Download

1 / 36
370 likes | 591 Views
Oracle Data Mining and Epidemiological Analysis. Scott A. Rappoport, OCP MTS Technologies OracleWorld 2003 San Francisco, CA. Presentation Goals. Short intros Vocabulary Present Basic Medical Terms Describe Data Mining Models and Terms Synthesize What questions are we asking?

E N D
Oracle Data Mining and Epidemiological Analysis Scott A. Rappoport, OCP MTS Technologies OracleWorld 2003 San Francisco, CA
Presentation Goals • Short intros • Vocabulary • Present Basic Medical Terms • Describe Data Mining Models and Terms • Synthesize • What questions are we asking? • Applying DM to Epidemiological issues • Demonstrate the DM4J components • The future: • Challenges • 10g features
The DM Dimension • Data Mining capability readily accessible to the end users opens a whole new dimension of what can be performed in the medicine. • New questions are being generated based on the availability of these new techniques. • This is a cutting edge (bleeding edge) advanced technique
A few disclaimers… Medical data is highly sensitive information… Thus: • No personally identifiable info is presented • No specific aggregated information on disease types, locations, or time is provided • Scaled back list of attributes in demos • However, demos will give an indicative application of the technology.
About you • What percentage of the audience: • Has a medical background? • Physician • Epidemiology/research/academic • Has an IT background? • DBA • Developer • Knows a lot about Data Mining? Statistics? • Has at least two of the above? Three?
About me • Oracle Certified DBA and Developer • ASQ Certified Quality Engineer • Principal Architect, supporting the Naval Health Research Center in San Diego, CA • Instructor of Oracle, Data Warehouse, and Web Services courses at UCSD-Extension • Papers on Java, DataWarehousing – IOUG/ODTUG • Biochemistry degree/ worked in a diagnostics firm • Son of a clinical pathologist
Let’s get at it… The Medical Side
Medical Lexicon • Epidemiology • Study of the relationships of various factors determining the frequency and outbreak of disease. • Nosocomial • Outbreaks originating within a hospital. • Nosology • Study of the classification of diseases. • ICD9/10 • International Classification of Diseases: v9 or 10. Classification of disease by major category – represented by a three-digit code, followed by a specific type, represented by a two-digit code. • DNBI: • Disease Non-Battle Injury. Military classification of disease types.
Nosology/ICD9 Disease Classification • Over 12,000 separate diseases • Classified into 13 areas • Further sub-classed • Set off by 3 digit code, then additional 2 digit descriptor for better granularity • DNBI – military designations
Epidemiological/Medical Practice Questions • What factors affect the onset of disease within a population? • What is the likelihood that a patient will require follow-up treatment, hospitalization, or that the case will worsen? • Are there particular clusters of patients that are more likely to develop a certain disease? • How often is a case mis-diagnosed? • Is a particular treatment likely to cure the ailment?
Summarizing the Concerns • Predictive concerns • Classification of risks and subjects • Attribute ranking concerns • Multi-factor relevance • Dealing with large numbers of attributes • Clustering questions • Unknown associations
Epidemiological techniques • Statistical packages • Chi-square • ANOVA / ANCOVA / MANOVA • Multi-variate Analysis (Attribute Scoring): • Multiple Logistic Regression (binomial/dichotomous) • Multiple Linear Regression (multiple/category) • Covariance • 2x2 matrix
Risk factors/classification • Environmental: exposure, location, job risks, diet • Genetic: Genetic markers present? • Clinical: Blood/other diagnostics data • Familial: Other family members? Who, what? • History: Past illnesses? What? When? How often? • Socio-economic: Job, married, education, age, gender • Lifestyle: Exercise, smoker, alcohol • Ethnic/National/Geographical
Query Technique Reporting needs Example Operational reporting Basic information on an event Find the diagnosis of patient #A1234 on this date. Ad-hoc User define queries to help understand an event Does the specific patient have a past history of such a diagnosis? OLAP Summarized data of events across many dimensions What is the incidence rate of this disease among this patient type? For this area, season, hospital, etc? Is this becoming more prevalent? Data Mining Attribute associations, predictive modeling, clustering of populations by attribute sets. Across many attributes and records What are the risk factors for this disease? What is the likelihood a treatment will succeed for a patient? What specific populations are at risk? Reporting Examples
Data Mining Techniques • Classification • Seeks to find out attributes that best predict a dependent variable • Clustering • Seeks groupings of attributes in populations • Association • What is the likelihood that event A will lead to or occur with event B, C, or D… • Attribute Importance • Ranking of attributes based on their effects on a given dependent variable • Lift Model: • Measures how well a model can identify a given target
Data Mining Terms • Confusion Matrix: • Tests model accuracy. Actual to predicted evaluated, scored by incidence of false-positives / false-negatives. • False-negative: • disease present, results not shown • False-positive: • disease not present, results show • Supervised learning: • target value is specified. Classification / regression • Unsupervised learning: • Relations/target attributes not known. Clusters/Assoc
Data Mining Terms (cont’d) • Support: • The measure of how often the collection of items in an association occur together as a percentage of all the transactions. • Confidence: • Confidence of rule "B given A" is a measure of how much more likely it is that B occurs when A has occurred. • ROC: • Receiver Operating Characteristic. Used in Lift models to determine how well the model identifies targets as opposed to random selection.
Supervised/Unsupervised Supervised Prediction odds of success • Classification • Model • Test (obtain false-positives/negatives • Apply • Lift • Attribute Importance • Determine attributes with the most effect on result • Want to split on this attribute
Supervised/Unsupervised • Unsupervised No a priori knowledge find hidden relations/ associations/ groupings • Clustering • What groups of subjects share values of attributes that are closely related? • Associations • Find events that are related; i.e., if A (and/or B) happens, what are the odds that C will happen?
Classification Modeling • Used to find a predictive model of independent attributes on the outcome of a dependent attribute • Algorithms: Naïve Bayes, Adaptive Bayes NetWork
Classification Model (cont’d) • Replaces: • Multi-variate Analysis • Multiple Logistic Regression (binomial/dichotomous) • Multiple Linear Regression (multiple/category) • Questions: • Given a set of factors, what is the likelihood that a disease will be expressed? • What is the likelihood the disease will lead to a more severe ailment? • What category (multi-option) of health based on inputs?
Classification Model: To Do’s • Create a model: Classification Build • Refine: Run an Attribute Importance Model to help define best attributes to “split” • Test the model: Classification Test • Predict results: Classification Apply • Targeting: Classification Lift
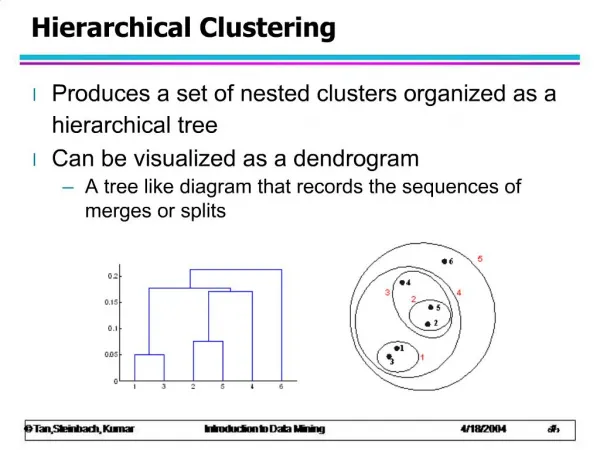
Clustering • Unsupervised model that attempts to find groups within the population that share similar attributes • Algorithm: k-means, O-Cluster Courtesy Charlie Berger, Oracle
Clustering (cont’d) • k-means only takes numeric values, and requires the number of clusters to be specified. Good for smaller datasets with fewer attributes. • O-Clusters: more robust than k-means • Questions: • What groups of people are present in a population, and what are their common attributes? • How are the members distributed along those attributes? • Are there given clusters of people related to a specific disease family? Are members more or less susceptible?
Association Models • Unsupervised model that returns a set of rules determining if one or more attributes are associated with other attributes. • Scored by support/confidence • What is the likelihood of A happening if B happens? • Often used with sparsely populated data sets. • Questions: • What is the relationship between overweight recruits, smoking, and attrition in boot camp?
Applications/Demos • Review of the parts of the process: • JDeveloper9i layout, model wizards, creation, run • ODM Browser: task review, navigation, results • Creation of models in JDeveloper9i with DM4J Wizards • Clustering Model Build and analyze histograms • Association Model Build: Analyze rules • Classification Model: Build, Test, Apply, Lift • Attribute Importance
Challenges • Most data sources have not been modeled to collect the range of data needed. • Bio-informatics opens a whole new range of study not even imagined a few years ago. • Data Stores are inconsistent. • Doctors notes are not uniform. • Legacy Apps are a mess. (COBOL, poorly documented, personnel retired…)
More challenges • Vast amounts of data/ processing • Confusion matrix on attributes with large categories. • Structuring questions “to peel away” masking factors, and be sensitive to subtle associations • Bringing it to the masses • Overcoming resistance to change.
New Native 10g Features • Text Mining – to help us search through physicians’ notes • Support Vector Machines (SVM): “Neural Networks on Steroids.” • Non-negative Matrix Factorization (NMF): Algorithm to help “boil down” many attributes into a manageable set. • Enhanced Bio-informatics support in the DB. • Transformation creation (currently alpha)
Summary • Covered a multi-disciplinary topic • Attempted to show how DM is uniquely suited to Epidemiological study • Showed the ease by which models can be made • Still, model creation requires trained personnel • Many challenges remain to fully exploit this technology.
Special Thanks to…. • Mark Kelly, Oracle Data Mining • Robert Haberstoh, Oracle Data Mining • Charlie Berger, Director Oracle Data Mining
Follow-up • Please fill out the on-line survey • Session #63144 • Feel free to contact me: Scott Rappoport, OCP Principal Technical Staff Member MTS Technologies 619-725-5082 rappoports@mtstech.com