Download

1 / 34
340 likes | 411 Views
Reliable All-Pairs Evolving Fuzzy Classifiers. Edwin Lughofer and Oliver Buchtala IEEE TRANSACTIONS ON FUZZY SYSTEMS, VOL. 21, NO. 4, AUGUST 2013. Outline. CLASSIFIER STRUCTURE TRAINING PHASE CLASSIFICATION PHASE Experiment. CLASSIFIER STRUCTURE.

E N D
Reliable All-Pairs Evolving Fuzzy Classifiers Edwin Lughofer and Oliver Buchtala IEEE TRANSACTIONS ON FUZZY SYSTEMS, VOL. 21, NO. 4, AUGUST 2013
Outline • CLASSIFIER STRUCTURE • TRAINING PHASE • CLASSIFICATION PHASE • Experiment
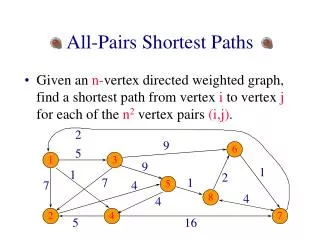
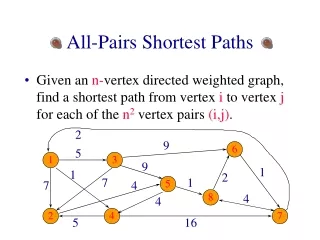
CLASSIFIER STRUCTURE • is the degree of preference of class k over classl (The degree lies in [0, 1]) • = 1 −
CLASSIFIER STRUCTURE K(K − 1) binary classifiers • is a classifier to separate samples that belong to class k from those that belong to class l • is a training data • L() being the class label associated with feature vector
CLASSIFIER STRUCTURE • In this paper, we are concentrating on two fuzzy classification architectures: • singleton class labels • regression-based classifiers
Singleton Class Labels • being the jth membership function (fuzzy set) of the ithrule • is the crisp output class label from the set of two classes (The degree is {0, 1})
TRAINING PHASE • Input(training data): (n) = ( (1) , y(1) ) , ( (2) , y(2) ) ,....,( (n) , y(n) ) y(n) containing the class labels as integer values in {0, . . . , K − 1}
TRAINING PHASE For each input sample s(n) = (x(n), y(n)) Do Obtain class label L = y(n) For k = 1, . . . , L − 1, call (upd) For k = L + 1, . . . , K call (upd) End For
TRAINING PHASE UpdateBinaryClassifier: input:, y = 1(if belongs to class k, y=0) If= ∅ Set first cluster center to current sample () Set =with> 0 (be a very small value) Set the number of rules: C = 1 Set the number of samples: = 1. Set a matrix H: = 1 (there are one input belong to class L) = 0 (there are no input belong to class k) y={1,0}
TRAINING PHASE input (new center)
TRAINING PHASE Else Find the value of win: Abeing a distance metric Ifthe distance( ) is larger than ρ: Set the number of rules: C = C+1 Set new cluster center: Set the number of samples: = 1 Set =with > 0 ( be a very small value) Update the matrix H: = 1 (there are one input belong to class L) = 0 (there are no input belong to class k)
TRAINING PHASE Cluster 1 input class k class L center
TRAINING PHASE Ifthe distance( ) is smaller than ρ: Update old center (): ( ) Update range of influence(): (Δc = (new) - (old) ) Update the matrix H: = + 1 Update the number of samples: = + 1
TRAINING PHASE Cluster 1 input class k class L center
TRAINING PHASE Cluster 1 input class k class L center
TRAINING PHASE Cluster 1 input class k class L center
TRAINING PHASE • Project updated/new cluster to axes to form Gaussian fuzzy sets and antecedent parts of rules: • a) one cluster corresponds to one rule; • b) each cluster center coordinate of the ith cluster ( , j = 1, . . . , p) corresponds to a center of a fuzzy set (, j = 1, . . . , p) appearing in the antecedent part of the rule; • c) the length of each cluster axis of the ith cluster corresponds to the width of a fuzzy set ( , j = 1, . . . , p)
TRAINING PHASE j = 1,2,3,……..,p
CLASSIFICATION PHASE • The classification outputs are produced in two stages. • 1) The first stage produces the output confidence levels (preferences) for each class pair and stores it in the preference relation matrix • 2) The second stage uses the whole information of the preference matrix and produces a final class response.
CLASSIFICATION PHASE belongs to the nearest rule that supports class k belongs to the nearest rule that supports class l is the membership degree of the current sample to the nearest rule that supports class k is the membership degree of the current sample to the nearest rule that supports class k ( T denoting a t-norm )
CLASSIFICATION PHASE => [0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2]=2.0 [0.8 0.0 0.0 0.0 0.0 0.8 0.0 0.0 0.0 0.0]=1.6 ……… output
Regression-Based Classifiers • being the jth membership function (fuzzy set) of the ithrule
TRAINING PHASE • Input(training data): (n) = ( (1) , y(1) ) , ( (2) , y(2) ) ,....,( (n) , y(n) ) y(n) containing the class labels as integer values in {0, . . . , K − 1}
TRAINING PHASE For each input sample s(n) = (x(n), y(n)) Do Obtain class label L = y(n) For k = 1, . . . , L − 1, call (upd) For k = L + 1, . . . , K call (upd) End For
TRAINING PHASE UpdateBinaryClassifier: input:, y = 1(if belongs to class k, y=0) If= ∅ Set first cluster center to current sample () Set =with> 0 (be a very small value) Set the number of rules: C = 1 Set the number of samples: = 1 Set the wight : = Set the weighted inverse Hessian matrix:= αI
TRAINING PHASE Else Find the value of win: Abeing a distance metric Ifthe distance( ) is larger than ρ: Set the number of rules: C = C+1 Set new cluster center: Set the number of samples: = 1. Set =with > 0 ( be a very small value) Set the wight : = Set the weighted inverse Hessian matrix: = αI
TRAINING PHASE Ifthe distance( ) is smaller than ρ: Update the wight(): being the normalized membership function value for the (N + 1)th data sample = Update weighted inverse Hessian matrix(): Update the number of samples: = + 1
TRAINING PHASE j = 1,2,3,……..,p
CLASSIFICATION PHASE For : For : y(k,l)= If is lying outside the interval [0,1],we round it toward the nearest integer in {0, 1}
CLASSIFICATION PHASE ……… output
Ignorance • Ignorance belongs to that part of classifier’s uncertainty that is due to a query point falling into the extrapolation region of the feature space
Ignorance IF then