Download

1 / 43
430 likes | 682 Views
Lecture 7 Pipeline Hazards. 6 PM. Time. 7. 8. 9. 40. 30. 40. 40. 40. 20. T a s k O r d e r. A. B. C. D. Pipelining Lessons. Pipelining doesn’t help latency of single task, it helps throughput of entire workload Pipeline rate limited by slowest pipeline stage

E N D
Lecture 7Pipeline Hazards CS510 Computer Architectures
6 PM Time 7 8 9 40 30 40 40 40 20 T a s k O r d e r A B C D Pipelining Lessons • Pipelining doesn’t help latency of single task, it helps throughput of entire workload • Pipeline rate limited by slowest pipeline stage • Multiple tasks operating simultaneously • Potential speedup = Number pipe stages • Unbalanced lengths of pipe stages reduces speedup • Time to “fill” pipeline and time to “drain” it reduces speedup CS510 Computer Architectures
Its Not That Easy to Achieve the Promised Performance • Limits to pipelining: Hazards prevent the next instruction from executing during its designated clock cycle • Structural hazards: HW cannot support this combination of instructions • Data hazards: Instruction depends on result of prior instruction still in the pipeline • Control hazards: Pipelining of branches and other instructions that change the PC • Common solution is to stall the pipeline until the hazard is resolved, inserting one or more “bubbles”, i.e., idle clock cycles, in the pipeline CS510 Computer Architectures
Time(clock cycles) CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 Mem ALU Mem Mem Reg Reg Instruction Order ALU Mem Mem Reg Mem Reg ALU ALU ALU Mem Mem Mem Reg Reg Reg Reg Reg Reg Mem Mem Mem Mem Mem Structural Hazards /Memory LOAD Instr 1 Instr 2 Instr 3 Instr 4 Operation on Memory by 2 different instructions in the same clock cycle CS510 Computer Architectures
Time(clock cycles) CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 Mem Mem ALU Mem Mem Reg Reg Instruction Order ALU Mem Mem Mem Reg Mem Reg ALU ALU Mem Mem Mem Mem Reg Reg Reg Reg Mem Mem Instr 3 Stall Stall Stall Mem ALU Instr 3 Reg Mem Structural Hazards with Single-Port Memory LOAD Instr 1 Instr 2 3 cycles stall with 1-port memory CS510 Computer Architectures
DM DM DM DM DM DM IM IM IM IM IM IM Time(clock cycles) CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 ALU DM Reg Reg IM Instruction Order ALU Instr 1 IM DM Reg Reg ALU ALU ALU Instr 2 DM DM DM Reg Reg Reg Reg Reg Reg IM IM IM Instr 3 Instr 4 Instr 5 ALU DM Reg IM Avoiding Structural Hazard with Dual-Port Memory LOAD No stall with 2-port memory CS510 Computer Architectures
Ave Instr Timeunpipelined Ave Instr Time pipelined CPIunpipelinedx Clock Cycleunpipelined CPIpipelinedx Clock Cyclepipelined CPIunpipelined Clock Cycleunpipelined CPIpipelined Clock Cyclepipelined Speedup from pipelining x Speedup = Ideal CPI x Pipeline depth Clock Cycleunpipelined CPIpipelined Clock Cyclepipelined x Speed Up Equation for Pipelining Ideal CPI = CPIunpipelined/Pipeline depth(Number of pipeline stages) Ideal CPI for pipelined machines is almost always 1 CS510 Computer Architectures
Speedup = Ideal CPI x Pipeline depth Clock Cycleunpipelined Ideal CPI + Pipeline stall CPI Clock Cyclepipelined x Speedup = Pipeline depth Clock Cycleunpipelined 1 + Pipeline stall CPI Clock Cyclepipelined x Speed Up Equation for Pipelining CPIpipelined = Ideal CPI + Pipeline stall clock cycles per instr = 1 + Pipeline stall clock cycles per instr CS510 Computer Architectures
Dual-Port vs Single-Port Memory • Machine A: 2-port memory(needs no stall for Load); same clock cycle as unpipelined machine • Machine B: 1-ported memory(needs 3 cycles stall for Load); 1.05 times faster clock rate than the unpipelined machine • Ideal CPI = 1 for both • Loads are 40% of instructions executed SpeedUpA = [Pipeline Depth/(1 + 0)] x (clockunpipe/clockpipe) = Pipeline Depth SpeedUpB = Pipeline Depth/(1 + 0.4 x 3) x (clockunpipe/(clockunpipe / 1.05) = (Pipeline Depth/1.2) x 1.05 = 0.87 x Pipeline Depth SpeedUpA / SpeedUpB = Pipeline Depth/(0.87 x Pipeline Depth) = 1.15 Machine A is 1.15 times faster CS510 Computer Architectures
Time(clock cycles) ALU R1 Mem Reg Reg Mem ALU Reg Mem Reg Mem Reg ALU Reg Mem Reg Mem Reg Reg ALU Mem Reg Mem Reg ALU Reg Mem Reg Mem Reg Data Hazard on Registers CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 ADD R1,R2,R3 SUB R4,R1,R3 AND R6,R1,R7 OR R8,R1,R9 XOR R10,R11,R1 CS510 Computer Architectures
Clcok Cycle Read from Ri Store into Ri Register Ri Data Hazard on Registers Registers can be made to read and store in the same cycle such that data is stored in the first half of the clock cycle, and that data can be read in the second half of the same clock cycle CS510 Computer Architectures
ALU R1 Mem Reg Reg Mem ALU Reg Mem Mem Reg Reg ALU Reg Mem Reg Reg Mem ALU Mem Reg Reg Mem Reg Reg ALU Mem Reg Reg Mem Data Hazard on Registers Time(clock cycles) CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 ADD R1,R2,R3 SUB R4,R1,R3 AND R6,R1,R7 OR R8,R1,R9 XOR R10,R11,R1 Needs to Stall 2 cycles CS510 Computer Architectures
Three Generic Data Hazards Instri followed by Instrj Read After Write (RAW)Instrj tries to read operand before Instri writes it InstriLW R1, 0(R2) Instrj SUB R 4, R1, R5 CS510 Computer Architectures
Three Generic Data Hazards InstrI followed by InstrJ • Write After Read (WAR)Instrj tries to write operand before Instri reads it Instri ADD R1, R2, R3Instrj LW R2, 0(R5) • Can’t happen in DLX 5 stage pipeline because: • All instructions take 5 stages, • Reads are always in stage 2, and • Writes are always in stage 5 CS510 Computer Architectures
Three Generic Data Hazards InstrI followed by InstrJ Write After Write (WAW)Instrj tries to write operand before Instri writes it • Leaves wrong result ( Instri not Instrj) Instri LW R1, 0(R2) Instrj LW R1, 0(R3) • Can’t happen in DLX 5 stage pipeline because: • All instructions take 5 stages, and • Writes are always in stage 5 • Will see WAR and WAW in later more complicated pipes CS510 Computer Architectures
Forwarding to Avoid Data Hazards Time(clock cycles) CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 ALU Mem Reg Reg Mem ADD R1,R2,R3 ALU Mem Mem Reg SUB R4,R1,R3 Reg ALU AND R6,R1,R7 Mem Reg Reg Mem ALU OR R8,R1,R9 Mem Reg Reg Mem ALU XOR R10,R11,R1 Mem Reg Reg Mem CS510 Computer Architectures
Zero? MUX MUX D/A Buffer A/M Buffer M/W Buffer ALU Data Memory HW Change for Forwarding CS510 Computer Architectures
ALU DM Reg IM Reg ALU DM Reg IM Reg Time(clock cycles) ALU DM Reg Reg IM ALU DM Reg IM Reg ALU DM Reg IM Reg ALU DM Reg IM Reg ALU AND R6,R1,R7 DM Reg Reg IM ALU DM OR R8,R1,R9 Reg IM Load Delay Due to Data Hazard LOAD R1,0(R2) Load Delay =2cycles SUB R4,R1,R6 CS510 Computer Architectures
ALU DM Reg IM Reg Time(clock cycles) ALU DM Reg Reg IM ALU DM Reg IM Reg ALU DM Reg Reg IM AND R6,R1,R7 ALU DM Reg Reg IM ALU Reg DM Reg IM OR R8,R1,R9 Load Delay with Forwarding We need to add HW, called Pipeline Interlock LOAD R1,0(R2) Load Delay with Forwarding=1cycle SUB R4,R1,R6 CS510 Computer Architectures
Stall Stall Stall Stall Stall Software Scheduling to Avoid Load Hazards Try to produce fast code for a = b + c; d = e - f; assuming a, b, c, d ,e, and f are in memory. Fast code: LW Rb,b LW Rc,c LW Re,e ADD Ra,Rb,Rc LW Rf,f SW a,Ra SUB Rd,Re,Rf SW d,Rd Slow code(with forwarding): LW Rb,b LW Rc,c ADDRa,Rb,Rc SWa,Ra LW Re,e LW Rf,f SUBRd,Re,Rf SW d,Rd RAW RAW RAW RAW RAW CS510 Computer Architectures
scheduled unscheduled 54% gcc 31% 42% spice 14% 65% tex 25% 0% 20% 40% 60% 80% % loads stalling pipeline Compiler Avoiding Load Stalls CS510 Computer Architectures
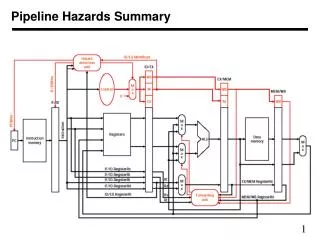
WB Stage ID Stage EX Stage Mem Stage IF Stage MUX Add Zero? +4 MUX Data Memory M/W Buffer PC Instr. Memory F/D Buffer D/A Buffer A/M Buffer Reg File ALU LMD MUX MUX SMD Sign Ext • Branch Address • Calculation • Decide Condition 16 32 • Branch • Decision for • target address Pipelined DLX Datapath CS510 Computer Architectures
ALU ALU ALU DM DM Reg Reg Reg Reg IM IM DM Reg Reg IM Time(clock cycles) CC1 CC2 CC3 CC4 CC5 CC6 CC7 CC8 CC9 ALU DM Reg Reg IM ALU DM Reg Branch Target available Reg IM ALU DM Reg Reg IM ALU DM Reg Reg IM ALU DM Reg Reg IM Control Hazard on Branches:Three Stall Cycles Program execution order in instructions Should’t be executed when branch condition is true ! 40 BEQ R1,R3, 36 44 AND R12,R2, R5 48 OR R13,R6, R2 52 ADD R14,R2, R2 80 LD R4,R7, 100 Branch Delay = 3 cycles CS510 Computer Architectures
We don’t know yet the instruction being executed is a branch. Fetch the branch successor. Now, target address is available. Now, we know the instruction being executed is a branch. But stall until branch target address is known. 3 Wasted clock cycles for the TAKEN branch Control Hazard on Branches:Three Stall Cycles Branch instruction IF ID EX MEM WB Branch successor IF ID EX MEM Branch successor + 1 IF ID EX Branch successor + 2 IF ID CS510 Computer Architectures
Branch Stall Impact • If CPI = 1, 30% branch, Stall 3 cycles => new CPI = 1.9 • Half of the ideal speed • Two part solution: • Determine the branch is TAKEN or NOT TAKEN sooner, AND • Compute TAKEN Branch Address(Branch Target) earlier • DLX branch tests if register = 0 or 1 • DLX Solution: Get New PC earlier • -MoveZero test to ID stage • -Additional ADDERto calculate New PC(taken PC) • in ID stage • -1 clock cycle penalty for branch in contrast to 3 cycles CS510 Computer Architectures
To get target addr. earlier When a branch instruction is in Execute stage, Next Address is available here. IF Stage WB Stage ID Stage EX Stage Mem Stage Zero? MUX Add To get the Condition Earlier. Target Address available after ID. Add +4 MUX Data Memory M/W Buffer PC Instr. Memory F/D Buffer D/A Buffer A/M Buffer Reg File ALU LMD MUX MUX SMD Sign Ext 16 32 Pipelined DLX Datapath CS510 Computer Architectures
Branch Behavior in Programs • Conditional branch frequencies • integer average --- 14 to 16 % • floating point --- 3 to 12 % • Forward and backward taken branches • forward taken --- 60 % • backward taken --- 85 % • the average of all conditional branches ---- 67 % CS510 Computer Architectures
4 Branch Hazard Alternatives • Stall until branch direction is clear • Predict branch NOT TAKEN • Predict branch TAKEN • Delayed branch CS510 Computer Architectures
3 cycle penalty Revised DLX pipeline(get the branch address at EX) Branch instruction IF ID EX MEM WB Branch successor stallIF ID EX MEM WB Branch successor + 1 IF ID EX MEM Branch successor + 2 IF ID 1 cycle penalty(Branch Delay Slot) 4 Branch Hazard Alternatives:(1) STALL Stall until branch direction is clear Branch instruction IF ID EX MEM WB Branch successor stallstall stall IF ID EX MEM Branch successor + 1 IF ID EX Branch successor + 2 IF ID CS510 Computer Architectures
Flush this instruction in progress 4 Branch Hazard Alternatives:(2) Predict Branch “NOT TAKEN” • Execute successor instructions in the sequence • PC+4 is already calculated, so use it to get the next instruction • Flush instructions in the pipeline if branch is actually TAKEN • Advantage of late pipeline state update • 47% of DLX branches are NOT TAKEN on the average NOT TAKEN branch instruction i IF ID EX MEM WB instruction i+1 IF ID EX MEM WB instruction i+2 IF ID EX MEM WB No penalty TAKEN branch instruction i IF ID EX MEM WB instruction i+1 IF ID EX MEM WB instruction T IF ID EX MEM WB 1 cycle penalty CS510 Computer Architectures
TAKEN address not available at this time TAKEN address available 4 Branch Hazard Alternatives: (3) Predict Branch “TAKEN” • 53% DLX branches TAKEN on average • Branch target address available after ID in DLX • DLX still incurs 1 cycle branch penalty for TAKEN branch • Other machines: branch target known before outcome NOT TAKENinstruction i IF ID EX MEM WB Instruction Tstall IF Instruction i+1 IF ID EX MEM WB 2 cycle penalty in DLX(1 in other machines). TAKEN branchinstruction i IF ID EX MEM WB Instruction TstallIF ID EX MEM WB Instruction T+1 IF ID EX MEM WB 1 cycle penalty in DLX(0 in other machines) CS510 Computer Architectures
Delayed Branch of length n 4 Branch Hazard Alternatives:(4) Delayed Branch Delayed Branch • Delay branch to take place AFTER a successor instruction branch instruction sequential successor1 sequential successor2 ........ sequential successorn branch target if taken • 1 slot delayed branch allows proper decision and branch target address in 5 stage DLX pipeline with control hazard improvement CS510 Computer Architectures
Delayed Branch • Where to get instructions to fill branch delay slot? • Before branch instruction • From the target address: only valuable when branch TAKEN • From fall through: only valuable when branch NOT TAKEN • Canceling branches allow more slots to be filled • Compiler effectiveness for single delayed branch slot: • Fills about 60% of delayed branch slots • About 80% of instructions executed in delayed branch slots are useful in computation • About 50% (60% x 80%) of slots usefully filled CS510 Computer Architectures
ADD R1, R2, R3 if R2=0 then SUB R4, R5, R6 ADD R1, R2, R3 if R1=0 then ADD R1, R2, R3 if R1=0 then SUB R4, R5, R6 Delay slot Delay slot Delay slot if R2=0 then ADD R1, R2, R3 if R1=0 then ADD R1, R2, R3 if R2=0 then ADD R1, R2, R3 SUB R4, R5, R6 SUB R4, R5, R6 4 Branch Hazard Alternatives:Delayed Branch From before From fall through From target - Improve performance when TAKEN(loop) - Must be alright to execute rescheduled instructions if Not Taken - May need duplicate the instruction if it is the target of another branch instr. - Improve performance when NOT TAKEN - Must be alright to execute instructions of Taken - Always improve performance - Branch must not depend on rescheduled instructions CS510 Computer Architectures
Limitations on Delayed Branch • Difficulty in finding useful instructions to fill the delayed branch slots • Solution - Squashing • Delayed branch associated with a branch prediction • Instructions in the predicted path are executed in the delayed branch slot • If the branch outcome is mispredicted, instructions in the delayed branch slot are squashed(discarded) CS510 Computer Architectures
Canceling Branch • Used when the delayed branch scheduling, i.e., filling the delay slot cannot be done due to • Restrictions on scheduling instructions at the delay slots • Limitations on the ability to predict whether it will TAKE or NOT TAKE at compile time • Instruction includes the direction that the branch was predicted • When the branch behaves as predicted, the instructions in the delay slot are executed • When branch is incorrectly predicted, the instructions in the delay slot are turned into No-OPs • Canceling Branch allows to fill the delay slot even if the instruction to be filled in the delay slot does not meet the requirements CS510 Computer Architectures
Pipeline speedup = Pipeline depth / CPI Pipeline depth = 1 + Branch frequency x Branch penalty Evaluating Branch Alternatives Stall pipeline 3 1+0.14x3=1.42 5/1.42=3.5 1.0 Predict Taken 1 1+0.14x1=1.14 5/1.14=4.4 1.26 Predict Not Taken 1 1+0.14x0.65=1.09 5/1.09=4.5 1.29 Delayed branch 0.5 1+0.14x0.5=1.07 5/1.07=4.6 1.31 Conditional and Unconditional collectively 14% frequency, 65% of branch is TAKEN Scheduling Branch CPI speedup vs speedup vs scheme penalty unpipelined stall CS510 Computer Architectures
If branch is almost alwaysNOT TAKEN, and R4 is not needed on the taken path, and R5 and R6 are not modified in the following instruction(s), this move can increase speed Depend on LW, need to stall If branch is almost alwaysTAKEN, and R7 is not needed, and R8 and R9 are not modified on the fall-through path, this move can increase speed Static(Compiler) Prediction of Taken/Untaken Branches Code Motion LW R1, 0(R2) SUB R1, R1, R3 BEQZ R1, L OR R4, R5, R6 ADD R10,R4,R3 L: ADD R7, R8, R9 CS510 Computer Architectures
14% 70% 12% 60% 10% 50% Misprediction Rate 8% 40% Frequency of Misprediction 30% 6% 20% 4% 10% 2% 0% 0% gcc ora doduc gcc ora alvinn doduc tomcatv hydro2d espresso mdljsp2 swm256 alvinn compress tomcatv hydro2d espresso mdljsp2 swm256 compress Taken backwards Not Taken Forwards Always taken Static(Compiler) Prediction of Taken/Untaken Branches • Improves strategy for placing instructions in delay slot • Two strategies • Direction-based Prediction: TAKEN backward branch, NOT TAKEN forward branch • Profile-based prediction: Record branch behaviors, predict branch based on the prior run(s) CS510 Computer Architectures
100000 10000 1000 Instructions per mispredicted branch 100 10 1 gcc ora doduc alvinn tomcatv hydro2d mdljsp2 espresso swm256 compress Profile-based Direction-based Evaluating Static Branch Prediction Strategies • Misprediction rate ignores frequency of branch • Instructions between mispredicted branches is a better metric CS510 Computer Architectures
Pipeline Depth Clock Cycle Unpipelined Speedup = X Clock Cycle Pipelined 1 + Pipeline stall CPI Pipelining Summary • Just overlap tasks, and easy if tasks are independent • Speed Up <= Pipeline Depth; if ideal CPI is 1, then: • Hazards limit performance on computers: • Structural: need more HW resources • Data: need forwarding, compiler scheduling • Control: Dynamic Prediction, Delayed branch slot, • Static(compiler) Prediction CS510 Computer Architectures