Download

1 / 53
530 likes | 660 Views
Network Layer: Inside Routers. UIUC CS438: Communication Networks Summer 2014 Fred Douglas Slides: Fred , Kurose&Ross (some edited), Caesar&many others (also edited). high-seed switching fabric. Router architecture overview. two key router functions:

E N D
Network Layer: Inside Routers UIUC CS438: Communication Networks Summer 2014 Fred Douglas Slides: Fred, Kurose&Ross(some edited), Caesar&many others (also edited)
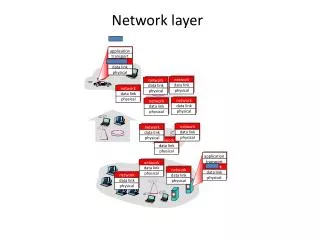
high-seed switching fabric Router architecture overview two key router functions: • run routing algorithms/protocol (RIP, OSPF, BGP) • forwarding datagrams from incoming to outgoing link forwarding tables computed, pushed to input ports routing processor routing, management control plane (software) forwarding data plane (hardware) router input ports router output ports
Function division input interface output interface • Input interfaces: • Must perform packet forwarding – need to know to which output interface to send packets • May enqueue packets and perform scheduling • Output interfaces: • May enqueue packets and perform scheduling Inter- connection Medium (Backplane) C RI RO B C
Input port functions lookup, forwarding queueing decentralized switching: • given datagram dest., lookup output port using forwarding table in input port memory (“match plus action”) • goal: complete input port processing at ‘line speed’ • queuing: if datagrams arrive faster than forwarding rate into switch fabric link layer protocol (receive) switch fabric line termination physical layer: bit-level reception (decode analog signals) data link layer: e.g., Ethernet see chapter 5
Generic Switching Fabric input interface output interface • Input and output interfaces are connected through a backplane • Backplane can be implemented by • Shared memory • Low capacity (e.g. PC-based) routers • Shared bus • Medium capacity routers • Point-to-point (switched) bus • High capacity routers Inter- connection Medium (Backplane) memory switched fabric (example: crossbar) bus memory
output port (e.g., Ethernet) input port (e.g., Ethernet) memory system bus Switching via memory first generation routers: • traditional computers • switching logic done by generic CPU • packet copied to system’s memory • speed limited by memory bandwidth • (2 bus crossings per datagram)
Switching via a bus • datagram from input port memory to output port memory via a shared bus • bus contention: switching speed limited by bus bandwidth • 32 Gbps bus, Cisco 5600: sufficient speed for access and enterprise routers bus
crossbar Switching via interconnection network • overcome bus bandwidth limitations • Clos, banyan networks, crossbar, other interconnection nets • initially developed to connect • processors in multiprocessor • telephone system • fragment datagram into fixed length cells, switch cells through the fabric. • Examples: • Cisco 12000: 60 Gbpsfabric (and this is outdated!) • Minimal Cisco CRS-3 configuration: 1.12Tbps • Juniper T4000: 4Tbps • …and these can be scaled to “multi-chassis” configurations!
Output Port Output Port Output Port Output Port Crossbar Switch • Every input port is connected to every output port • Complexity scales as O(N2) Input Port Input Port Input Port Input Port
Knockout Switch • Full crossbar requires each output port to handle up to N input packets • N input ports simultaneously sending to the same output is unlikely, especially in a large switch • Instead, let’s implement each port to handle L<N packets at the same time • Hard issue: what value of L to use?
Knockout switch • Components: • Packet filters (recognize packets destined for given output port) • Concentrator (selects L of those packets, “knocks out” others) • Output queue with capacity L packets
Knockout switch • Want some fairness (no starvation) • no input should have its packets always “knocked out” • A “knock out” tournament of 1v1(packet) games • Winners chosen randomly • Overall winners are selected by playing log N rounds, and keeping the L packets with most “wins” • Visual intuition: A win moves you “left” one space, a loss moves you “right”. Run the tournament, and keep the “leftmost” L packets.
Knockout switch • Pick L from N packets at a port • Output port maintains L cyclic buffers • Shifter places up to L packets in one cycle • (The tournament winners) • Each buffer gets at most one packet • Output port uses round-robin between buffers • Arrival order is maintained • Output ports scale as O(N)
1 2 3 4 1 4 3 2 2 Discard 4 3 1 3 Discard 4 1 Knockout Switch Choose L of N Ex: 2 of 4 R R 2x2 random selector R Output port logic R R What happens if more than L arrive? D R Delay unit D To the 2 output buffers
Self-Routing Fabrics • Idea • Use source routing on the “network” inside the switch • Source routing – packets have entire path specified in header • In this case: • Input port attaches output port number as header • Fabric designed so that input+output port# uniquely determine path • Our example: Batcher-Banyan Network
Banyan Network • A network of 2x2 switches • Each element routes to output 0 or 1 based on packet header • A switching element at stage i looks at bit i in the header 0 00100 1
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 Banyan Network 101 101 101 101
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 001 001 001 001 011 011 011 011 110 110 110 111 111 111 110 111 Banyan Network 001 011 110 111
Banyan Network • Perfect Shuffle • N inputs requires log2N stages of N/2 switching elements • Complexity on order of N log2N • Collisions • If two packets arrive at the same switch destined for the same output port, a collision will occur • If all packets are sorted in ascending order upon arrival to a banyan network, no collisions will occur!
0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 001 001 001 001 011 Collision! Happens because input is unsorted 110 110 110 111 110 Collision in a Banyan Network 001 011 110 010
U D Batcher Network • Performs merge sort • A network of 2x2 switches • Each element routes to output 0 or 1 based on packet header • A switch at stage i looks at the whole header • Two types of switches • Up switch • Sends higher number to top output (0) • Down switch • Sends higher number to bottom output (1)
7 3 3 3 3 1 3 6 6 1 3 7 6 7 1 6 6 6 1 1 1 7 7 7 Merge Merge Batcher Network D D D U D D Sort
Sort inputs 0 – 3 in ascending order Merge 0 – 3 with 4 – 7 8x8 Switch Sort inputs 4 – 7 in descending order Batcher Network D D D D D D U D D D D D D U U D D D U U U D D D
Batcher Network • How it really works • Merger is presented with a pair of sorted lists, one in ascending order, one in descending order • First stage of merger sends packets to the correct half of the network • Second stage sends them to the correct quarter • Size • N/2 switches per stage • log2N x (1 + log2N)/2 stages • Complexity = N log22N
Batcher-Banyan Network • Recall: sorted inputs to banyan no collision • Batcher sorts, so……. • Feed batcher into banyan! • Arbitrary unique permutations can be routed without collisions
datagram buffer queueing “This slide is HUGELY important!” -Kurose&Ross Output ports • buffering required when datagrams arrive from fabric faster than transmission rate • Packets drop if not enough buffer space • scheduling discipline chooses among queued datagrams for transmission • Can go for fairness, or favor some flows (QoS) switch fabric line termination link layer protocol (send)
switch fabric switch fabric one packet time later at t, packets more from input to output Output port queueing • buffering when arrival rate via switch exceeds output line speed • output port buffer overflow queueing(delay) and loss!
switch fabric one packet time later: green packet experiences HOL blocking Input port queuing • fabric slower than input ports combined -> queueing may occur at input queues • queueing delay and loss due to input buffer overflow! • Head-of-the-Line (HOL) blocking: queued datagram at front of queue prevents others in queue from moving forward switch fabric output port contention: only one red datagram can be transferred.lower red packet is blocked
What’s so hard about IP packet forwarding? • Back-of-the-envelope numbers • Line cards can be 40 Gbps today (OC-768) • Getting faster every year! • To handle minimum-sized packets (~40b) • 125 Mpps, or 8ns per packet • Can use parallelism, but need to be careful about reordering • For each packet, you must • Do a routing lookup (where to send it) • Schedule the crossbar • Maybe buffer, maybe QoS, maybe ACLs,…
Routing lookups • Routing tables: 200,000 to 1M entries • Router must be able to handle routing table loads 5-10 years hence • How can we store routing state? • What kind of memory to use? • How can we quickly lookup with increasingly large routing tables?
Memory technologies • Vendors moved from DRAM (1980s) to SRAM (1990s) to TCAM (2000s) • Vendors are now moving back to SRAM and parallel banks of DRAM due to power/heat
Ethernet Switch • Lookup frame DA in forwarding table. • If known, forward to correct port. • If unknown, broadcast to all ports. • Learn SA of incoming frame. • Forward frame to outgoing interface. • Transmit frame onto link. • How to do this quickly? • Need to determine next hop quickly • Would like to do so without reducing line rates
Inside a switch Ethernet 1 • Packet received from upper Ethernet • Ethernet chip extracts source address S, stored in shared memory, in receive queue • Ethernet chips set in “promiscuous mode” • Extracts destination address D, given to lookup engine Ethernet chip Lookup engine Processor Packet/lookup memory Ethernet chip Ethernet 2
F0:4D:A2:3A:31:9C Eth 1 00:21:9B:77:F2:65 Eth 2 8B:01:54:A2:78:9C Eth 1 00:0C:F1:56:98:AD Eth 1 00:B0:D0:86:BB:F7 Eth 2 00:A0:C9:14:C8:29 Eth 2 90:03:BA:26:01:B0 Eth 2 00:0C:29:A8:D0:FA Eth 1 00:10:7F:00:0D:B7 Eth 2 Inside a switch Ethernet 1 • Lookup engine looks up D in database stored in memory • If destination is on upper Ethernet: set packet buffer pointer to free queue • If destination is on lower Ethernet: set packet buffer pointer to transmit queue of the lower Ethernet • How to do the lookup quickly? Ethernet chip Lookup engine Processor Packet/lookup memory Ethernet chip Ethernet 2
Problem overview F0:4D:A2:3A:31:9C Eth 1 00:21:9B:77:F2:65 Eth 2 8B:01:54:A2:78:9C Eth 1 00:0C:F1:56:98:AD Eth 1 00:B0:D0:86:BB:F7 Eth 2 00:A0:C9:14:C8:29 Eth 2 90:03:BA:26:01:B0 Eth 2 00:0C:29:A8:D0:FA Eth 1 00:10:7F:00:0D:B7 Eth 2 • Goal: given address, look up outbound interface • Do this quickly (few instructions/low circuit complexity) • Linear search too low 90:03:BA:26:01:B0 Eth 2
Idea #1: binary search F0:4D:A2:3A:31:9C Eth 1 00:21:9B:77:F2:65 Eth 2 8B:01:54:A2:78:9C Eth 1 00:0C:F1:56:98:AD Eth 1 00:B0:D0:86:BB:F7 Eth 2 00:A0:C9:14:C8:29 Eth 2 90:03:BA:26:01:B0 Eth 2 00:0C:29:A8:D0:FA Eth 1 00:10:7F:00:0D:B7 Eth 2 00:0C:F1:56:98:AD Eth 1 00:10:7F:00:0D:B7 Eth 2 00:21:9B:77:F2:65 Eth 2 00:B0:D0:86:BB:F7 Eth 2 00:A0:C9:14:C8:29 Eth 2 00:0C:29:A8:D0:FA Eth 1 8B:01:54:A2:78:9C Eth 1 90:03:BA:26:01:B0 Eth 2 F0:4D:A2:3A:31:9C Eth 1 • Put all destinations in a list, sort them, binary search • Problem: logarithmic time 90:03:BA:26:01:B0 Eth 2
Improvement: Parallel Binary search 8B:01:54:A2:78:9C F0:4D:A2:3A:31:9C 00:10:7F:00:0D:B7 • Packets still have O(log n) delay, but can process O(log n) packets in parallel O(1) 00:A0:C9:14:C8:29 00:21:9B:77:F2:65 8B:01:54:A2:78:9C 00:10:7F:00:0D:B7 00:B0:D0:86:BB:F7 00:0C:29:A8:D0:FA 90:03:BA:26:01:B0 00:0C:F1:56:98:AD 00:10:7F:00:0D:B7 00:21:9B:77:F2:65 00:B0:D0:86:BB:F7 00:A0:C9:14:C8:29 00:0C:29:A8:D0:FA 8B:01:54:A2:78:9C 90:03:BA:26:01:B0 F0:4D:A2:3A:31:9C
Improvement: Parallel Binary search 8B:01:54:A2:78:9C F0:4D:A2:3A:31:9C 00:10:7F:00:0D:B7 • Packets still have O(log n) delay, but can process O(log n) packets in parallel O(1) 00:A0:C9:14:C8:29 00:21:9B:77:F2:65 8B:01:54:A2:78:9C 00:10:7F:00:0D:B7 00:B0:D0:86:BB:F7 00:0C:29:A8:D0:FA 90:03:BA:26:01:B0 00:0C:F1:56:98:AD 00:10:7F:00:0D:B7 00:21:9B:77:F2:65 00:B0:D0:86:BB:F7 00:A0:C9:14:C8:29 00:0C:29:A8:D0:FA 8B:01:54:A2:78:9C 90:03:BA:26:01:B0 F0:4D:A2:3A:31:9C
01 02 04 Idea #2: hashing keys function hashes bins F0:4D:A2:3A:31:9C • Hash key=destination, value=interface pairs • Lookup in O(1) with hash • Problem: chaining (not really O(1)) 00 8B:01:54:A2:78:9C 00:21:9B:77:F2:65 01 F0:4D:A2:3A:31:9C 8B:01:54:A2:78:9C 90:03:BA:26:01:B0 02 00:0C:29:A8:D0:FA 00:10:7F:00:0D:B7 00:0C:F1:56:98:AD 03 00:B0:D0:86:BB:F7 04 00:21:9B:77:F2:65 00:A0:C9:14:C8:29 05 90:03:BA:26:01:B0 90:03:BA:26:01:B0 00:B0:D0:86:BB:F7 ... 00:A0:C9:14:C8:29 00:0C:29:A8:D0:FA 00:0C:F1:56:98:AD 08 00:10:7F:00:0D:B7
01 02 04 Improvement: Perfect hashing parameter keys hashes bins F0:4D:A2:3A:31:9C • Perfect hashing: find a hash function that maps perfectly with no collisions • Gigaswitch approach • Use a parameterized hash function • Precompute hash function to bound worst case number of collisions 00 8B:01:54:A2:78:9C 00:21:9B:77:F2:65 01 F0:4D:A2:3A:31:9C 8B:01:54:A2:78:9C 90:03:BA:26:01:B0 02 00:0C:29:A8:D0:FA 00:10:7F:00:0D:B7 00:0C:F1:56:98:AD 03 00:B0:D0:86:BB:F7 04 00:21:9B:77:F2:65 00:A0:C9:14:C8:29 05 90:03:BA:26:01:B0 90:03:BA:26:01:B0 00:B0:D0:86:BB:F7 ... 00:A0:C9:14:C8:29 00:0C:29:A8:D0:FA 00:0C:F1:56:98:AD 08 00:10:7F:00:0D:B7
Longest Prefix Match • Not just one entry that matches a destination • 128.174.252.0/24 and 128.174.0.0/16 • Which one to use for 128.174.252.14? • By convention, Internet routers choose the longest (most-specific) match • Need variable prefix match algorithms • Several methods
Method 1: Trie Trie Sample Database • P1=10* • P2=111* • P3=11001* • P4=1* • P5=0* • P6=1000* • P7=100000* • P8=1000000* • Tree of (left ptr, right ptr) data structures • May be stored in SRAM/DRAM • Lookup performed by traversing sequence of pointers • Lookup time O(log N) where N is # prefixes
Improvement on 1: Multi-way tree 16-ary Search Trie • Doing multiple comparisons per cycle accelerates lookup • Can do this for free to the width of CPU word (modern CPUs process multiple bits per cycle) • But increases wasted space (more unused pointers) 0000, ptr 1111, ptr 1111, ptr 0000, 0 1111, ptr 0000, 0 000011110000 111111111111
Improvement on 1: Multi-way tree Table produced from 215 randomly generated 48-bit addresses
Method 2: Use a Really Big Array Number Prefix length • Observation: most prefixes are /24 or shorter • So, just store a big 2^24 table with next hop for each prefix • Nonexistant prefixes just leave that entry empty
1 Next Hop 24 Method 2: Use a Really Big Array 224 = 16M entries Prefixes up to 24-bits 142.19.6 Next Hop 142.19.6 142.19.6.14 14