Download
1 / 1
10 likes | 123 Views
ECHO DEPository Project: Highlight on tools & emerging issues. Overview. 3. Tools Development.

E N D
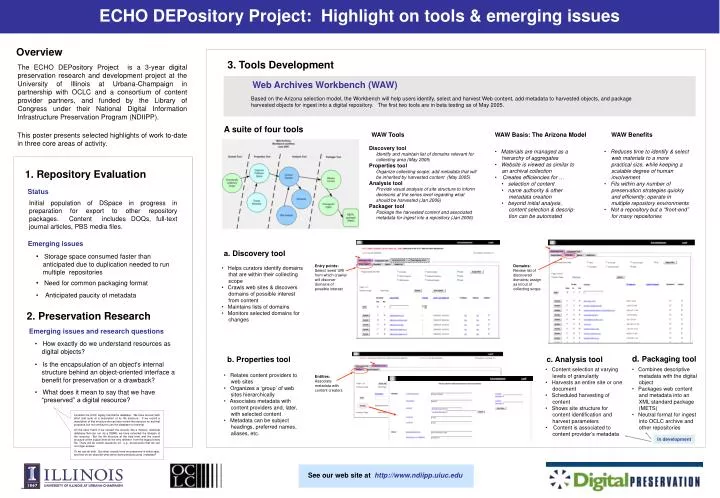
ECHO DEPository Project: Highlight on tools & emerging issues Overview 3. Tools Development The ECHO DEPository Project is a 3-year digital preservation research and development project at the University of Illinois at Urbana-Champaign in partnership with OCLC and a consortium of content provider partners, and funded by the Library of Congress under their National Digital Information Infrastructure Preservation Program (NDIIPP). Web Archives Workbench (WAW) Based on the Arizona selection model, the Workbench will help users identify, select and harvest Web content, add metadata to harvested objects, and package harvested objects for ingest into a digital repository. The first two tools are in beta testing as of May 2005. A suite of four tools This poster presents selected highlights of work to-date in three core areas of activity. WAW Tools WAW Basis: The Arizona Model WAW Benefits • Discovery tool • Identify and maintain list of domains relevant for collecting area (May 2005) • Properties tool • Organize collecting scope; add metadata that will be inherited by harvested content (May 2005) • Analysis tool • Provide visual analysis of site structure to inform decisions at the series level regarding what should be harvested (Jan 2006) • Packager tool • Package the harvested content and associated metadata for ingest into a repository (Jan 2006) • Materials are managed as a • hierarchy of aggregates • Website is viewed as similar to • an archival collection • Creates efficiencies for … • selection of content • name authority & other • metadata creation • beyond initial analysis, • content selection & descrip-tion can be automated • Reduces time to identify & select • web materials to a more practical size, while keeping a scalable degree of human involvement • Fits within any number of • preservation strategies quickly and efficiently; operate in multiple repository environments • Not a repository but a “front-end” • for many repositories 1. Repository Evaluation Status Initial population of DSpace in progress in preparation for export to other repository packages. Content includes DOQs, full-text journal articles, PBS media files. Emerging issues a. Discovery tool • Storage space consumed faster than • anticipated due to duplication needed to run multiple repositories Analysis tool Packaging tool Entry points: Select ‘seed’ URI from which crawler will discover domains of possible interest Domains: Review list of discovered domains; assign as in/out of collecting scope • Helps curators identify domains • that are within their collecting scope • Crawls web sites & discovers • domains of possible interest from content • Maintains lists of domains • Monitors selected domains for • changes • Need for common packaging format • Anticipated paucity of metadata 2. Preservation Research Emerging issues and research questions • How exactly do we understand resources as • digital objects? d. Packaging tool b. Properties tool c. Analysis tool • Is the encapsulation of an object's internal • structure behind an object-oriented interface a benefit for preservation or a drawback? • Content selection at varying • levels of granularity • Harvests an entire site or one • document • Scheduled harvesting of • content • Shows site structure for • content identification and harvest parameters • Content is associated to • content provider’s metadata • Combines descriptive • metadata with the digital object • Packages web content • and metadata into an XML standard package (METS) • Neutral format for ingest • into OCLC archive and other repositories • Relates content providers to • web sites • Organizes a ‘group’ of web • sites hierarchically • Associates metadata with • content providers and, later, with selected content • Metadata can be subject • headings, preferred names, aliases, etc. Entities: Associate metadata with content creators • What does it mean to say that we have • “preserved” a digital resource? Consider the UIUC legacy mainframe database. We have arrived (with effort and luck) at a description of its file structure. If we record a description of that structure we can later review the resource for archival purposes, but not continue to use the database for retrieval. On the other hand, if we convert the records into a modern, relational database that can run via a DBMS, we have extended the lifespan of the resource. But the file structure at the byte level and the record structure at the logical level will be very different from the legacy binary file. There will be certain questions (of, e.g., provenance) that we can no longer answer. Or we can do both. But what, exactly have we preserved in either case, and how do we describe what we've done precisely using metadata? In development See our web site athttp://www.ndiipp.uiuc.edu




















