Download

1 / 32
320 likes | 441 Views
Optimizing Data Warehouse Loads via Parallel Pro-C and Parallel/Direct-Mode SQL. Bert Scalzo, Ph.D. Bert.Scalzo@Quest.com. About the Author. Oracle DBA from 4 through 10g Worked for Oracle Education Worked for Oracle Consulting Holds several Oracle Masters

E N D
Optimizing Data Warehouse Loads via Parallel Pro-C and Parallel/Direct-Mode SQL Bert Scalzo, Ph.D. Bert.Scalzo@Quest.com
About the Author • Oracle DBA from 4 through 10g • Worked for Oracle Education • Worked for Oracle Consulting • Holds several Oracle Masters • BS, MS and PhD in Computer Science • MBA and insurance industry designations • Articles in • Oracle Magazine • Oracle Informant • PC Week (now E-Magazine)
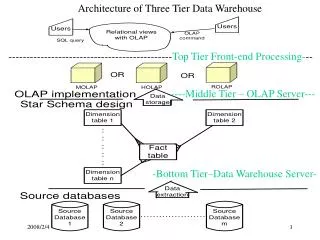
Star Schema Design “Star schema” approach to dimensional data modeling was pioneered by Ralph Kimball Dimensions: smaller, de-normalized tables containing business descriptive columns that users use to query Facts: very large tables with primary keys formed from the concatenation of related dimension table foreign key columns, and also possessing numerically additive, non-key columns used for calculations during user queries
Facts Dimensions
108th -1010th 103rd -105th
The Loading Challenge How much data would a data loader load, if a data loader could load data? Dimensions: often reloaded in their entirety, since they only have have tens to hundreds of thousands of rows Facts: must be cumulatively loaded, since they generally have hundreds of millions to billions of rows – with daily data loading requirements of 10-20 million rows or more
Hardware Won’t Compensate Often people have unrealistic expectation that using expensive hardware is only way to obtain optimal application performance • CPU • SMP • MPP • Disk IO • 15,000 RPM • RAID (EMC) • OS • UNIX • 64-bit • Oracle • OPS / PQO • 64-bit
Hardware Tuning Example • Problem: Data load runtime 4+ hours • 8 400-MHz 64-bit CPU’s • 4 Gigabytes UNIX RAM • 2 Gigabytes EMC Cache • RAID 5 (slower on writes) • Attempt #1: Bought more hardware • 16 400-MHz 64-bit CPU’s • 8 Gigabytes UNIX RAM • 4 Gigabytes EMC Cache • RAID 1 (faster on writes) • Runtime still 4+ hours !!!
Application Tuning Example • Attempt #2: Redesigned application • Convert PL/SQL to Pro-C • Run 16 streams in parallel • Better utilize UNIX capabilities • Run time = 20 minutes !!! • Attempt #3: Tuned the SQL code • Tune individual SQL statements • Use Dynamic SQL method # 2 • Prepare SQL outside loop • Execute Prep SQL in loop • Run time = 15 minutes !!!
Lesson Learned • Hardware: • Cost approximately $1,000,000 • System downtime for upgrades • Zero runtime improvement • Loss of credibility with customer • Redesign: • 4 hours DBA $150/hour = $600 • 20 hours Developer $100/hour = $2000 • Total cost = $2600 or 385 times less Golden Rule #1:Application redesign much cheaper than hardware!!!
Program Design Paramount In reality, the loading program’s design is the key factor for the fastest possible data loads into any large-scale data warehouse Data loading programs must be designed to utilize SMP/MPP architectures, otherwise CPU usage may not exceed 1 / # of CPU’s Golden Rule #2: minimize inter-process waits and maximize total concurrent CPU usage
Example Loading Problem • Hardware: • HP-9000, V2200, 16 CPU, 8 GB RAM • EMC 3700 RAID-1 with 4 GB cache • Database: • Oracle 8.1.5.0 (32 bit) • Tables partitioned by month • Indexes partitioned by month • Nightly Load: • 6000 files with 20 million detail rows • Summarize details across 3 aggregates
Original’s Physical Problems • IO Intensive: • 5 IO’s from source to destination • Wasted IO’s to copy files twice • Large Waits: • Each step dependent on predecessor • No overlapping of any load operations • Single Threaded: • No aspect of processing is parallel • Overall CPU usage less than 7%
Original’s Logical Problems • Brute Force: • Simple for programmers to visualize • Does not leverage UNIX’s strengths • Record Oriented: • Simple for programmers to code (cursors) • Does not leverage SQL’s strengths (sets) • Stupid Aggregation: • Process record #1, create aggregate record • Process record #2, update aggregate record • Repeat last step for each record being input
Process Step Start Time Duration (minutes) Cat T-000 30 Sort T-030 45 SQL Loader T-075 15 PL/SQL T-090 180 T-270 270 Original Version’s Timings CPU Utilization Glance Plus Display HP-UX 11.0 16 CPU’s
Parallel Design Options • Parallel/Direct SQL Loader: • Use Parallel, Direct option for speed • Cannot do data lookups and data scrubbing without complex pre-insert/update triggers • Multi-Threaded Pro-C: • Hard to monitor via UNIX commands • Difficult to program and hard to debug • “Divide & Conquer”: • Leverages UNIX’s key strengths • Easy to monitor via UNIX commands • Simple UNIX shell scripting exercise • Simple Pro-C programming exercise
What Are Threads? • Multithreaded applications have multiple threads, where each thread: • is a "lightweight" sub-processes • executes within the main process • shares code and data segments (i.e. address space) • has its own program counters, registers and stack • Global and static variables are common to all threads and require a mutual exclusivity mechanism to manage access to from multiple threads within the application.
main() { sql_context ctx1,ctx2; /* declare runtime contexts */ EXEC SQL ENABLE THREADS; EXEC SQL CONTEXT ALLOCATE :ctx1; EXEC SQL CONTEXT ALLOCATE :ctx2; ... /* spawn thread, execute function1 (in the thread) passing ctx1 */ thread_create(..., function1, ctx1); /* spawn thread, execute function2 (in the thread) passing ctx2 */ thread_create(..., function2, ctx2); ... EXEC SQL CONTEXT FREE :ctx1; EXEC SQL CONTEXT FREE :ctx2; ... } void function1(sql_context ctx) { EXEC SQL CONTEXT USE :ctx; /* execute executable SQL statements on runtime context ctx1!!! */ ... } void function2(sql_context ctx) { EXEC SQL CONTEXT USE :ctx; /* execute executable SQL statements on runtime context ctx2!!! */ ... } Non-Mutex Code
Step #1: Form Streams Unix shell script to form N streams (i.e. groups) of M/N data sets from M input files degree=16 file_name= ras.dltx.postrn file_count=`ll ${file_name}.* | wc -l` if [ $file_count ] then if [ -f file_list* ] then rm -f file_list* fi ls ${file_name}.* > file_list split_count=`expr \( $file_count + file_count % $degree \) / $degree` split -$split_count file_list file_list_ ### Step #2’s code goes here ### fi
Example for Step #1 files: ras.dltx.postrn.1 ras.dltx.postrn.2 ras.dltx.postrn.3 ras.dltx.postrn.4 ras.dltx.postrn.5 ras.dltx.postrn.6 ras.dltx.postrn.7 ras.dltx.postrn.8 ras.dltx.postrn.9 ras.dltx.postrn.10 ras.dltx.postrn.11 ras.dltx.postrn.12 file_list_aa: ras.dltx.postrn.1 ras.dltx.postrn.2 ras.dltx.postrn.3 ras.dltx.postrn.4 Data Set 1 file_list_ab: ras.dltx.postrn.5 ras.dltx.postrn.6 ras.dltx.postrn.7 ras.dltx.postrn.8 Data Set 2 …
Step #2: Process Streams Unix shell script to create N concurrent background processes, each handling one of the streams’ data sets for file in `ls file_list_*` do (cat $file | while read line do if [ -s $line ] then cat $line | pro_c_program fi done )& done wait
Example for Step #2 All running concurrently, with no wait states file_list_aa: ras.dltx.postrn.1 ras.dltx.postrn.2 ras.dltx.postrn.3 ras.dltx.postrn.4 file_list_ab: ras.dltx.postrn.5 ras.dltx.postrn.6 ras.dltx.postrn.7 ras.dltx.postrn.8 • for each file • skip if empty • grep file • sort file • run Pro-C • inserts data • for each file • skip if empty • grep file • sort file • run Pro-C • inserts data
Step #3: Calc Aggregations sqlplus $user_id/$user_pw@sid @daily_aggregate sqlplus $user_id/$user_pw@$sid @weekly_aggregate sqlplus $user_id/$user_pw@$sid @daily_aggregate alter session enable parallel dml; insert /*+ parallel (aggregate_table, 16) append */ into aggregate_table (period_id, location_id, product_id, vendor_id, … ) select /*+ parallel (detail_table,16 full(detail_table) ) */ period_id, location_id, product_id, vendor_id, …, sum(nvl(column_x,0)) from detail_table where period_id between $BEG_ID and $END_ID group by period_id, location_id, product_id, vendor_id;
Pro-C Program • Algorithm: • Read records from Standard IO until EOF • Perform record lookups and data scrubbing • Insert processed record into detail table • If record already exists, update instead • Commit every 1000 inserts or updates • Special Techniques: • Dynamic SQL Method #2 (15% improvement) • Prepare SQL outside record processing loop • Execute SQL inside record processing loop
Process Step Start Time Duration (minutes) Stream #1 T-000 15 Stream #… T-000 15 Stream #16 T-000 15 Aggregate T-015 10 T-25 25 “Divide & Conquer” Version’s Timings CPU Utilization Glance Plus Display HP-UX 11.0 16 CPU’s
Results Old Run Time = 270 Minutes New Run Time = 25 Minutes RT Improvement = 1080 % • Customer’s Reaction: • took team to Ranger’s baseball game • gave team a pizza party & 1/2 day off • gave entire team plaques of appreciation
Other Possible Improvements • Shell Script: • Split files based upon size to better balance load • Pro-C: • Use Pro-C host arrays for inserts/updates • Read lookup tables into process memory (PGA) • Fact Tables: • Partition tables and indexes by both time and parallel separation criteria (e.g. time zone)