Download

1 / 21
210 likes | 357 Views
An Unsupervised Learning Approach for Overlapping Co-clustering. Machine Learning Project Presentation Rohit Gupta and Varun Chandola {rohit,chandola}@cs.umn.edu. Outline. Introduction to Clustering Description of Application Domain From Traditional Clustering to Overlapping Co-clustering

E N D
An Unsupervised Learning Approach for Overlapping Co-clustering Machine Learning Project Presentation Rohit Gupta and Varun Chandola {rohit,chandola}@cs.umn.edu
Outline • Introduction to Clustering • Description of Application Domain • From Traditional Clustering to Overlapping Co-clustering • Current State of Art • A Frequent Itemsets Based Solution • An Alternate Minimization Based Solution • Application to Gene Expression Data • Experimental Results • Conclusions and Future Directions
Clustering • Clustering is an unsupervised machine learning technique • Uses unlabeled samples • In the simplest form – determine groups (clusters) of data objects such that the objects in one cluster are similar to each other and dissimilar to objects in other clusters • Where each data object is a set of attributes (or features) with a definite notion of proximity • Most traditional clustering algorithms • Are partitional in nature. Assign a data object to exactly one cluster • Perform clustering along one dimension
Application Domains • Gene Expression Data • Genes vs. Experimental Conditions • Find similar genes based on their expression values for different experimental conditions • Each cluster would represent a potential functional module in the organism • Text Documents Data • Documents vs. Words • Movie Recommendation Systems • Users vs. Movies
Overlapping Clustering • Also known as soft clustering, fuzzy clustering • A data object can be assigned to more than one cluster • Motivation is that many real world data sets have inherently overlapping clusters • A gene can be a part of multiple functional modules (clusters)
Co-clustering • Co-clustering is the problem of simultaneously clustering rows and columns of a data matrix • Also known as bi-clustering, subspace clustering, bi-dimensional clustering, simultaneous clustering, block clustering • The resulting clusters are blocks in the input data matrix • These blocks often represent more coherent and meaningful clusters • Only a subset of genes participate in any cellular process of interest that is active for only a subset of conditions
Overlapping Co-clustering overlaps Co-clusters Segal et al, 2003, Banerjee et al, 2005 Dhillon et al, 2003, Cho et al 2004, Banerjee et al, 2005 [Bergmann et al, 2003] Overlapping Co-clusters
Current State of Art • Traditional Clustering – Numerous algorithms like k-means • Overlapping Clustering – Probabilistic RelationalModel Based Approach by Segal et al and Banerjee et al • Co-clustering – Dhillon et al for gene expression data and document clustering. (Banerjee et al provided a general framework using a general class of Bregman distortion functions) • Overlapping co-clustering • Iterative Signature Algorithm (ISA) by Bergmann et al for gene expression data • Uses an Alternate Minimization technique • Involves thresholding after every iteration • We propose a more formal framework based on the co-clustering approach by Dhillon et al and another simpler frequent itemsets based solution
Frequent Itemsets Based Approach • Based on the concept of frequent itemsets from association analysis domain • A frequent itemset is a set of items (features) which occur together more than a specified number of times (referred to as support threshold) in the data set • The data has to be binary (only presence or absence is considered)
Frequent Itemsets Based Approach (2) • Application to gene expression data: • Normalization – first along columns (conditions) to remove scaling effects and then along rows (genes) • Binarization • Values above a preset threshold λ are set to 1 and the rest to 0. • Values above a preset percentile are set to 1 and the rest to 0. • Split each gene column to three components g+, g0 and g- signifying the up and down regulation of the gene's expression. This triples the number of items (or genes) • Gene expression matrix converted to transaction format data – each experiment is a transaction and contains index values for the genes that were expressed in this experiment
Frequent Itemsets Based Approach (3) • Algorithm: • Run closed frequent itemset algorithm to generate frequent closed itemsets with a specified support threshold σ • Post-Processing: • Prune frequent itemsets (set of genes) of length < α • For each remaining itemset, scan the transaction data to record all the transactions (experiments) in which this itemset occurs • (Note: The combination of these transactions (experiments) and the itemset (genes) will give the desired sets of genes with subsets of conditions they are most tightly co-expressed with)
Limitations of Frequent Itemsets Based Approach • Binarization of the gene expression matrix may lose some of the patterns in the data • Up-regulation and down-regulation of genes not directly taken into account • Setting up right support threshold incorporating the domain knowledge is not trivial • Large number of modules obtained – difficult to evaluate biologically • Traditional association analysis based approaches only considers dense blocks, noise may break the actual module in this case – Error tolerant Itemsets (ETI) offers a potential solution though
Alternate Minimization (AM) Based Approach • Extends the non-overlapping co-clustering approach by [Dhillon et al, 2003, Banerjee et al 2005] • Algorithm • Input: Data Matrix A (size: m x n) and k, l (# of row and column clusters) • Initialize row and column cluster mappings, X (size: m x k) and Y (size: n x l) • Random assignment of rows (or columns) to row (or column) clusters • Any traditional one dimensional clustering can be used to initialize X and Y • Objective function: ||A – Â||2, Â is matrix approximation of A computed as follows: • Each element of a co-cluster (obtained using current X and Y) is replaced by mean of co-cluster (aI,J) • Each element of a co-cluster is replaced by (ai,J + aI,j – aI,J) i.e row mean + column mean – overall mean
Alternate Minimization (AM) Based Approach(2) • While (converged) • Phase 1: • Compute row cluster prototypes (based on current X and matrix A) • Compute Bregman distance, dΦ(ri, Rr) - each row to each row cluster prototype • Compute probability with which each of m rows fall into each of k row clusters • Update row cluster X keeping column cluster Y same (some thresholding is required here to allow limited overlap) • Phase 2: • Compute column cluster prototypes (based on current Y and matrix A) • Compute Bregman distance, dΦ(cj, Cc) - each column to each column cluster prototype • Compute probability with which each of n columns fall into each of l column clusters • Update column cluster Y keeping row cluster X same • Compute objective function: ||A – Â||2 • Check convergence
Observations • Each row or column can be assigned to multiple row and column clusters respectively by certain probability based on their distances from respective cluster prototypes. This will produce overlapping co-clustering. • Maximum overlapping co-clusters that could be obtained = k x l • Initialization of X and Y can be done in multiple ways – two ways are explored in the experiments • Thresholding to control percent overlap is tricky and requires domain knowledge • Cluster Evaluation is important – internal and external • SSE, Entropy of each co-cluster • Biological evaluation using GO (Gene Ontology) for results on gene expression data
Experimental Results (1) • Frequent Itemsets Based Approach • A synthetic data set (40 X 40) Total Number of co-clusters detected = 3
Experimental Results (2) • Frequent Itemsets Based Approach • Another synthetic data set (40 X 40) Total Number of co-clusters detected = 7 All 4 blocks (in the original data set) were detected Need post-processing to eliminate unwanted co-clusters
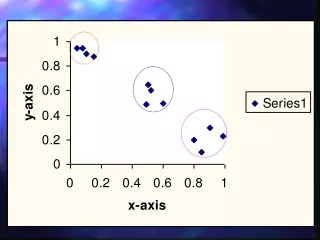
Experimental Results (3) • AM Based Approach • Synthetic data sets (20 X 20) • Finds co-clusters for each case
Experimental Results (4) • AM Based Approach on Gene Expression Dataset • Human Lymphoma Microarray Data [Described in Cho et al, 2004] • # genes = 854 • # conditions = 96 • k = 5, l = 5, one dimensional k-means for initialization of X and Y • Total Number of co-clusters = 25 Objective Function vs. Iterations Input Data A preliminary analysis of the 25 co-clusters show that only one meaningful co-cluster is obtained
Conclusions • Frequent Itemsets based approach is guaranteed to find dense overlapping co-clusters • Error Tolerant Itemset Approach offers a potential solution to address the problem of noise • AM based approach is a formal algorithm to find overlapping co-clusters • Simultaneously performs clustering in both dimensions while minimizing a global objective function • Results on synthetic data prove the correctness of the algorithm • Preliminary results on gene expression data show promise and will be further evaluated • A key insight here is that application of these techniques to gene expression data requires domain knowledge for pre-processing, initialization, thresholding as well as post-processing of the co-clusters obtained
References • [Bergmann et al, 2003] Sven Bergmann, Jan Ihmels and Naama Barkai, Iterative signature algorithm for the analysis of large-scale gene expression data, Phys. Rev. E 67, pp 31902, 2003 • [Liu et al, 2004] Jinze Liu, Paulsen Susan, Wei Wang, Andrew Nobel and Jan Prins, Mining Approximate Frequent Itemset from Noisy Data, Proc. IEEE ICDM, pp. 463-466, 2004 • [Cho et al, 2004] H. Cho, I. S. Dhillon, Y. Guan, and S. Sra, Minimum sum-squared residue co-clustering of gene expression data. In Proceedings of SIAM Data Mining Conference, pages 114-125, 2004 • [Dhillon et al, 2003] Inderjit S. Dhillon, Subramanyam Mallela and Dharmendra S. Modha, Information-Theoretic Co-Clustering, Proc. ACM SIGKDD, pp. 89-98, 2003 • [Banerjee et al, 2004] A generalized maximum entropy approach to bregman co-clustering and matrix approximation. In KDD '04: Proceedings of the 10th ACM SIGKDD, pages 509-514, 2004