH” • “BATCH” suaviza mas eficiente computacionalmente sobre todo si los datos son muchos y redundantes • 2.- Maximizar la información • Entrando aleatoriamente los datos entre una Epoch y otra • “Emphasizing Scheme” + Patrones “Dificiles” • Peligro de patrones mal clasificados
Heurísticas para mejorar el algoritmo BP 3.- Función de Activación Antisimétrica
Heurísticas para mejorar el algoritmo BP • 4.- Salidas deseadas • Para valores grandes de net el sistema se satura. Se toma un valor para evitar una lentitud del aprendizaje. Si • para +a tomamos d = a - • para –a tomamos d = -a + • si a = 1.7159 = 0.7159 y d = 1 • 5.- Normalización de entradas • Preprocesamiento de las entradas • Hacer la media de los datos igual a cero • Decorrelacionar las entradas PCA • Ecualización de la covarianza
Problemas 1.- Aprendizaje muy lento. Si el problema es complejo puede tardar días / semanas. Problema paralelo Implementación secuencial 2.- Parálisis de la red. Se produce cuando no se trabaja en la zona central de la función sigmoidea; el aprendizaje se detiene y la red no aprende. Se evita con Tiempo de aprendizaje
Problemas • 3.- Mínimos locales. La función de error tiene colinas y valles. BPN utiliza la dirección del gradiente para llegar a un mínimo; puede que la red quede atrapada en un mínimo local. • métodos estadísticos que resuelven este problema Lentos. • Si las variaciones son infinitesimales tiempo de aprendizaje. • Si el paso es grande Paralisis e Inestabilidad. • soluciones en algún tipo de redes.
Momento es el momento Para mejorar el tiempo de aprendizaje se introduce un término (momentum) proporcional al cambio de pesos en el paso anterior. La red evoluciona en función del gradiente actual y del anterior • Con esta mejora la red converge más rápidamente y evita mínimos locales. • La relación entre y suele ser recíproca. Si (0,9) , (0,1) y al contrario. • Unos valores aceptables, = 0,1 y = 0,5
Aplicaciones • 1.- Reconocimiento de caracteres. • NEC, sistema de reconocimiento de códigos postales con 99% • de efectividad. Utilizan algoritmos convencionales y una red • BPN. • Sesnowski y Rosenberg (1987) NETTALK, sistema de • traducción del inglés escrito al hablado. • Burr (1987) Sistema de reconocimiento de palabras • manuscritas con 99.7% de efectividad, utilizando diccionario. • 2.- Compresión de información (imágenes). • Cottrell, Munro i Zipser (1987), muy buenos resultados. • Las redes tienen en cuenta la información de percepción (JPEG • y otros no). • 3.- Pronunciación de palabras.
Interpretación Probabilística de una NN Puede ser estimado a partir de las proporciones de ejemplos de entrenamiento para cada clase Se puede hacer una suposición de una función densidad Gausiana 1.- Las Redes neurales reconocen patrones complejos en un mundo real, ruidoso e incierto 2.- La incertidumbre es estudiada en un marco probabilístico. - Si suponemos un problema de clasificación en K clases de salida T. Bayes La probabilidad de mala clasificación se minimiza cuando asignamos
Interpretación Probabilística de una NN Lippmann (1991) demuestra que las Redes Neurales calculan directamente Los pesos se calculan a partir de la minimización del error (mínimos cuadrados)