Download

1 / 29
310 likes | 603 Views
Epidemiology and Applied Statistics Review Module 2 – Data Types & Applied Statistics. American College of Veterinary Preventive Medicine Review Course Katherine Feldman, DVM, MPH, DACVPM kfeldman@umd.edu 301-314-6820. Plan. Students review modules on their own

E N D
Epidemiology and Applied Statistics Review Module 2 – Data Types & Applied Statistics American College of Veterinary Preventive Medicine Review Course Katherine Feldman, DVM, MPH, DACVPM kfeldman@umd.edu 301-314-6820
Plan • Students review modules on their own • Send questions by email to Katherine Feldman (kfeldman@umd.edu) by Friday March 23 a.m. • Conference call Friday March 23 2-3 p.m. • Watch email and Blackboard for conference call details
References • Gordis L. Epidemiology, 3rd ed. Elsevier Saunders, Philadelphia, 2004. • $47.95 from Amazon.com • Norman GR, Streiner DL. PDQ statistics, 3rd ed. BC Decker Inc., Hamilton, 2003. • $17.79 from Amazon.com
Independent & Dependent Variables • Independent variables • The characteristic being observed or measured that is hypothesized to influence an event of manifestation • E.g., Risk factors • Dependent variables • The value of which is dependent on the effect of other variable(s). A manifestation or outcome whose variation we seek to explain or account for by the influence of independent variables. • E.g., Disease outcome
Continuous vs. Discrete Data • Continuous • Quantitative with potentially infinite number of values along continuum • Can be measured to as many decimal places as measuring instrument allows • E.g., Weight, height • Discrete • Count – quantitative data that can be arranged into discrete, naturally occurring or arbitrarily selected groups or sets of values e.g., pulse rate • Categorical • Nominal – qualitative, named category; the order of the categories is irrelevant to statistical analyses e.g., gender, reproductive status • Ordinal – ordered categories, qualitative e.g., disease staging in cancer, education level
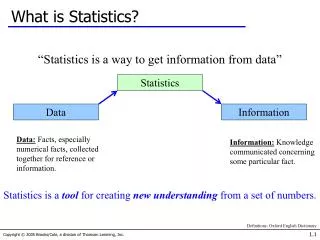
Once we take a sample from a population we have two goals: • Summarize and describe the data • Test hypotheses and make inferences about the population based on what has been observed in the sample
Descriptive vs. Inferential statistics • Descriptive statistics • Communicate results without attempting to generalize • Important first step in epidemiologic studies • Inferential statistics • Used to infer the likelihood that the observed results can be generalized to other samples of individuals
Distributions • Data is distributed in some manner among various categories or throughout possible values • When values are plotted, we get a distribution • Frequency histogram • Frequently used in epidemiology • We can see proportion of the total sample in each category • E.g., If we want to know the probability that entrants are age 78 or 79 years, then add up the probabilities in those categories
Measures of central tendency • Mean • The average, determined by adding all values and dividing by total number of subjects • Mode • The most common value in the data • Median • Value in dataset where ½ subjects are smaller and ½ are larger • List data in ascending order • Find the median location as (n+1) / 2
For a symmetrical distribution, the mean, median, and mode all occur at same point • The median is less sensitive to extreme observations than the mean • The mean uses all data and has nicer statistical properties than the median • The mode is mainly useful for nominal variables
Mode approximately $50,000 Median approximately $60,000 Mean approximately $70,000 Skew
Measures of Dispersion (Variation) • Need to be able to measure the extent to which individual values differ from mean • Range • The difference between the highest and lowest values
Variance • Average squared deviation of each value from the mean Σ(Individual value – mean value)2 Number of values - 1 • Because variance is reported in squared units, take square root of the variance and report standard deviation • Standard deviation (SD) • Average measure of how individual values differ from the mean • The smaller the SD, the less each score varies from the mean • The larger the spread of scores, the larger the SD. ___________________________ SD = Σ(Individual value – mean value)2 Number of values - 1 • When reporting estimates of central tendency, report measure of dispersion, e.g., mean ± SD √
Normal Distribution • Many variables tend to follow bell-shaped distribution • Most values clustered symmetrically near mean • Few values falling in the tails • Shape of curve can be expressed in terms of mean and SD • 68% are in 1 SD of mean • 95.5% are in 2 SDs • 2.3% in each tail
Epidemiologists never achieve degree of control possible in experimental settings. • While our results may reflect the truth, it is also possible that there are alternative explanations • Findings are due to random error (chance) • Findings are due to systematic error (bias) • Findings are confounded by other variables that were unmeasured or uncontrolled
Inference & Assessing the Role of Chance • A principal assumption underlying use of measures of disease frequency is that we can make inferences to the population based on a sample • Because of random variation from sample to sample, the observed results will probably reflect the play of chance
We can quantify the degree to which chance variability may account for the results observed in any individual study • By performing appropriate test of statistical significance and determining the p-value
Hypothesis Testing • Performing a test of statistical significance to determine likelihood that sampling variability (chance) explains the observed results • Make explicit statement of hypothesis to be tested • Null hypothesis (H0) • Always the hypothesis of no difference • The assertion that there is no association between exposure and disease, e.g., RR = 1, OR = 1 • Alternative hypothesis (H1 or HA) • The assertion that there is some association between exposure and disease, e.g., RR ≠ 1, OR ≠ 1
The Appropriate Test of Statistical Significance • Will vary by study design, data type and situation • Generates a test statistic that is a function of • The difference between observed values in the study and expected values if null hypothesis were true, and • The variability in the sample • Will lead to a probability statement (p-value)
p-value • Probability that an effect at least as extreme as that observed in a particular study could have occurred by chance alone, given H0 is true • The larger the test statistic, the lower the p-value • Convention in medical research is when p ≤ 0.05, then association between exposure and disease is statistically significant • There is no more than a 5% (1 in 20) probability of observing results as extreme as that observed due solely to chance • If p > 0.05, then chance cannot be excluded as a likely explanation
t Test • Parametric test for differences between means of independent samples • Continuous data • H0: mean1 = mean2 HA: mean1 ≠ mean2
Chi-square test • Test whether observed differences in proportions between study groups are statistically significant • I.e., Whether there is an association between exposure and outcome • Categorical data • H0: proportions are equal; no association HA: proportions are different; there is an association
Chi-square test • O = observed count in a category • E = Expected count in that category under the null hypothesis • Expected counts, E, can be determined by • R = Row total • C = Column total • T = Table total
One of the major determinants of the degree to which chance affects the findings in any particular study is sample size • In general, the smaller the sample from which our inference is made, the more variability there will be in the estimates and the less likely the findings will reflect the experience of the total population • Conversely, the larger the sample on which the estimate is based, the less variability and the more reliable the inference
Confidence Intervals • p-values are composite measures that reflect • Magnitude of the difference between the groups, AND • Sample size • Therefore, if sample size is sufficiently large then small differences may be statistically significant • Conversely, large effects may not achieve statistical significance if sample size is not sufficient • It is not possible to determine the contribution of the sample size just by looking at the p-value
Confidence Intervals (CI) • A related but more informative measure of the role of chance is the confidence interval (CI) • The range within which the true magnitude of effect lies with a certain degree of assurance • When using 0.05 as your cutoff for statistical significance, then use corresponding 95% CI • If null value (e.g., OR=1) is included in 95% CI, then the corresponding p-value is greater than 0.05 • E.g., 95% CI = (0.8, 1.7) NOT SIGNIFICANT • If null value (e.g., OR=1) is not included in CI, then the p-value is less than 0.05 and the association is statistically significant • E.g., 95% CI = (1.4, 4.8) SIGNIFICANT
Confidence Intervals (CI) • Width of CI indicates amount of variability inherent in the estimate and thus the effect of sample size • The larger the study sample, the more stable the estimate, and the narrower the CI • The wider the CI, the greater the variability in the estimate and the smaller the sample size