Download

1 / 90
910 likes | 1.14k Views
HUMAN GENOME. Dr. ANIL KUMAR Officer-Incharge, Bioinformatic Sub Centre & Prof. & Head, School of Biotechnology DEVI AHILYA UNIVERSITY KHANDWA RD. CAMPUS INDORE-452017 INDIA.

E N D
HUMAN GENOME Dr. ANIL KUMAR Officer-Incharge, Bioinformatic Sub Centre & Prof. & Head, School of Biotechnology DEVI AHILYA UNIVERSITY KHANDWA RD. CAMPUS INDORE-452017 INDIA
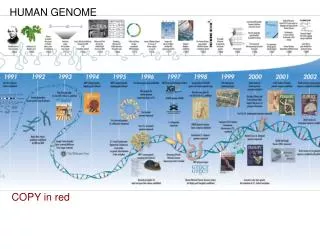
IN DEC. 1984- DURING A WORKSHOP ON CURRENT STATE OF MUTATION DETECTION AND CHARACTERIZATION AND TO PROJECT FUTURE DIRECTIONS FOR TECHNOLOGIES TO TACKLE THE PREVAILING TECHNICAL LIMITATIONS, SCIENTISTS DISCUSSED ABOUT THE HUMAN GENOME ANALYSIS AND THIS WAS THE FIRST STEP TOWARDS NUCLEOTIDE SEQUENCING OF THE ENTIRE HUMAN GENOME. THIS WORKSHOP WAS BEING SPONSORED BY THE US DEPT. OF ENERGY.
IN THE WORKSHOP, GROWING ROLES OF EXISTING DNA TECHNOLOGIES ESPECIALLY THE EMERGING GENE CLONING AND SEQUENCING TECHNOLOGIES WERE DISCUSSED. IT WAS REALIZED THAT EXISTING TECHNOLOGIES ARE IN USE SINCE A DECADE AND MOSTLY INDIVIDUAL SCIENTISTS ARE ENGAGED IN CLONING AND CHARACTERIZATION OF SINGLE GENES WHICH LOOKED TO BE WASTEFUL OF HUMAN AND RESEARCH RESOURCES.
IT WAS ALSO DEBATED THAT SUCH METHODOLOGIES WERE INCAPABLE OF DETERMINING MUTATIONS WITH GOOD SENSITIVITY. AN EXHAUSTIVE, COMPLEX, EXPANSIVE PROJECT FOR COMPLETE NUCLEOTIDE SEQUENCING OF THE HUMAN GENOME SHOULD BE UNDERTAKEN.
SUBSEQUENTLY, A REPORT ON TECHNOLOGIES FOR DETECTING HERITABLE MUTATIONS IN HUMAN BEINGS INITIATED THE IDEA FOR A DEDICATED HUMAN GENOME PROJECT BY US DEPT. OF ENERGY (UAE). • IN 1986- DAE SPONSORED AN INTERNATIONAL MEETING IN MEXICO TO ASSESS THE DESIRABILITY AND FEASIBILITY OF ORDERING AND SEQUENCING DNA CLONES REPRESENTING THE ENTIRE HUMAN GENOME.
DAE SET THREE MAJOR OBJECTIVES • GENERATION OF REFINED PHYSICAL MAPS OF HUMAN CHROMOSOMES • DEVELOPMENT OF SUPPORT TECHNOLOGIES AND FACILITIES FOR HUMAN GENOME RESEARCH • EXPANSION OF COMMUNICATION NETWORKS AND OF COMPUTATIONAL AND DATABASE CAPABILITIES • OTHER US ORGANIZATIONS ALSO INITIATED THEIR OWN STUDIES
IN 1988- WITH SUPPORT FROM US OFFICE OF TECHNOLOGY ASSESSMENT AND NATIONAL RESEARCH COUNCIL & NIH, OFFICE OF HUMAN GENOME RESEARCH WAS SET UP. LATER RENAMED AS NATIONAL CENTER FOR HUMAN GENOME RESEARCH. • IN 1988- US CONGRESS APPROVED $ 3 BILLION FOR THE PROJECT AND TIME LIMIT 15 YEARS COMMENCING FROM 1991.
DOE FUNDED NO. OF LABS LIKE LAWRENCE BERKELEY NATIONAL LAB, LOS ALAMOS NATIONAL LAB, LAWRENCE LIVERMORE NATIONAL LAB. • THEREAFTER, EUROPIAN COUNTRIES LIKE GERMANY, FRANCE, ITALY, DENMARK, THE NETHERLANDS, UK ALSO STARTED THE PROJECTS. • OTHER COUNTRIES LIKE AUSTRALIA, CANADA, JAPAN, KOREA, NEW ZEALAND ALSO STARTED THE PROJECTS. THAT’S WAY, IT REALLY BECAME AN INTERNATIONAL PROJECT.
LATER, HUMAN GENOME ORGANIZATION WAS ESTABLISHED TO COORDINATE THE DIFFERENT NATIONAL EFFORTS, FACILITATE EXCHANGE OF RESEARCH DATA, PUBLIC DEBATE etc. THREE CENTERS OF HUMAN GENOME ORGANIZATION (HUGO) WERE ESTABLISHED : • HUGO EUROPE ( LONDON) • HUGO AMERICAS ( BETHESDA) • HUGO PACIFIC ( TOKYO)
SCIENTISTS ASSOCIATED WITH PUBLIC HUMAN GENOME PROJECT & CELERA GENOMICS PUBLISHED SEQUENCES OF GENOME DNA IN HUMAN NATURE ( Feb. 15, 2001) ; SCIENCE (Feb. 16,2001) www.ornl.gov/hgmis/project/journals/journals.html
SEQUENCE IS MAGNIFICANT AND UNPRECEDENTED RESOURCE AND IS BASIS FOR RESEARCH AND DISCOVERY THROUGHOUT THIS CENTURY AND BEYOND. • IT WILL HAVE DIVERSE PRACTICAL APPLICATIONS AND IMPACT UPON HOW WE FEEL OURSELVES AND OUR PLACE IN THE TAPESTRY OF LIFE AROUND US.
AFTER THE SEQUENCE, ESTIMATED GENES ARE NEARLY 30,000 to 35,000- MUCH LESS NUMBER THAN ESTIMATED EARLIER ( NEARLY 100,000 OR EVEN MORE.
IT IS SUGGESTED THAT GENETIC KEY TO HUMAN COMPLEXITY IS NOT IN NUMBER OF GENES BUT IS , HOW GENE PARTS ARE TRANSLATED TO SYNTHESIZE DIFFERENT PROTEIN PRODUCTS. THERE IS ONE PHENOMENA CALLED AS ALTERNATE SPLICING. BESIDES, THOUSANDS OF POST TRANSLATIONAL CHEMICAL MODIFICATIONS MADE TO PROTEINS AND REGULATORY MECHANISMS CONTROLLING THESE PROCESSES ADD TO COMPLEXITY.
IN CONSTRUCTING THE SEQUENCE DRAFT, 16 GENOME SEQUENCING CENTERS PRODUCED OVER 22.1 BILLION BASES OF RAW SEQUENCE DATA, COMPRIZING OVERLAPPING FRAGMENTS TOTALING 3.9 BILLION BASES. THE SEQUENCES ARE SEQUENCED SEVEN TIMES. OVER 30% DATA IS HIGH QUALITY, FINISHED SEQUENCE WITH EIGHT TO TEN FOLD COVERAGE, 99.99% ACCURACY AND FEW GAPS. ALL DATA ARE FREELY AVAILABLE VIA THE WEB (www.ornl.gov/hgmis/project/journals/sequencesites.html)
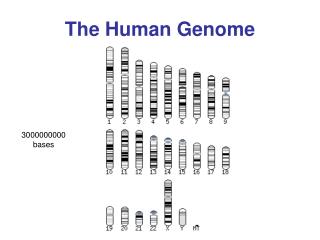
HIGHLIGHTS OF THE SEQUENCE • HUMAN GENOME CONTAINS 3164.7 MILLION NUCLEOTIDES • AVERAGE GENE HAS 3000 NUCLEOTIDES, SIZE VARIES MUCH. LARGEST KNOWN HUMAN GENE IS DYSTROPHIN ( 2.4 MILLION NUCLEOTIDES)
·TOTAL NUMBER OF GENES 30,000-35,000. MUCH LOWER NUMBER THAN PREVIOUSLY ESTIMATED 80,000- 140,000 NUMBER. THIS HAD BEEN BASED ON EXTRAPOLATIONS FROM GENE RICH AREAS AS OPPOSED TO A COMPOSITE OF GENE RICH AND GENE POOR AREAS.
·ALMOST ALL (99.9%) NUCLEOTIDE BASES ARE EXACTLY THE SAME IN ALL PERSONS. · THE FUNCTIONS ARE UNKNOWN FOR OVER 50% OF DISCOVERED GENES.
·LESS THAN 2% OF THE GENOME CODES FOR PROTEINS. ·REPEATED SEQUENCES THAT DO NOT CODE FOR ANY PROTEIN MAKE UP AT LEAST 50% OF THE GENOME . THESE ARE CALLED AS ‘JUNK DNA’.
·REPETITIVE SEQUENCES ARE THOUGHT TO HAVE NO DIRECT FUNCTIONS BUT THEY SHED LIGHT ON CHROMOSOME STRUCTURE AND DYNAMICS. IT IS CONSIDERED THAT THESE REPEATS RESHAPE THE GENOME BY REARRANGING IT CREATING ENTIRELY NEW GENES AND MODIFYING AND RESHUFFLING EXISTING GENES
·DURING THE LAST 50 MILLION YEARS, A DRAMATIC DECREASE SEEMS TO HAVE OCCURRED IN THE RATE OF ACCUMULATION OF REPEATS IN THE HUMAN GENOME. ·THE HUMAN GENOME’S GENE DENSE ‘URBAN CENTERS’ ARE PREDOMINANTLY COMPOSED OF THE DNA BUILDING BLOCKS G AND C.
· IN CONTRAST, THE GENE POOR ‘DESERTS’ ARE RICH IN THE DNA BUILDING BLOCKS A AND T. GC AND AT RICH REGIONS USUALLY CAN BE SEEN THROUGH A MICROSCOPE AS LIGHT AND DARK BANDS ON CHROMOSOMES. · GENES APPEAR TO BE CONCENTRATED IN RANDOM AREAS ALONG THE GENOME WITH VAST EXPANSES OF NONCODING DNA BETWEEN.
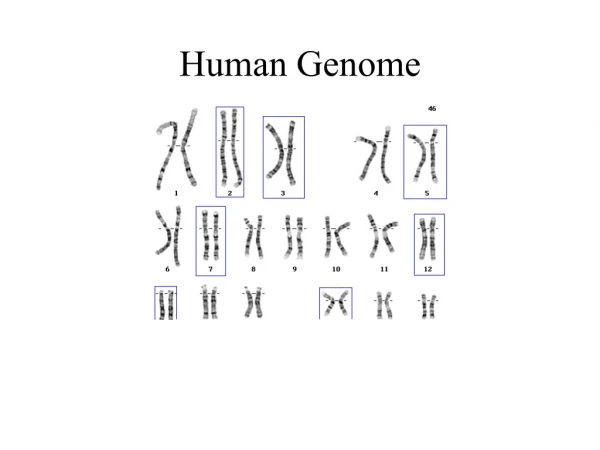
·STRETCHES OF UPTO 30,000 C AND G BASES REPEATING OVER AND OVER OFTEN OCCUR ADJACENT TO GENE RICH AREAS FORMING A BARRIER BETWEEN THE GENES AND THE ‘JUNK DNA’. THESE CG ISLANDS ARE BELIEVED TO HELP REGULATE GENE ACTIVITY. ·CHROMOSOME 1 HAS THE MOST GENES (2968) AND THE Y CHROMOSOME HAS THE FEWEST (231).
·UNLIKE THE HUMAN’S SEEMINGLY RANDOM DISTRIBUTION OF GENE RICH AREAS, MANY OTHER ORGANISMS GENOMES ARE MORE UNIFORM WITH GENES EVENLY SPACED THROUGHOUT. · HUMANS HAVE ON AVERAGE THREE TIMES AS MANY KINDS OF PROTEINS AS THE FLY OR WORM BECAUSE OF mRNA TRANSCRIPT ‘ ALTERNATIVE SPLICING’ AND CHEMICAL MODIFICATIONS TO THE PROTEINS. THIS PROCESS CAN YIELD DIFFERENT PROTEIN PRODUCTS FROM THE SAME GENE.
· HUMANS SHARE MOST OF THE SAME PROTEIN FAMILIES WITH WORMS, FLIES, AND PLANTS BUT THE NUMBER OF GENE FAMILY MEMBERS HAS EXPANDED IN HUMANS ESPECIALLY IN PROTEINS INVOLVED IN DEVELOPMENT AND IMMUNITY. ·HUMAN GENOME HAS MUCH GREATER PORTION OF REPEAT SEQUENCES (50%) THAN MUSTARD WEED (11%), THE WORM (7%), AND THE FLY (3%).
·ALTHOUGH HUMANS APPEAR TO HAVE STOPPED ACCUMULATING REPEATED DNA OVER 50 MILLION YEARS AGO, THERE SEEMS TO BE NO SUCH DECLINE IN RODENTS. THIS MAY ACCOUNT FOR SOME OF THE FUNDAMENTAL DIFFERENCES BETWEEN HOMINIDS AND RODENTS ALTHOUGH GENE ESTIMATES ARE SIMILAR IN THESE SPECIES. SCIENTISTS HAVE PROPOSED MANY THEORIES TO EXPLAIN EVOLUTIONARY CONTRASTS BETWEEN HUMANS AND OTHER ORGANISMS INCLUDING THOSE OF LIFE SPAN, LITTER SIZES, INBREEDING, AND GENETIC DRIFT.
· IN 2003, FINE SEQUENCES HAVE BEEN SUBMITTED. · AS PER LATEST ESTIMATE, NOW TOTAL 24847 GENES HAVE BEEN PREDICTED IN THE ENTIRE HUMAN GENOME.
VARIATIONS AND MUTATIONS • ABOUT 1.4 MILLION LOCATIONS HAVE BEEN IDENTIFIED WHERE SINGLE BASE DIFFERENCES OCCUR IN HUMANS. THIS INFORMATION PROMISES TO REVOLUTIONIZE THE PROCESSES OF FINDING CHROMOSOMAL LOCATIONS FOR DISEASE ASSOCIATED SEQUENCES AND TRACING HUMAN HISTORY.
THE RATIO OF GERMLINE (SPERM OR EGG CELL) MUTATIONS IS 2:1 IN MALES VS FEMALES. RESEARCHERS GIVE SEVERAL REASONS FOR THE HIGHER MUTATION RATE IN THE MALE GERMLINE INCLUDING THE GREATER NUMBER OF CELL DIVISIONS REQUIRED FOR SPERM FORMATION THAN FOR EGGS.
APPLICATIONS, FUTURE CHALLENGES • DERIVING MEANINGFUL KNOWLEDGE FROM THE DNA SEQUENCE WILL DEFINE RESEARCH TO INFORM UNDERSTANDING OF BIOLOGICAL SYSTEMS. THIS TASK WILL REQUIRE EXPERTISE AND CREATIVITY OF TENS OF THOUSANDS OF SCIENTISTS FROM VARIED DISCIPLINES IN BOTH THE PUBLIC AND PRIVATE SECTORS WORLDWIDE.
HAVING THIS SEQUENCE WILL ENABLE THE WORKERS A NEW APPROACH TO BIOLOGICAL RESEARCH. IN THE PAST, RESEARCHERS STUDIED ONE OR FEW GENES AT A TIME. WITH WHOLE GENOME SEQUENCES AND NEW HIGH THROUGHPUT TECHNOLOGIES, THEY CAN APPROACH QUESTIONS SYSTEMATICALLY AND ON A GRAND SCALE. THEY CAN STUDY ALL THE GENES IN A GENOME, FOR EXAMPLE, OR ALL THE TRANSCRIPTS IN A PARTICULAR TISSUE OR ORGAN OR TUMOR , OR HOW TENS OF THOUSANDS OF GENES AND PROTEINS WORK TOGETHER IN INTERCONNECTED NETWORKS TO ORCHESTRATE THE CHEMISTRY OF LIFE.
Organism Size Yr. of No. of Gene (Mb) Seq. Genes density • Saccharomyces cerevisiae 12.1 1996 6034 483 • Escherichia coli 4.6 1997 4200 932 • Caenorhabditis elegans 97 1998 19099 197 (roundworm) • Arabidopsis thaliana 100 2000 25000 221 • Drosophila melanogaster 180 2000 13061 117 • Human 3200 2001 30000- 12 Draft 35,000
Nature (Feb. 2001) 409, 819 • www.nature.com/nature/journal/v409/n6822/fig_tab/409818a0_F1.html) • Gene predictions are made by computational algorithms based on recognition of gene sequence features and similarities to known genes. Gene estimates need further confirmation including characterization of their protein products and functions. • Gene density = Number of genes per million sequenced DNA bases. • For this talk, the matter has been collected from Human Genome News published by the US Department of Energy Office of biological and environmental research ( July 2001 issue)
Do-it-yourself science • With the sharply falling costs of equipment and wealth of information that is publicly available, we are getting to the point at which almost anyone with access to the internet and equipment for sequencing can publish his/her genetic information. • It is evident from the recent story published in Nature about Hugh Rienhoff, a trained geneticist and biotechnology entrepreneur, whose daughter was born with a collection of congenital defects. • He investigated the genetic cause by himself by buying lab equipments and having her gene sequenced. • He posted his theories behind the possible cause of disease and posted information about her condition and genetic sequence on the internet. • Besides, the recent release of greatly enhanced haplotype map or HapMap, describes the most common forms of human genetic variation characterizing over 3.1 million human SNPs across geographically diverse populations. • These findings demonstrate the power of genomics to deliver clues that could yield better medicine and uncovering multiple genes that may be associated with the risk of developing specific diseases.
IN FEBRUARY , 2001, CELERA GENOMICS & HUMAN GENOME PROJECT EACH PUBLISHED THEIR SEQUENCES OF THE HUMAN GENOME. IT WAS A MONUMENTAL ACHIEVEMENT.
PEOPLE - WHAT COMES NEXT AFTER THE SEQUENCE OF THE HUMAN GENOME • RESEARCHER- PROTEOMICS ( THE STUDY OF PROTEINS CODED BY GENES) • PROTEOME- REFERS TO THE WHOLE BODY OF DIVERSE PROTEINS FOUND IN AN ORGANISM - JOSHUA LEDERBERG (Nobel Laureate)
PROTEOMICS IS THE SYSTEMATIC CATALOGING, SEPARATION, AND STUDY OF ALL THE PROTEINS PRODUCED BY GENES WITHIN EACH CELL AS WELL AS THE COMPLEX INTERACTIONS AMONG PROTEINS THAT ULTIMATELY RESULT IN HEALTH OR DISEASE • PROTEOMICS ADDRESSES THE QUESTION OF WHAT PROTEINS DO IN A CELL IN A GLOBAL , INTEGRATED WAY- Brian T. Chait, Professor & Head, Mass Spectrometry & Gaseous Ion Chemistry Laboratory, Rockfeller University
THE TERM ‘PROTEOMICS’ & ‘PROTEOME’ ONLY CAME INTO USE BETWEEN 1995 & 1998 BY ANALOGY WITH ‘GENOMICS’ & GENOME, AND ARE STILL NOT IN STANDARD DICTIONARIES- J. Lederberg • PROTEOMICS IS THE STUDY OF WHERE EACH PROTEIN IS LOCATED IN A CELL, WHEN THE PROTEIN IS PRESENT AND FOR HOW LONG, AND WITH WHICH OTHER PROTEINS IT IS INTERACTING. IT MEANS LOOKING AT MANY EVENTS AT THE SAME TIME AND CONNECTING THEM – Brian T. Chait
WE KNOW TENS OF THOUSANDS OF PROTEINS AT THIS STAGE BUT JUST AS THE PERIODIC TABLE ENABLED US TO SAY THAT THERE WAS A LARGER NUMBER OF ELEMENTS THAT HAD YET TO BE DISCOVERED, THAT IS TRUE CURRENTLY ABOUT PROTEINS – Lederberg
DNA----------------- RNA---------------PROTEIN • PROTEINS ARE COMPOSED OF AMINO ACIDS WHICH ARE ARRANGED ACCORDING TO PARTICULAR SEQUENCES WHICH CORRESPOND TO THE SEQUENCE OF NUCLEOTIDES IN THE GENE. AFTER SYNTHESIS , MANY PROTEINS ARE ALSO CHEMICALLY MODIFIED. AT THIS STAGE, THE PROTEIN ESSENTIALLY HAS ALL THE INFORMATION NECESSARY TO ADOPT ITS THREE DIMENSIONAL STRUCTURE
PROTEINS ARE THE WORKHORSE OF THE CELL AND ALL PROTEINS WORK TOGETHER IN A COMPLEX NETWORK TO GIVE FUNCTION – F. Hochstrasser, University of Geneva, Switzerland • GENES ARE THE ‘BLUEPRINTS’ FOR INFORMATION REQUIRED FOR LIFE, BUT PROTEINS EXPRESSED IN DIFFERENT CELLS ARE THE DYNAMIC MACHINES RESPONSIBLE FOR FUNCTION- John H. Richards, CALTECH
FROM HUMAN GENOME SEQUENCES, IT HAS BEEN ESTIMATED THAT THERE ARE NEARLY 25,000 GENES AGAINST THE PREVIOUS ESTIMATES of NEARLY 100,000 OR MORE • HOW DO WE MANAGE TO BE SO COMPLEX WITH SO FEW GENES ? • IT IS APPARENT THAT OUR COMPLEXITY IS TIED NOT TO THE NUMBER OF GENES BUT RATHER TO THE COMPLEXITY OF THEIR PRODUCTS, THE PROTEINS.
Drosophila (fruit fly) - 13,000 GENES Roundworm - 19,000 GENES HUMAN - 25,000 GENES • ALL THREE ORGANISMS SHARE MANY HOMOLOGOUS GENES • THE KEY TO EACH ORGANISM’S UNIQUENESS LIES IN THE FACT THAT EACH GENE MAY PRODUCE MORE THAN ONE PROTEIN - ANYWHERE FROM SIX TO TWENTY OR MORE-NOT THE OLD CONCEPT OF ONE TO ONE RATIO OF GENES TO PROTEINS
THE HUMAN GENOME DIVERSITY IS TREMENDOUS, SEVERAL ORDERS OF MAGNITUDE GREATER THAN THE GENOME DIVERSITY. EACH GENE NORMALLY EXPRESSES FIVE-SIX PROTEINS AND UPTO TWENTY WITH INCREASING AGE. A HUMAN MAY EXPRESS UPTO A HALF MILLION PROTEINS. HOWEVER, ONLY ABOUT 80,000 PROTEINS HAVE BEEN IDENTIFIED SO FAR, AND ONLY SMALL NUMBER OUT OF 80,000 HAVE BEEN STUDIED IN DETAIL. THE PACE OF DISCOVERY IN PROTEOMICS HAS ACCELERATED AND THIS FIELD IS ENTERING IN AN EXCITING NEW ERA.
HOW DO GENES PRODUCE SUCH A DIVERSITY OF PROTEINS ? • THIS IS DUE TO THE WAY INSTRUCTIONS FOR PROTEIN SYNTHESES ARE TRANSMITTED FROM DNA TO THE CYTOPLASM. INFORMATION FOR MAKING PROTEINS IN DNA IS ARRANGED IN BLOCKS CALLED EXONS WHICH ARE INTERRUPTED BY OTHER SEQUENCES CALLED AS INTRONS WHOSE FUNCTION IS NOT UNDERSTOOD YET • THE CELL EDITS THE RNA COPY ASSEMBLED ON THE DNA BY REMOVING INTRONS - RNA SPLICING
IN FACT, SPLICING IS A MORE COMPLEX PROCESS THAN A SIMPLE LINEAR EDITING PROCESS. CELLS CAN USE ALTERNATIVE SPLICING SCHEMES TO GENERATE A VARIETY OF MESSAGES FOR A GIVEN SEQUENCE OF DNA. A LINEAR SEQUENCE OF EXONS 1,2,3,4,5,6,7 CAN NOT ONLY GENERATE mRNAs WHOSE SEQUENCE IS 1-2-3-4-5-6-7 BUT ALSO OTHER SEQUENCES SUCH AS 1-2-3-6, 1-3-4-5-7, 1-2-4-6 etc. ( ALTERNATIVE SPLICING)
THUS USING ALTERNATIVE SPLICING ,THE SAME DNA SEQUENCE-THE SAME GENE-CAN RESULT IN A NUMBER OF PROTEINS. • PROTEIN DIVERSITY ALSO ARISES BECAUSE PROTEINS ARE FREQUENTLY MODIFIED AFTER SYNTHESIS. FOR EX. TWO PROTEINS MAY BE COVALENTLY LINKED THROUGH –S-S- LINKAGE TO FORM DIMER, PHOSPHATE OR SULFATE MAY BE ADDED. IN SOME CASES, CLEAVAGE OCCURS FOR GETTING ACTIVE PROTEINS ( ZYMOGENS). THUS BY ALTERNATIVE SPLICING SCHEMES AND POST TRANSLATIONAL CHANGES, FEW GENES MAY GIVE LARGE NUMBER OF PROTEINS.
DISEASE IS A MALFUNCTION OF PHYSIOLOGICAL PATHWAYS. THE FUNDAMENTAL UNDERLYING CAUSE OF DISEASE IS THAT PROTEINS- NANOMACHINES DO ALL THE JOBS IN THE CELL-GET OUT OF KILTER. • DRUGS WORK BY CORRECTING PROTEIN MALFUNCTION- BY INCREASING OR DECREASING THEIR AMOUNTS OR BY ALTERING THEIR INTERACTIONS AND THUS BY STUDYING PROTEINS, WE EXPECT NOT ONLY TO UNDERSTAND THE NATURE OF DISEASE BUT ALSO LEARN TO DESIGN DRUGS THAT ARE MORE EFFECTIVE THAN DRUGS DEVELOPED.
IN NEW DRUG DEVELOPMENT, THERE ARE NUMBER OF CRUCIAL POINTS IN WHICH PROTEOMICS CAN GUIDE SCIENTISTS. • FIRST WOULD BE THE IDENTIFICATION AND SELECTION OF GOOD TARGETS COMPARED TO SUPERFLUOUS ONES.- Michael Silber, Pfizer Inc. A DRUG TARGET IS A PROTEIN THAT MIGHT BE INHIBITED OR ACTIVATED TO PRODUCE A THERAPEUTIC EFFECT. DRUGS ARE ONLY AS GOOD AS THE TARGETS SELECTED. THIS WILL HELP IN THE DISCOVERY OF NEW AND MORE SPECIFIC MEDICINES.
HOW MANY PROTEINS OR MORE PRECISELY SPECIFIC SITES IN PROTEINS CAN BE TARGETS FOR THERAPEUTICALLY VALUABLE COMPOUNDS. THE ESTIMATE IS VARIABLE FROM 1000 to 20,000. CURRENTLY PHARMACEUTICAL INDUSTRIES ARE WORKING WITH 400-500 TARGETS, MANY OF WHICH ARE RECEPTORS OF ONLY ONE PARTICULAR TYPE. THUS THE FIELD IS POTENTIALLY WIDE OPEN. HOWEVER, IT IS ESSENTIAL TO DETERMINE WHICH TARGETS ARE MOST URGENT, MOST IMPORTANT, AND MOST ACCESSIBLE TO RESEARCH.