Download
1 / 5
60 likes | 182 Views
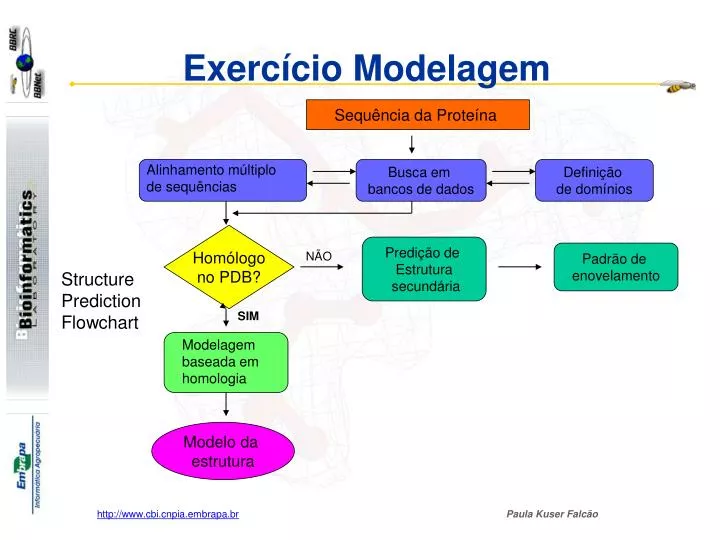
Sequência da Proteína. Alinhamento múltiplo de sequências. Busca em bancos de dados. Definição de domínios. Homólogo no PDB?. Predição de Estrutura secundária. Padrão de enovelamento. NÃO. SIM. Modelagem baseada em homologia. Modelo da estrutura. Exercício Modelagem.

E N D
Sequência da Proteína Alinhamento múltiplo de sequências Busca em bancos de dados Definição de domínios Homólogo no PDB? Predição de Estrutura secundária Padrão de enovelamento NÃO SIM Modelagem baseada em homologia Modelo da estrutura Exercício Modelagem Structure Prediction Flowchart http://www.cbi.cnpia.embrapa.br
Formato FASTA • uma linha de descrição, seguida de linhas com os dados da sequência. A linha de descrição é diferenciada da linha de sequência por um símbolo ">“ na primeira coluna. • É recomendado que todas as linhas do texto tenham 80 caracteres ou menos. >gi|532319|pir|TVFV2E|TVFV2E envelope protein ELRLRYCAPAGFALLKCNDADYDGFKTNCSNVSVVHCTNLMNTTVTTGLLLNGSYSENRTQIWQKHRTSNDSALILLNKHYNLTVTCKRPGNKTVLPVTIMAGLVFSQKYNLRLRQAWCHFPSNWKGAWKEVKEE--------IVNLPKERYRGTNDPK RIFFQRQWGDPETANLWFNCHGEFFYCKMDWFLNYLNNLTVDADHNECKNTSG TKSGNKRAPGPCVQRTYVACHIRSVIIWLETISKKTYAPPREGHLECTSTVTGMTVELNYIPKNRTNVTLSPQIESIWAAELDRYKLVEITPIGFAPTEVRRYTGGHERQKRVPFVXXXXXXXXXXXXXXXXXXXXXXVQSQHLLAGILQQQKNLLAAVEAQQQMLKLTIWGVK http://www.cbi.cnpia.embrapa.br
Formato PIR • 1. Uma linha começando com: • um sinal ">" (maior que) seguido por • Um código de duas letras descrevendo o tipo de sequência (P1, F1, DL, DC, RL, RC, or XX), seguido de • Ponto e vírgulo, seguido de • Código de identififcação da sequência. • 2. Uma linha contendo uma descrição textual da sequência. • 3. Uma ou mais linhas contendo a sequência. O fim da sequência é marcado por um asterisco (*) >P1;CRAB_ANAPL ALPHA CRYSTALLIN B CHAIN (ALPHA(B)-CRYSTALLIN). MDITIHNPLI RRPLFSWLAP SRIFDQIFGE HLQESELLPA SPSLSPFLMR SPIFRMPSWL ETGLSEMRLE KDKFSVNLDV KHFSPEELKV KVLGDMVEIH GKHEERQDEH GFIAREFNRK YRIPADVDPL TITSSLSLDG VLTVSAPRKQ SDVPERSIPI TREEKPAIAG AQRK* http://www.cbi.cnpia.embrapa.br
Busca por Homologia em Bancos de Dados • Exercício • Abrir o arquivo texto com a sequência inicial em formato fasta. • Abrir em Softwares o programa PsiBlast, e fazer uma busca por homologia da sequência inicial contra o banco de estruturas de proteínas. Clique com o mouse no campo “Enter sequence below”. Use o mouse para destacar a sequência no arquivo texto. Colocar a sequência no Blast fazendo copy & paste . http://www.cbi.cnpia.embrapa.br
Alinhamento - Clustal • Abrir o programa ClustalX. • Obter as sequências dos 5 melhores hits do alinhamento e colocar num arquivo. • Em ClustalX – Load Sequences, selecionar o arquivo onde estão as sequências. • O resultado do alinhamento das sequências deve ser avaliado manualmente. http://www.cbi.cnpia.embrapa.br