Download

1 / 36
360 likes | 591 Views
Réseaux de Neurones et Apprentissage Automatique 1. Chapitre 3:. Les Réseaux de Neurones. Modèles Connectionistes ( Réseaux de Neurones ). Cerveau humain

E N D
Réseaux de Neurones et ApprentissageAutomatique1 Chapitre 3: Les Réseaux de Neurones
ModèlesConnectionistes (Réseaux de Neurones) • Cerveauhumain • Nombre de neurones: ~10-100 billion (1010 – 1011) (“There are as many neurons in the brain as there are stars in the Milky Way”; David Eagleman, Discover, 31 juillet 2007) • Connections par neurone: ~10-100 mille (104 – 105) • Temps de commutation d’1 Neurone : ~ 0.001 (10-3) seconde • Temps de reconnaissance d’une scène/image : ~0.1 second • 100 pas d’inférences pas suffisants! calculsmassivementparallèles
ModèlesConnectionistes (Réseaux de Neurones) • Définition d’un Réseau de Neurones: "... un système composé de plusieurs éléments de calcul simples fonctionnant en parallèle et dont la fonction est déterminée par la structure du réseau, les poids des connexions, et le traitement effectué sur les éléments de calcul ou nœuds." - DARPA (1988) • Propriétés des réseaux de neurones • Beaucoup d’unités semblables aux neurones; commutations basées sur des seuils • Beaucoup d'interconnexions pondérées entre les unités • Processus distribué hautement parallèle. • L'accent est mis sur le réglage automatique des poids
Quand considérer les réseaux de neurones? • Input: Haute-Dimensionalité et valeursdiscrètesouréelles • e.g., input brut provenant de capteurs • Conversion possible de donnéessymboliques en donnéesquantitatives (numériques) • Output: vecteurs à valeursdiscrètesouréelles • e.gdécisions de controle d’un actionneur de robot • Conversion possible qualitative/quantitative (symbolique/numérique) • Données: Peuvent contenir du bruit • Fonction cible: forme inconnue • Résultat: la lisibilité (pour l'homme) moins importante que la performance • Performance mesurée uniquement en termes de précision et d'efficacité • Lisibilité: la capacité d'expliquer les inférences faites à l'aide de modèles • Exemples: reconnaissance de phonèmes dans la parole; classification d’Images; Prédictions financières
Hidden-to-Output Unit Weight Map (for one hidden unit) Input-to-Hidden Unit Weight Map (for one hidden unit) Véhicule à ApprentissageAutonome avec un RN (ALVINN) • Pomerleauet al • http://www.cs.cmu.edu/afs/cs/project/alv/member/www/projects/ALVINN.html • Conduit à 110 kms/h surautoroute
Perceptron: modèled’un simple neurone • Linear Threshold Unit (LTU) or Linear Threshold Gate (LTG) (Unité à seuillinéaire) • input à l’unité: définicommecombinaisonlinéaire • Output de l’unité: fonctiond’activation à seuilselon le input (seuil=- w0) • Réseau de perceptrons • Neuronemodéliséutilisantuneunitéconnectéeà d’autresunitéspar liens pondéréswi • Multi-Layer Perceptrons(MLP) (réseau multi-couches de perceptrons) x0= 1 x1 w1 w0 x2 w2 xn wn Le Perceptron
x2 x2 + + - + - + x1 x1 - + - - ExempleA ExempleB Surface de Décision d’un Perceptron • Perceptron: peutreprésenterquelquesfonctionsutiles(And, Or, Nand, Nor) • Emulation de porteslogiques par LTU (McCulloch and Pitts, 1943) • e.g., Quelspoidsreprésententg(x1, x2) = AND(x1, x2)? OR(x1, x2)? NOT(x)? • (w0 + w1 . x1 + w2 . x2 w0 = -0.8 w1 = w2 = 0.5 w0= - 0.3 w0= 0.3 w1 = -0.5) • Quelquesfonctionsnon représentables • e.g., non linéairementséparables • Solution: utiliser un réseau de perceptrons(LTUs)
x2 + + + - + - + + - + + - - + - x1 - + - + - - - - - - - - Data SetLinéairement Séparable(LS) SéparateursLinéaires • DéfinitionFonctionnelle • f(x) = 1 siw1x1+ w2x2 + … + wnxn ; 0 sinon • : valeur du seuil • FonctionsLinéairementSéparables • Disjonctions: c(x)= x1’ x2’ … xm’ • m-de-n: c(x)= au moins 3 de (x1’ , x2’, …, xm’ ) • OuExclusif (XOR): c(x) = x1 x2 • DNF Générale : c(x) = T1 T2 … Tm; Ti = l1 l2 … lk
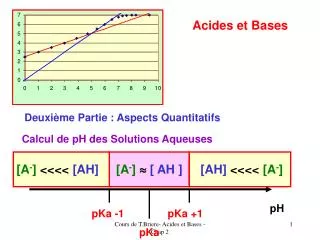
Règled’apprentissage(training rule; learning rule) • Pas spécifique à l’apprentissagesupervisé • Contexte: mise à jour de modèle • Règled’apprentissage de Hebb(1949) • Idée: si deux unités sont toutes deux actives («firing»), le poids entre elles devrait augmenter • wij= wij + r oiojoùr estuneconstante: le tauxd’apprentissage • Appuyées par des preuves neurophysiologiques • Règled’apprentissage du Perceptron (Rosenblatt, 1959) • Idée : quand une valeur cible de sortie est prévue pour un neurone pour 1 certain input, on peut progressivement mettre à jour les poids pour apprendre à produire le output désiré • Supposons LTU avec unités input/output binaires(booléennes); • oùt = c(x) est la valeurciblée en sortie, ole output du perceptron, • r uneconstantetauxd’apprentissage(e.g., 0.1) • On peutdémontrer la convergence siD estlinéairementséparableet r petit Règlesd’Apprentissage pour Perceptrons
Algorithmed’Apprentissage du Perceptron • Algorithmede descente simple par gradient • Applicable à l’apprentissage de concepts, apprentissagesymbolique • AlgorithmeTrain-Perceptron (D {<x, t(x)c(x)>}) • Initialisertous les poidswi à des valeursaléatoires • TANTQUE pas tous les exemplesprédiscorrectement FAIRE • POUR chaqueexempled’apprentissagex D • Calculer le output actuelo(x) • POUR i= 1 à n • wi wi+ r(t - o)xi// règled’apprentissage du perceptron • Apprenabilité du Perceptron (Learnability) • Rappel: peutapprendreseulementh H - i.e. fonctionslinéairementséparables • Minsky& Papert, 1969, ontdémontré les limites de la représentation • e.g., parité (XOR à nattributs: x1 x2 …xn) • e.g., symmétrie, connexitéen reconnaissance de formesvisuelle • Livre influent Perceptrons a découragé la recherchesur RNs ~10 ans
Convergence du Perceptron • Theorème de Convergence du Perceptron • Si les données sont linéairement séparables alors l'algorithme d'apprentissage du perceptron converge • Théoreme de boucle du Perceptron • Si les données d'apprentissage ne sont pas LS alors l'algorithme d’apprentissage du perceptron finira par reprendre le même ensemble de poids et entrera ainsi dans une boucle infinie • Comment améliorer la robustesse et l'expressivité? • Objectif 1: développer un algorithme qui trouvera l’ approximation la plus proche • Objectif 2: développer une architecture qui peut surmonter la limitation de la représentation
Comprendre la Descente par Gradient pour des unitéslinéaires • Soit le cas simple d’uneunitélinéaire sans seuil: • Objectif: trouver le meilleurajustement (“best fit”) à l’ensemble de donnéesD • Algorithmed’approximation • Objectifquantitatif : minimiserl’erreursurl’ensembled’apprentissageD • FonctionErreur : somme des carrés des erreurs (Sum of Squared Errors, SSE) • Comment minimiserl’erreur? • Optimisationsimple • Se déplacerdans la direction de la plus grande pente (gradient) dansl’espacepoids-erreur • Calculée en cherchant la tangente • i.e. dérivéespartielles deE par rapport aux poids (wi) Descente par Gradient : Principe
Définition: Gradient • Règled’apprentissage de descente du • gradient modifiée Descente du Gradient :Dérivation de la règle du Delta/LMS (Widrow-Hoff)
Descente du Gradient :Dérivation de la règle du Delta/LMS (Widrow-Hoff) • AlgorithmeDescente duGradient (D, r) • Chaqueexempled’app. est 1 paire de la forme<x, t(x)>, où x est le vecteur de valeursinput, t(x) est la valeur en sortie, et rtauxd’apprentissage (e.g., 0.05) • Initialisertous les poidswi à de (petites) valeursaléatoires • JUSQU’A ceque la condition de terminaisonsoitsatisfaite, FAIRE • Initialiserchaquewi à zéro • POUR chaque <x, t(x)> dansD, FAIRE • Entrerl’instancex à l’unité et calculer le output o • POUR chaquepoidswid’1 unitélinéaire, FAIRE • wi wi+ r(t - o)xi • wi wi+ wi • RETOURNER w final • Mécanique de la règle du Delta • Gradient estbasésur la dérivée • Importance: ultérieurement, nous utiliserons des fonctionsd’activationnon-linéaires(fonctions de transfert, squashing functions)
Concepts LS : Peutacheverune classification parfaite • ExempleA: la règled’apprentissage du perceptron converge • Concepts Non-LS : peuventuniquementapproximer • ExempleB: non LS; règle du delta converge, mais pas mieuxque 3 corrects • ExempleC: non LS; de meilleursrésultats avec la règle du delta • Vecteur de poidsw • Règle du Delta : minimiseerreur distance du séparateur (i.e., maximise) x2 x2 x2 + + + - + + - - + - + - + + + - + + - - - + - - x1 x1 x1 + + - + - + - - + - - - - - - - - ExempleA ExempleB ExempleC Descente du Gradient :Dérivation de la règle du Delta/LMS (Widrow-Hoff)
Descente du Gradient en Mode Batch • JUSQU’A condition determinaisonsatisfaite, FAIRE • 1. Calculer le gradient • 2. • RETOURNER w final • Descente du Gradient en Mode Incrémental (En ligne) • JUSQU’A condition de terminaisonsatisfaite, FAIRE • POUR chaquedonnée d=<x, t(x)> dansD, FAIRE • 1. Calculer le gradient • 2. • RETOURNER w final • Émulation du Mode Batch • La Descente du gradient incrémentale peut approximer la descente du gradient batch de très près si r est suffisamment petit Descente du Gradient Incrémentale (Stochastique)
Descente du Gradient: Standard vs Stochastique • Descente du Gradient • Converge vers un vecteur de poids avec erreurminimaleindépendamment du fait si D Lin. Séparableou pas, pour peuque le tauxd’apprentissage r soitsuffisamment petit. • Difficultés: • Convergence à un minimum local peutêtrelente • Pas de garantie de trouver un minimum global • Descente du Gradient Stochastiquesenséeallégercesdifficultés • Différences • En DG Standard, sommed’erreursur D avant la MAJ des poids W plus de calculs pour chaque pas de MAJ de poids(maistaille du pas plus grande par MAJ de poids) • DG stochastique: peutparfoiséviter de tombersur des minima locaux • Les 2 sontutiliséesassezsouvent en pratique
Output Layer o1 o2 v42 Hidden Layer h1 h2 h3 h4 u 11 x1 x2 x3 Input Layer RéseauxMulticouchesd’Unités non Linéaires • Unités non Linéaires • Rappel: fonctiond’activationsgn (w x) • Fonctiond’activationnonlinéaire : généralisationdesgn • RéseauxMulticouches • Type exact: Perceptrons Multi-Couches (MLPs) • Définition: 1 réseaumulticouchesfeedforward (alimentation avant) estcomposé d’1 couched’entrée, 1 ouplusieurscouches cachées, et 1 couche de sortie. • Seules les couches cachées et de sortie contiennent des perceptrons (unités à seuilou non-linéaires) • MLPs en Théorie • Réseau (2 ouplusieurs couches) peutreprésentertoutefonction avec uneerreurarbitrairement petite • Apprentissagemême d’un RéseauMulticouchesde 3-unités estNP-hard • MLPs en Pratique • Conception de réseaux de neurones pour des fonctionsarbitrairesestdifficile • Apprentissagefriand en calculsmêmequand la structure est “connue”
x0= 1 x1 w1 w0 x2 w2 xn wn Fonctionsd’Activation Non Linéaires • Fonctiond’ActivationSigmoide • FonctionLinéaired’activation à seuil: sgn(w x) • Fonctiond’activationnon linéaire (transfer, squashing) : généralisation de sgn • est la fonctionsigmoide • Pouvonsdéduire des règles de gradient pour l’apprentissage de • 1 unitésigmoide • Réseauxmulticouchesfeedforwardd’unitéssigmoides (avec backpropagation) • Fonctiond’ActivationTangenteHyperbolique
Rappel: Gradient d’1 fonctiond’erreur • Gradient Fonctiond’ActivationSigmoide • Nous savonsque: • Donc : Gradient d’Erreur pour uneUnitéSigmoide
Idée intuitive : Distribuer le blâme sur les erreurs aux couches précédentes • AlgorithmeTrain-by-Backprop (D, r) • Chaqueexempled’apprentissageestunepaire <x, t(x)>, oùx est le vecteur input et t(x) est le vecteurcible. rest le tauxd’apprentissage (e.g., 0.05) • Initialisertous les poidswi à des valeursaléatoires petites • JUSQU’A atteinte de la condition de terminaison, FAIRE • POUR chaque <x, t(x)> dansD, FAIRE • Input l’instancexà l’unité et calculer le output o(x) = (net(x)) • POUR chaqueunité output k, FAIRE (calculer sonerreur) • POUR chaqueunitécachéej, FAIRE • MAJ de chaquew= ui,j (a = hj) ouw = vj,k(a = ok) • wstart-layer, end-layer wstart-layer, end-layer + wstart-layer, end-layer • wstart-layer, end-layer r end-layeraend-layer • RETOURNER u, v Output Layer o1 o2 v42 Hidden Layer h1 h2 h3 h4 u 11 x1 x2 x3 Input Layer Algorithme de Backpropagation (propagation arrière)
Descente du Gradient en Backpropagation • Appliquée à toutes les matrices de poids du réseau • Propriété: Backpropagationsur les réseauxfeedforwardtrouvera un minimum local(pas nécessairement global) de la fonctionerreur • Backprop en pratique • L’optimisation locale donnesouvent de bonsrésultats (l’executerplusieursfois) • Souvent on inclut un momentum (élan) de poids • Apprentissagesouventtrès lent : milliersd’itérationssur D (epochs) • Inférence(appliquer le réseau après apprentissage) typiquementtrèsrapide. E.g.: Classification; Controle. Backpropagationet Optima Locaux
RNs Feedforward : Puissance de Représentation et Biais • Puissance de Représentation(i.e., Expressivité) • Backpropprésentée pour RNs feedforward à 1 couchecachée (RN 2 couches) • RN feedforward à 2 couches • Toutefonctionbooléenne • Toutefonction continue bornée(approximation avec erreurarbitrairement petite) : 1 output (unitéslinéaires sans seuil) + 1 cachée (sigmoid) • RN feedforward 3 couches: toutefonction (approximation avec erreurarbitrairement petite): output (unitéslinéaires), 2 couches cachées (sigmoides)
Apprentissage de Représentations de CoucheCachée • Unitéscachées et extraction de traits • Procédured’apprentissage: représentation de couches cachéesminimisanterreurE • Backpropdéfinitparfois de nouveaux traits (cachés) non explicitesdans la representation du input x, maiscapte les propriétés des instances input les + pertinentes à l’apprentissage de la fonctionciblet(x) • Les unitésexpriment des traits nouvellementconstruits • Fonctioncible (Sparseaka1-of-C, Codage) • RN apprend à découvrir des représentationsutiles des couches cachées
Convergence de la Backpropagation • Pas de Garantie de Convergence à 1 Solution OptimaleGlobale • Rappel: perceptronconverge à la meilleureh H, pour peuque h H; i.e., LS • Descente du gradient vers1 minimum local (peutêtre pas un minimum global) de la fonctionerreur • Améliorationspossibles de la backprop(BP) • Le terme “momentum” (variante de BP maisrègle de MAJ des poidslégèrementdifférente) • Descente du gradient stochastique(variante de l’algorithme BP) • Apprentissage de réseaux multiples avec poidsinitiauxdifférents • Nature de la Convergence • Initialiserpoids à presque zero • Réseau initial presquelinéaire • Fonctions de plus en plus non-linéaires avec l’avancée de l’apprentissage
Error vs epochs (Exemple1) Error vs epochs (Exemple2) Surapprentissage (Overtraining) des RNs • Définition de Overfitting • h’ pirequehsurDtest, meilleuresurDtrain • A cause d’itérationsexcessives • L’éviter: critèred’arrêt (cross-validation: holdout, k-fold)
Overfittingdes RNs • D’autres causes d’Overfittingsontpossibles • Nombred’unitéscachéesparfoisdécidées à l’avance • Tropd’unitéscachées • Troppeud’unitéscachées (“underfitting”) • RNs qui n’arrivent pas à progresser (“croître”) • Analogie: systèmed’équationslinéaires(plus d’inconnuesqued’équations) • Approches de Solutions • Eviter: • Ensemble Hold out cross-validation oupartage de k façons (k ways) • Weight decay: diminuerchaquepoids d’1 certain facteur à chaque iteration (epoch) • Détection/traitement: random restarts, addition et suppression de poidsoud’unités
Exemple: RN pour la Reconnaissance de Visages: la Tâche • Tâched’apprentissage: Classer des images de visages de diversespersonnesayantdifférentes poses: • 20 personnes; 32 images par personne (624 images niveauxgris, résolution de chacune 120 x 128, intensité des niveaux de gris 0 (noir) à 255 (blanc)) • expressions variables (heureux, triste, en colère, neutre) • Différentes directions (regardant à gauche, à droite, tout droit, vers le haut) • Portant des lunettes ou pas • Variation de l’arrière-plan derrière la personne • Vêtements portés par la personne • Position du visage dans l'image • Différentesfonctionsciblespeuventêtre apprises • Id de la personne; direction; genre; port de lunettes ; etc. • Dansnotrecas: apprendre la direction verslaquelle la personneregarde
Reconnaissance de Visages: Décisions de conception • Codage de l’input: • Comment coder une image? • Extraction de contours, régionsd’intensitésuniformes, autres traits locaux? • Problème: nombre variable de caractéristiques # variable d'unités d'entrée • Choix: coder l’image sur 30 x 32 valeurs d'intensité des pixels (résumé /moyennes de 120 x 128 originale ) exigences de calcul gérables Ceci est crucial en cas de ALVINN (conduite autonome) • Codage de l’Output : • Output du RN: 1 de 4 valeurs • Option1: uneunité (valeurs e.g. 0.2, 0.4, 0.6, 0.8) • Option2: codage de l’output 1-of-n (meilleure option) • Note: plutôtquevaleurs 0 et 1, 0.1 et 0.9 utilisés (unitéssigmoides ne peuventproduire output 0 et 1)
Gauche Tout droitDroite Haut Output Layer Weights (including w0 = ) after 1 Epoch Hidden Layer Weights after 25 Epochs 30 x 32 Inputs Hidden Layer Weights after 1 Epoch RN pour la Reconnaissance de Visages • Précision de 90%, Reconnaissance de visages 1-of-20 • http://www.cs.cmu.edu/~tom/faces.html
Reconnaissance de Visages: Décisions de conception • Structure du RN: Combiend’unités et comment les interconnecter • habituellement: 1 ou 2 couches d’unitéssigmoides (parfois 3). Plus quecela, apprentissagetrop lent! • Combiend’unitéscachées? De préférenceassezpeu. • E.g. avec 3 unitéscachées: 5 min apprentissage; 90% Avec 30 unitéscachées: 1 heureapprentissage; résultat à peinemeilleur • Autresparamètres d’apprentissage: Learning rate: r = 0.3; momentum α = 0.3 (sitropgrands, pas de convergence à erreur acceptable) - Descente du gradient utilisée.
Apprentissage • Poids du RN • Initialisés à de petites valeurs aléatoires • Poids d’unités d'entrée • Initialisés à 0 • Nombre d'itérations d’apprentissage • Données partitionnées en ensembles d'apprentissage et de validation • Descente du Gradient utilisée • Chaque 50 itérations, performance du RN évaluée par rapport à l’ensemble de validation • RN final: celui avec la meilleureprécision par raport à l’ens. de validation • résultat final (90%) mesurésur 3ème ens. (de tests)
RéseauxRécurrents • Représenter des séries de temps • RN Feedforward : • y(t + 1) = net (x(t)) • Besoin de capter les relations • temporelles • Approches de Solution • Cycles orientés • Feedback • Output-to-input [Jordan] • Hidden-to-input [Elman] • Input-to-input • Capte des relations dans le temps • Entre x(t’t) et y(t+ 1) • Entre y(t’t) et y(t+ 1)
Quelques Applications de RNs • Diagnostique • Les plus proches de l'apprentissage de concepts et classification • Certains RNs peuvent être post-traités pour produire des diagnostics probabilistes • Prévision et surveillance • Pronostic (prévision) • Prévoir une continuation de données (typiquement numériques) • Systèmes d'aide à la décision • Systèmes de conseils • Fournir une assistance aux experts humains dans la prise de décisions • Design (fabrication, ingénierie) • Thérapie (médecine) • Gestion des crises (médicale, économique, militaire, sécurité informatique) • Automation du Contrôle • Robots Mobiles • Capteurs et actionneurs autonomes • Et bien plus encore (Raisonnementautomatisé, etc.)