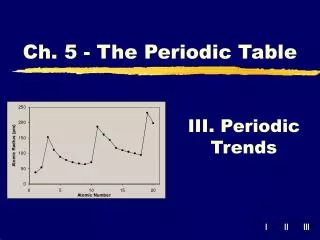
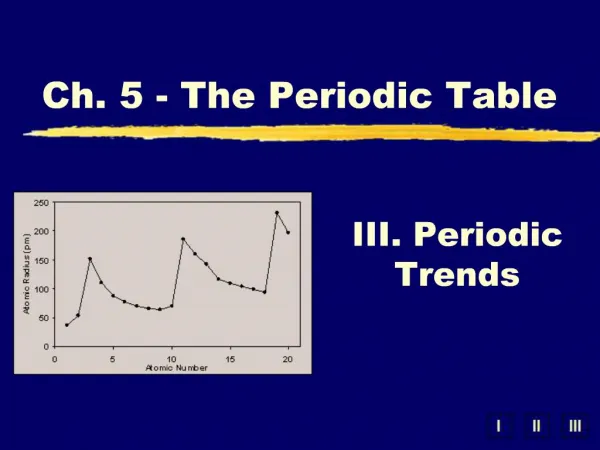
Download

1 / 32
320 likes | 484 Views
3C13/D6. III. Current Trends . Part 1: Distributed DBMSs: Concepts and Design Lecture 12 (2 hours) Lecturer: Chris Clack. 12.0 Content. Content. 12.1 Objectives 12.2 Overview of Networking 12.3 Introduction to DDBMSs - Concepts - Advantages and Disadvantages

E N D
3C13/D6 III. Current Trends Part 1: Distributed DBMSs: Concepts and Design Lecture 12 (2 hours) Lecturer: Chris Clack
12.0 Content Content 12.1 Objectives 12.2 Overview of Networking 12.3 Introduction to DDBMSs - Concepts - Advantages and Disadvantages - Homogeneous and Heterogeneous 12.4 Functions and Architecture - Functions of a DDBMS - Reference Architecture for a DDBMS/ Federated MDBS 12.5 Distributed Relational Database Design - Data Allocation - Fragmentation 12.6 Transparency in a DDBMS - Distribution Transparency - Transaction Transparency - Performance Transparency 12.7 Date’s 12 Rules for DDBMs 12.8 Summary
12.1 Objectives Objectives In this Lecture you will learn: • Concepts. • Advantages and disadvantages of distributed databases. • Functions and architecture for a DDBMS. • Distributed database design. • Levels of transparency. • Comparison criteria for DDBMSs.
12.2 Overview of Networking Overview of Networking Network: interconnected collection of autonomous computers, capable of exchanging information. • Local Area Network (LAN) intended for connecting computers at same site. • Wide Area Network (WAN) used when computers or LANs need to be connected over long distances. • WAN relatively slow • Less reliable than LANs. • DDBMS using LAN provides much faster response time than one using WAN.
12.2 Overview of Networking Overview of Networking Network: interconnected collection of autonomous computers, capable of exchanging information. • Local Area Network (LAN) intended for connecting computers at same site. • Wide Area Network (WAN) used when computers or LANs need to be connected over long distances. • WAN relatively slow • Less reliable than LANs. • DDBMS using LAN provides much faster response time than one using WAN.
12.3 Introduction Concepts Databases and networks: • A centralized DBMS could be physically processed by several computers distributed across a network • There could be several separate DBMS on several computers distributed across a network • There may be a Distributed DBMS (DDBMS) • made up of several DBMSs distributed across a network • each with local autonomy • Each participates in at least one global DBMS action • The DDBMS therefore can operate as a single global DBMS
12.3 Introduction Concepts DDBMS to Avoid `islands of information’ problem… A “Distributed Database”: is alogically interrelated collection of shared data (and a description of this data), physically distributed over a computer network. A “Distributed DBMS” (DDBMS): is aSoftware system that permits the management of the distributed database and makes the distribution transparent to users. Fundamental Principle:make distribution transparent to user. The fact that fragments are stored on different computers is hidden from the users
12.3 Introduction Concepts • DDBMS has following characteristics: • Collection of logically-related shared data. • Data split into fragments. • Fragments may be replicated. • Fragments/replicas allocated to sites. • Sites linked by a communication network. • Data at each site is under control of a DBMS. • DBMSs handle local applications autonomously. • Each DBMS participates in at least one global application.
12.3 Introduction Important difference between DDBMS and distributed processing ! Distributed processing of centralised DBMS DDBMS
12.3 Introduction • Distributed processing of a centralised DBMS has following characteristics : • Much more tightly coupled than a DDBMS. • Database design is same as for standard DBMS • No attempt to reflect organisational structure • Much simpler than DDBMS • More secure than DDBMS • No local autonomy
12.3 Introduction Important difference between DDBMS and parallel database Parallel Database Architectures: Shared: a)memory b)disk c)nothing DDBMS
12.3 Introduction Why use a DDBMS? (!) • Advantages: • Reflects organizational structure • Improved shareability and • local autonomy • Improved availability • Improved reliability • Improved performance • Economics • Modular growth • Disadvantages: • Complexity • Cost • Security • Integrity control more difficult • Lack of standards • Lack of experience • Database design more complex
12.3 Introduction Homogeneous & Heterogeneous DDBMSs • Homogeneous:All sites use same DBMS product. • Much easier to design and manage. • Approach provides incremental growth • Allows increased performance. • Heterogeneous: Sites may run different DBMS products, underlying data models. • Sites implemented their own databases - integration considered later. • Translations required to allow for • Typical solution is to use gateways. • Different hardware. • Different DBMS products. • Different hardware and DBMS products.
12.3 Introduction Open Database access and interoperability “The Open Group” formed Specification Working Group (SWG) to provide specifications that create database infrastructure environment where there is: • Common SQL API :allows client applications to be written that do not need to know vendor of DBMS they are accessing. • Common database protocol: enables DBMS from one vendor to communicate directly with DBMS from another vendor without need for a gateway. • Common network protocol: allows communications between different DBMSs.
12.3 Introduction Multidatabase system (MDBS)! • MDBS: DDBMS where each site maintains complete autonomy • Resides transparently on top of existing database and file systems • presents a single database to its users. • Allows users to access and share data without requiring physical database integration. 2 types: • Federated MDBS: looks like a DDBMS for global users and a centralized DBMS for local users. • Unfederated MDBS: has no “local” users
12.4 Functions and Architecture of a DDBMS Functions and Architecture of a DDBMS
12.4 Functions and Architecture of a DDBMS Functions of a DDBMS • Expect DDBMS to have at least the functionality of a DBMS. • Also to have following functionality: • Extended communication services. • Extended Data Dictionary. • Distributed query processing. • Extended concurrency control. • Extended recovery services.
12.4 Functions and Architecture of a DDBMS DDBMS Reference Architecture • A reference architecture consists of: • Set of global external schemas. • Global conceptual schema (GCS). • Fragmentation schema and allocation schema (see later …) • Set of schemas for each local DBMS conforming to 3-level ANSI/SPARC. • Comparison with federated MDBS: In DDBMS: GCS is union of all local conceptual schemas. In FMDBS: GCS is subset of local conceptual schemas (LCS), consisting of data that each local system agrees to share. GCS of tightly coupled system involves integration of either parts of LCSs or local external schemas. FMDBS with no GCS is called loosely coupled.
12.4 Functions and Architecture of a DDBMS Distributed Relation Database Design
12.5 Distributed Relational Database Design Data Allocation ! Four alternative strategies regarding placement of data: • Centralized: single database and DBMS stored at one site with users distributed across the network. • Partitioned: Database partitioned into disjoint fragments, each fragment assigned to one site. • Complete Replication: Consists of maintaining complete copy of database at each site. • Selective Replication: Combination of partitioning, replication, and centralization. Comparison of strategies
12.5 Distributed Relational Database Design Data Allocation Four alternative strategies regarding placement of data: • Centralized: single database and DBMS stored at one site with users distributed across the network. • Partitioned: Database partitioned into disjoint fragments, each fragment assigned to one site. • Complete Replication: Consists of maintaining complete copy of database at each site. • Selective Replication: Combination of partitioning, replication, and centralization. Comparison of strategies
12.5 Distributed Relational Database Design Fragmentation Why fragment? Usage: - Apps work with views rather than entire relations. Efficiency: -Data stored close to where most frequently used. - Data not needed by local applications is not stored. Security: - and so not available to unauthorized users. Parallelism: - With fragments as unit of distribution, T can be divided into several subqueries that operate on fragments. Disadvantages: Performance & Integrity.
12.5 Distributed Relational Database Design Fragmentation ! Three Correctness of fragmentation rules: • Completeness: If relation R decomposed into fragments R1, R2, ... Rn, each data item that can be found in R must appear in at least one fragment. • Reconstruction: Must be possible to define a relational operation that will reconstruct R from the fragments. - for horizontal fragmentation: Union operation - for vertical: Join 3. Disjointness: If data item di appears in fragment Ri, then should not appear in any other fragment. - Exception: vertical fragmentation. - For horizontal fragmentation, data item is a tuple. - For vertical fragmentation, data item is an attribute.
12.5 Distributed Relational Database Design Fragmentation ! Four types of fragmentation: Horizontal: Consists of a subset of the tuples of a relation. - Defined using Selection operation - Determined by looking at predicates used by Ts. - Involves finding set of minimal (complete and relevant) predicates. - Set of predicates is complete, iff, any two tuples in same fragment are referenced with same probability by any application. - Predicate is relevant if there is at least one application that accesses fragments differently.
12.5 Distributed Relational Database Design Fragmentation ! Other possibility is no fragmentation: • If relation is small and not updated frequently, may be better not to fragment. Four types of fragmentation: 2. Vertical: subset of atts of a relation. - Defined using Projection operation - Determined by establishing affinity of one attribute to another. 3. Mixed:horizontal fragment that is vertically fragmented, or a vertical fragment that is horizontally fragmented. - Defined using Selection and Projection operations 4. Derived: horizontal fragment that is based on horizontal fragmentation of a parent relation. • - Ensures fragments frequently joined together are at same site. • - Defined using Semijoin operation
12.6 Distributed Relational Database Design Transparency in a DDBMS Transparency hides implementation details from users. Overall objective: equivalence to user of DDBMs to centralised DBMS - FULL transparency not universally accepted objective Four main types: • Distribution transparency • Transaction transparency • Performance transparency • DBMS transparency (only applicable to heterogeneous)
12.6 Distributed Relational Database Design 1. Distribution Transparency Distribution transparency:allows user to perceive database as single, logical entity. If DDBMS exhibits distribution transparency, user does not need to know: • fragmentation transparency: data is fragmented • Location transparency: location of data items • otherwise call this local mapping transparency • replication transparency: user unaware of replication of fragments Naming transparency: each item in a DDB must have a unique name. • One solution: create central name server- loss of some local autonomy. - central site may become a bottleneck. - low availability: if the central site fails. • Alternative solution:prefix object with identifier of creator site, each fragment and its copies. Then each site uses alias.
12.6 Distributed Relational Database Design 2. Transaction Transparency Transaction transparency: Ensures all distributed Ts maintain distributed database’s integrity and consistency. • Distributed T accesses data stored at more than one location. • Each T is divided into no. of subTs, one for each site that has to be accessed. • DDBMS must ensure the indivisibility of both the global T and each of the subTs.
12.6 Distributed Relational Database Design 2. Transaction Transparency • Concurrency transparency: All Ts must execute independently and be logically consistent with results obtained if Ts executed in some arbitrary serial order. • Replication makes concurrency more complex • Failure transparency: must ensure atomicity and durability of global T. • Means ensuring that subTs of global T either all commit or all abort. • Classification transparency: In IBM’s Distributed Relational Database Architecture (DRDA), four types of Ts: • Remote request • Remote unit of work • Distributed unit of work • Distributed request.
12.6 Distributed Relational Database Design 3. Performance Transparency • DDBMS: -no performance degradation due to distributed architecture. • - determine most cost-effective strategy to execute a request. Distributed Query Processor (DQP) maps data request into ordered sequence of operations on local databases. - Must consider fragmentation, replication, and allocation schemas. DQP has to decide: • which fragment to access • which copy of a fragment to use • which location to use. - produces execution strategy optimized with respect to some cost function. • Typically, costs associated with a distributed request include: I/O cost; • CPU cost, communication cost.
12.7 Dates 12 Rules for DDBMS Date’s 12 Rules for DDBMS Fundamental Principle: To the user, distributed system should look exactly like a nondistributed system. 1. Local Autonomy 2. No Reliance on a Central Site 3. Continuous Operation 4. Location Independence 5. Fragmentation Independence 6. Replication Independence 7. Distributed Query Processing 8. Distributed Transaction Processing Ideals: 9. Hardware Independence 10. Operating System Independence 11. Network Independence 12. Database Independence
12.8 Summary Summary • 12.1 Objectives • 12.2 Overview of Networking • 12.3 Introduction to DDBMSs • Concepts • Advantages and Disadvantages • Homogeneous and Heterogeneous • 12.4 Functions and Architecture • Functions of a DDBMS • Reference Architecture for a • DDBMS/ Federated MDBS • 12.5 Distributed Relational Database Design • Data Allocation • Fragmentation • 12.6 Transparency in a DDBMS • - Distribution Transparency • - Transaction Transparency • - Performance Transparency • 12.7 Date’s 12 Rules for DDBMs NEXT LECTURE: III Current Trends Part 2: Distributed DBMSs- Advanced concepts - advanced concepts - protocols for distributed deadlock control - X/Open Distributed Transaction Processing Model - Oracle.