Download
1 / 1
10 likes | 196 Views
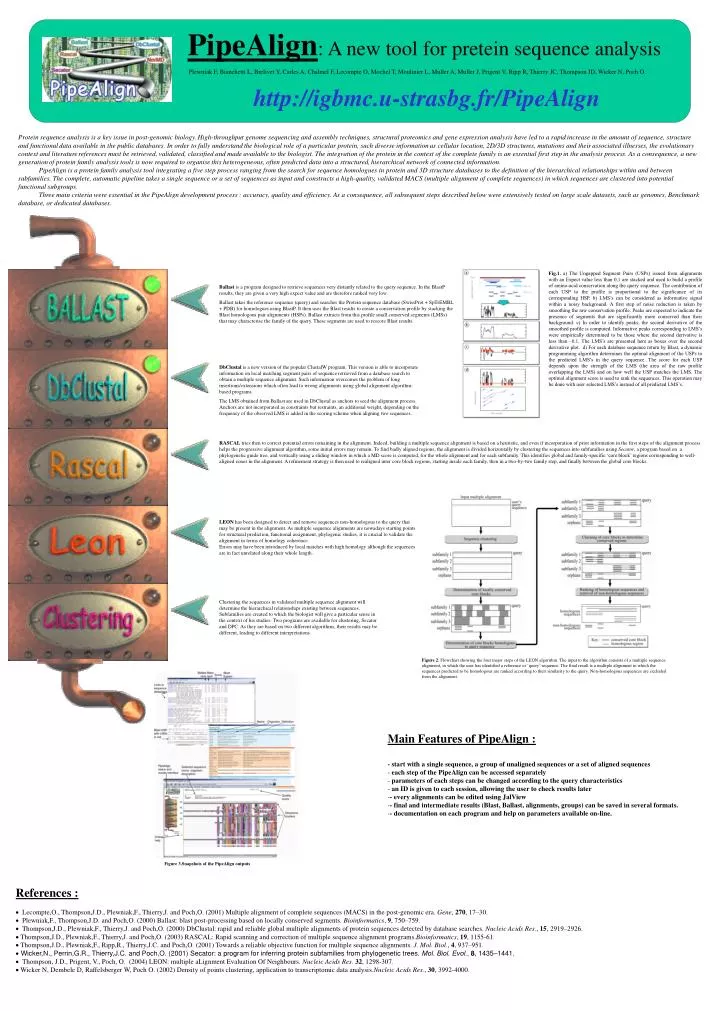
PipeAlign : A new tool for pretein sequence analysis http://igbmc.u-strasbg.fr/PipeAlign. Plewniak F, Bianchetti L, Brelivet Y, Carles A, Chalmel F, Lecompte O, Mochel T, Moulinier L, Muller A, Muller J, Prigent V, Ripp R, Thierry JC, Thompson JD, Wicker N, Poch O.

E N D
PipeAlign: A new tool for pretein sequence analysis http://igbmc.u-strasbg.fr/PipeAlign Plewniak F, Bianchetti L, Brelivet Y, Carles A, Chalmel F, Lecompte O, Mochel T, Moulinier L, Muller A, Muller J, Prigent V, Ripp R, Thierry JC, Thompson JD, Wicker N, Poch O. Protein sequence analysis is a key issue in post-genomic biology.High-throughput genome sequencing and assembly techniques, structuralproteomics and gene expression analysis have led to a rapidincrease in the amount of sequence, structure and functionaldata available in the public databases. In order to fully understandthe biological role of a particular protein, such diverse informationas cellular location, 2D/3D structures, mutations and theirassociated illnesses, the evolutionary context and literaturereferences must be retrieved, validated, classified and madeavailable to the biologist. The integration of the protein inthe context of the complete family is an essential first stepin the analysis process. As a consequence, a new generationof protein family analysis tools is now required to organisethis heterogeneous, often predicted data into a structured,hierarchical network of connected information. PipeAlign is a protein family analysis tool integrating a five step process ranging from the search for sequence homologues in protein and 3D structure databases to the definition of the hierarchical relationships within and between subfamilies. The complete, automatic pipeline takes a single sequence or a set of sequences as input and constructs a high-quality, validated MACS (multiple alignment of complete sequences) in which sequences are clustered into potential functional subgroups. Three main criteria were essential in the PipeAlign development process : accuracy, quality and efficiency. As a consequence, all subsequent steps described below were extensively tested on large scale datasets, such as genomes, Benchmark database, or dedicated databases. Fig.1. a) The Ungapped Segment Pairs (USPs) issued from alignments with an Expect value less than 0.1 are stacked and used to build a profile of amino-acid conservation along the query sequence. The contribution of each USP to the profile is proportional to the significance of its corresponding HSP. b) LMS’s can be considered as informative signal within a noisy background. A first step of noise reduction is taken by smoothing the raw conservation profile. Peaks are expected to indicate the presence of segments that are significantly more conserved than their background. c) In order to identify peaks, the second derivative of the smoothed profile is computed. Informative peaks corresponding to LMS’s were empirically determined to be those where the second derivative is less than –0.1. The LMS’s are presented here as boxes over the second derivative plot. d) For each database sequence return by Blast, a dynamic programming algorithm determines the optimal alignment of the USPs to the predicted LMS’s in the query sequence. The score for each USP depends upon the strength of the LMS (the area of the raw profile overlapping the LMS) and on how well the USP matches the LMS. The optimal alignment score is used to rank the sequences. This operation may be done with user selected LMS’s instead of all predicted LMS’s. Ballast is a program designed to retrieve sequences very distantly related to the query sequence. In the BlastP results, they are given a very high expect value and are therefore ranked very low. Ballast takes the reference sequence (query) and searches the Protein sequence database (SwissProt + SpTrEMBL + PDB) for homologues using BlastP. It then uses the Blast results to create a conservation profile by stacking the Blast homologous pair alignments (HSPs). Ballast extracts from this profile small conserved segments (LMSs) that may characterise the family of the query. These segments are used to rescore Blast results. DbClustal is a new version of the popular ClustalW program. This version is able to incorporate information on local matching segment pairs of sequence retrieved from a database search to obtain a multiple sequence alignment. Such information overcomes the problem of long insertions/extensions which often lead to wrong alignments using global alignment algorithm-based programs. The LMS obtained from Ballast are used in DbClustal as anchors to seed the alignment process. Anchors are not incorporated as constraints but restraints, an additional weight, depending on the frequency of the observed LMS is added in the scoring scheme when aligning two sequences. RASCAL tries then to correct potential errors remaining in the alignment. Indeed, building a multiple sequence alignment is based on a heuristic, and even if incorporation of prior information in the first steps of the alignment process helps the progressive alignment algorithm, some initial errors may remain. To find badly aligned regions, the alignment is divided horizontally by clustering the sequences into subfamilies using Secator, a program based on a phylogenetic guide tree, and vertically using a sliding window in which a MD score is computed, for the whole alignment and for each subfamily. This identifies global and family-specific ‘core block’ regions corresponding to well-aligned zones in the alignment. A refinement strategy is then used to realigned inter core block regions, starting inside each family, then in a two-by-two family step, and finally between the global core blocks. LEON has been designed to detect and remove sequences non-homologous to the query that may be present in the alignment. As multiple sequence alignments are nowadays starting points for structural prediction, functional assignment, phylogenic studies, it is crucial to validate the alignment in terms of homology coherence. Errors may have been introduced by local matches with high homology although the sequences are in fact unrelated along their whole length. Clustering the sequences in validated multiple sequence alignment will determine the hierarchical relationships existing between sequences. Subfamilies are created to which the biologist will give a particular sense in the context of his studies. Two programs are available for clustering, Secator and DPC. As they are based on two different algorithms, their results may be different, leading to different interpretations. Figure 2. Flowchart showing the four major steps of the LEON algorithm. The input to the algorithm consists of a multiple sequence alignment, in which the user has identified a reference or ‘query’ sequence. The final result is a multiple alignment in which the sequences predicted to be homologous are ranked according to their similarity to the query. Non-homologous sequences are excluded from the alignment. • Main Features of PipeAlign : • - start with a single sequence, a group of unaligned sequences or a set of aligned sequences • each step of the PipeAlign can be accessed separately • parameters of each steps can be changed according to the query characteristics • an ID is given to each session, allowing the user to check results later • - every alignments can be edited using JalView • - final and intermediate results (Blast, Ballast, alignments, groups) can be saved in several formats. • - documentation on each program and help on parameters available on-line. Figure 3.Snapshots of the PipeAlign outputs • References : • · Lecompte,O., Thompson,J.D., Plewniak,F., Thierry,J. and Poch,O. (2001) Multiple alignment of complete sequences (MACS) in the post-genomic era. Gene, 270, 17–30. • · Plewniak,F., Thompson,J.D. and Poch,O. (2000) Ballast: blast post-processing based on locally conserved segments. Bioinformatics, 9, 750–759. • · Thompson,J.D., Plewniak,F., Thierry,J. and Poch,O. (2000) DbClustal: rapid and reliable global multiple alignments of protein sequences detected by database searches. Nucleic Acids Res., 15, 2919–2926. • · Thompson,J.D., Plewniak,F., Thierry,J. and Poch,O. (2003) RASCAL: Rapid scanning and correction of multiple sequence alignment programs.Bioinformatics, 19, 1155-61. • Thompson,J.D., Plewniak,F., Ripp,R., Thierry,J.C. and Poch,O. (2001) Towards a reliable objective function for multiple sequence alignments. J. Mol. Biol., 4, 937–951. • Wicker,N., Perrin,G.R., Thierry,J.C. and Poch,O. (2001) Secator: a program for inferring protein subfamilies from phylogenetic trees. Mol. Biol. Evol., 8, 1435–1441. • Thompson, J.D., Prigent, V., Poch, O. (2004) LEON: multiple aLignment Evaluation Of Neighbours. Nucleic Acids Res.32, 1298-307. • Wicker N, Dembele D, Raffelsberger W, Poch O. (2002) Density of points clustering, application to transcriptomic data analysis.Nucleic Acids Res., 30, 3992-4000.