Download
1 / 4
40 likes | 179 Views
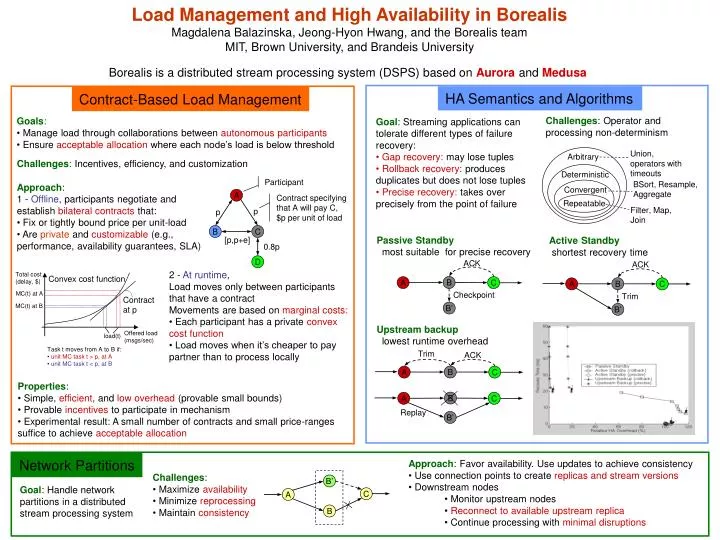
Borealis is a distributed stream processing system (DSPS) based on Aurora and Medusa. HA Semantics and Algorithms. Contract-Based Load Management.

E N D
Borealis is a distributed stream processing system (DSPS) based on Aurora and Medusa HA Semantics and Algorithms Contract-Based Load Management Load Management and High Availability in BorealisMagdalena Balazinska, Jeong-Hyon Hwang, and the Borealis teamMIT, Brown University, and Brandeis University Challenges: Operator and processing non-determinism • Goals: • Manage load through collaborations between autonomous participants • Ensure acceptable allocation where each node’s load is below threshold • Goal: Streaming applications can tolerate different types of failure recovery: • Gap recovery: may lose tuples • Rollback recovery: produces duplicates but does not lose tuples • Precise recovery: takes over precisely from the point of failure Union, operators with timeouts Arbitrary Challenges: Incentives, efficiency, and customization Deterministic BSort, Resample, Aggregate Participant • Approach: • 1 - Offline, participants negotiate and establish bilateral contracts that: • Fix or tightly bound price per unit-load • Are private and customizable(e.g., performance, availability guarantees, SLA) Convergent A Contract specifying that A will pay C, $p per unit of load Repeatable Filter, Map, Join p p B C Passive Standby most suitable for precise recovery Active Standby shortest recovery time [p,p+e] 0.8p ACK D ACK • 2 - At runtime, • Load moves only between participants that have a contract • Movements are based onmarginal costs: • Each participant has a private convex cost function • Load moves when it’s cheaper to pay partner than to process locally Total cost (delay, $) Convex cost function B A C B A C MC(t) at A Checkpoint Trim Contract at p MC(t) at B B’ B’ Upstream backup lowest runtime overhead Offered load (msgs/sec) load(t) • Task t moves from A to B if: • unit MC task t > p, at A • unit MC task t < p, at B Trim ACK B A C • Properties: • Simple, efficient, and low overhead (provable small bounds) • Provable incentives to participate in mechanism • Experimental result: A small number of contracts and small price-ranges suffice to achieve acceptable allocation B A C Replay B’ Network Partitions • Approach: Favor availability. Use updates to achieve consistency • Use connection points to create replicas and stream versions • Downstream nodes • Monitor upstream nodes • Reconnect to available upstream replica • Continue processing with minimal disruptions • Challenges: • Maximize availability • Minimize reprocessing • Maintain consistency B’ Goal: Handle network partitions in a distributed stream processing system C A B
Load Management Demonstration Setup All nodes process a network monitoring query over real traces of connection summaries Connection information Clusters of IPs that establish many connections F Group by IP prefix, sum Filter > 100 60s Group by IP count Filter > 100 60s T IPs that establish many connections IPs that connect over many ports Group by IP count distinct port Filter > 10 60s Node A overloaded A sheds load to B then to C Query: Count the connections established by each IP over 60 sec and the number of distinct ports to which each IP connected A 1) Three nodes with identical contracts and uneven initial load distribution p p A Acceptable allocation B C p B C 2) As node A becomes overloaded it sheds load to its partners B and C until system reaches acceptable allocation A B C 3) Load increases at node B causing system overload B A System overload C Acceptable allocation 4) Node D joins the system. Load flows from node B to C and C to D until the system reaches acceptable allocation B C 0.8p D D Load flows from C to D and from B to C Node D joins
High Availability Demonstration Setup Identical queries traverse nodes that use different high availability approaches Passive Standby 1) The four primaries, B0, C0, D0, and E0 run on one laptop B0 B1 B0’ Statically assigned secondary 2) All other nodes run on the other laptop Active Standby C1 C0 C0’ 3) We compare the runtime overhead of the approaches A 4) We kill all primaries at the same time Upstream Backup D1 D0 D0’ 5) We compare the recovery time and the effects on tuple delay and duplication Upstream Backup & Duplicate Elimination E1 E0 E0’ Passive standby adds most end-to-end delay Active Standby Passive Standby Failure Tuples received E2E delay Upstream Backup UB no dups Upstream backup has highest overhead during recovery Active standby has highest runtime overhead Duplicate tuples Failure
Network Partition Demonstration Setup No duplications and no losses after network partitions 1) The initial query distribution crosses computer boundaries Laptop 1 A R C 2) We unplug the cable connecting the laptops Tuples received through R Tuples received through B B Laptop 2 3) Node C detects that node B has become unreachable 4) Node C identifies node R as reachable alternate replica: Output stream has the same name but a different version Sequence nb of received tuples 5) Node C connects to node R and continues processing from the same point on the stream 6) Node C changes the version of its output stream End-to-end tuple delay 7) When partition heals, node C remains connected to R and continues processing uninterrupted End-to-end tuple delay increases while C detects the network partition and re-connects to R