Download

1 / 29
290 likes | 392 Views
Eidgenössisches Departement des Innern EDI Bundesamt für Meteorologie und Klimatologie MeteoSchweiz. Porting physical parametrizations to GPUs using compiler directives. X. Lapillonne, O. Fuhrer. Outline. Computing with GPUs GPU implementation using PGI-directives

E N D
Eidgenössisches Departement des Innern EDIBundesamt für Meteorologie und Klimatologie MeteoSchweiz Porting physical parametrizations to GPUs using compiler directives X. Lapillonne, O. Fuhrer
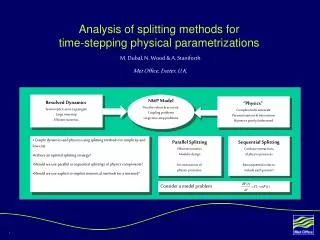
Outline • Computing with GPUs • GPU implementation using PGI-directives • The example of the microphysics parametrization • Summary
Computing on Graphical Processing Units (GPUs) • Benefit from the highly parallel architecture of GPUs • Higher peak performance at lower cost / power consumption. • High memory bandwidth
2 levels of parallelism Execution model • Copy data from CPU to GPU • Load GPU program (Kernel) and execution: • Same kernel is executed by all threads • Threads are grouped in blocks: • Synchronized (similar to SIMD vectorization) • Share data through shared memory • Blocks are arranged in a grid • Threads from different blocks are independent • Copy back data form GPU to CPU Host (CPU) Device(GPU) Data Transfer Grid Sequential Block (0,0) Block (1,0) Kernel Block (1,0) Block (1,1) Sequential Block (1,1) Thread (0,0) Thread (1,0) Thread (2,0) Thread (0,1) Thread (1,1) Thread (2,1) Thread (0,2) Thread (1,2) Thread (2,2)
Computing on Graphical Processing Units (GPUs) • To be efficient the code needs to take advantage of fine grain parallelism so as to execute 1000s of threads in parallel. • GPU code: • Programming level: • OpenCL, CUDA, CUDA Fortran (PGI) … • Best performance, but require complete rewrite • Directive based approach: • PGI, OpenMP-acc, HMPP (CAPS) • Smaller modifications to original code • The resulting code is still understandable by Fortran programmers and can be easily modified • Possible performance sacrifice with respect to CUDA code • No standard for the moment • Data transfer time between host and GPU may strongly reduce the overall performance
Phys. parametrization Dynamic Microphysics Turbulence Radiation I/O GPU GPU GPU GPU Running COSMO with GPUs 1) Simple accelerator approach: Kernels and data launched for each part of the code. • The GPU gains may be strongly reduce by large back and forth data transfers.
Running COSMO with GPUs Phys. parametrization Dynamic Microphysics Turbulence Radiation I/O GPU 2) Data remain on device, only send to CPU for I/O and communication • Strongly reduces device-host data transfer time (1 per time step) • Possible within the PGI-directive framework • Arrays declared on the GPU can be directly passed from the dynamical core (CUDA) to the physical parametrization (directives) without requiring intermediate copy to the CPU Directives CUDA
Outline Computing with GPUs GPU implementation using PGI-directives The example of the microphysics parametrization Summary
GPU implementation using PGI directives • Kernel generated at compilation time by adding directives in the code.Example of a matrix multiply to be compiled for an accelerator!$acc regiondo k = 1,n1 do i = 1,n3 c(i,k) = 0.0 do j = 1,n2 c(i,k) = c(i,k) + a(i,j) * b(j,k) enddo enddo enddo!$acc end region • Grid and block sizes are automatically set by the compiler or can be manually tuned using the parallel and vector keywords • Mirror and reflected keywords enable to declare GPU resident data arrays, thus avoiding data transfer between multiple kernel calls. • Based on other codes experiences (WRF, fluid dynamics) 1, directly adding directives to existing code may not be very efficient : still requires some re-writing to get better performance (loop reordering …) • Limitations : calls to subroutines within acc region need to be inlined, … 1http://www.pgroup.com/resources/accel.htm
!$acc region do i=1,N!init do k=1,nlev a(i,k)=0.0D0end do ! first layer a(i,1)=0.1D0 ! vertical computationdo k=2,nleva(i,k)=0.95D0*a(i,k-1)+exp(-2*a(i,k)**2)*a(i,k)end doend do !$acc end region i is the outer most loop nlev=60, N=10000 Execution time : 574 μs Execution time : 192 μs The stride-1 index loop should be the most outer loop to fully benefit from the vector-type parallelization. Importance of loop re-ordering Typical example for column based physical parametrization:- i is the parallel direction !$acc region!init do k=1,nlevdo i=1,N a(i,k)=0.0D0end doend do ! first layerdo i=1,N a(i,1)=0.1D0end do ! vertical computationdo k=2,nlevdo i=1,Na(i,k)=0.95D0*a(i,k-1)+exp(-2*a(i,k)**2)*a(i,k)end doend do !$acc end region
Outline Computing with GPUs GPU implementation using PGI-directives The example of the microphysics parametrization Summary
Test case: Microphysics parametrization(two-category ice scheme) • Calculates the rates of change of temperature, cloud water, cloud ice, water vapour, rain and snow due to cloud microphysical processes. • The microphysics contains most features of physical parametrizations: column based, vertical integration, math. intrinsic (log, exp…) → Compute bound . • 6% of the total computation time is spent in microphysics computation. • The directives are tested using a stand alone version of the microphysics. • Validity of GPU results are checked using reference CPU outputs.
Different implementations Version 1 (v1) → Direct implementation: • Few changes required; actual structure of the code is kept • Version 2 (v2) → Optimized for GPU: • Modifications in the routine: • Move the most inner loop outside (Parallel loop over stride-1 index) • Remove masks calculation (used for vectorization) • Scalarized intermediate matrices → new scalar variables may be assigned to register
Comparison with CPU results • Test case nx x ny x nz= 80 x 60 x 60, nstep = 100 • GPU code version 1 and 2 are compared with a reference mpi-parallel code running on AMD 2.6 GHZ Opteron Istanbul (6 cores) • 2010-09-18 12:00z+3h • Fermi card (C2070), using double precision
Using Fermi card and double precision real • 10x speed up achieved with Fermi card and code version 2. • Based on theoretical peak performance from 6 cores Opteron and Fermi card, one would expect a 9x speed up. • Only 2x speed up when taking data transfer into account (data transfer time is ~2s while execution time is ~0.5s) • Version 2 code is about 6x faster than version 1
Summary • GPUs are massively parallel hardware which can provide much higher computational power than CPU for comparable power and price • A project is currently carried out to port the full COSMO code to such architecture, using CUDA for the dynamical core and a directive based approach for the parametrizations • Porting of the microphysics subroutine to GPU was successfully carried out using PGI directive • Speed up using Fermi card and double precision reals with respect to reference MPI CPU code running on 6 cores AMD Opteron: • 10x without data transfer • 2x when considering data transfer • The large overhead of data transfer (4x execution time) shows that going to GPU is only viable if more computation is done (i.e all physics or all physics + dynamic) on the device between two data transfers. • Optimized code for GPU 6x time faster than direct GPU implementation: it is essential to reorder loops to take advantage of the synchronized parallelisation.
Next steps • GPU implementation and performance evaluation of other physical parametrizations in stand-alone code: • Radiation : Done, but awaiting for PGI bug-fix • Turbulence • Actual implementation in COSMO: • Introduction of ICON physical parametrization, with new data structure: t(nproma, ke, nblock). • PGI directives in COSMO. GPU – CPU version will have different loop order, what is the best solution ? (ex: #ifdef , pre-processing …)
y Horizontal x,y plan Block 3 Block 2 Block 1 x nproma Data structure • Considering data format t(nvec,nz,nblock), with nblock=(nx x ny)/nvec.
Mask for vectorization Actual computation Test case: One moment bulk microphysical parametrization(two-category ice scheme) • Calculates the rates of change of temperature, cloud water, cloud ice, water vapour, rain and snow due to cloud microphysical processes. • The microphysics contains most features of physical parametrizations: column based, vertical integration, math. intrinsic (log, exp…) → Compute bound . • 6% of the total computation time is spent in microphysics computation. The hydci_pp subroutine : Do k=1,nz ! vertical loop ! Check for existence of rain and snow Do i,j=1,nhorizontal !horizontal loop if rain(i,j,k) THEN ic1=ic1+1 idx1(ic1)=i ; idx2(ic2)=j …. ! Compute changes for grid point with rain and snow Do i1d=1,ic1 !horizontal loop i = idx1(i1d); j = jdx1(i1d) compute(i,j,k) ! search for cloud ….
!$acc region do kernel, parallel, vector( nv1 ) & !$acc private(zpkr,zpks,zprvr,zprvs,zvzr,zvzs) & Determine grid and block size 1D grid and block in this example DO ib=1,nblock DO k=1,nz Do i=1,nvec microphysics computation (i,k,ib) Different implementations Version 1 (v1) → Direct implementation: • Few changes required, mostly keep the actual structure of the code, in particular the optimisations for vector machine. • only one parallel loop over iblock (3rd dimension) • to maximize the level of parallelisation nvec is here set to 1 • No parallel loop over inner most index : does not take advantage of the vector type parallelisation • Optimal execution time for nv1=128
Synchronous parallel thread (vector) access contiguous memory Different implementations Version 2 (v2) → Optimized for GPU: • Important changes in the routine: • Move the most inner loop outside levels (k) loop • Remove masks calculation (used for vectorization) • Scalarized intermediate matrices → new scalar variables may be assigned to register • Two parallel loops !$acc region do parallel, vector( nv1 ) DO ib=1,nblock !$acc do kernel, vector( nv2 ) Do i=1,nvec DO k=1,nz computation (i,k,ib) • Optimal execution time for nv1=nv2=16 and nvec=16
Version 1 !$acc region do kernel, parallel, vector(128) & !$acc private(zpkr,zpks,zprvr,zprvs,zvzr,zvzs) & !$acc private(zcrim,zcagg,zbsdep,zvz0s,zn0s) & !$acc private(z1orhog,zrho1o2,zqrk,zqsk) & !$acc private(zdtdh,zzar,zzas) & !$acc private(ic1, ic2, ic3, ic4, ic5, ic6) & !$acc private(i,j,idx1,jdx1,idx2,jdx2,idx3,jdx3,idx4,jdx4,idx5,jdx5,idx6,jdx6) & !$acc private(zeln7o8qrk,zeln27o16qrk,zeln13o8qrk,zeln3o16qrk,zeln13o12qsk,zeln5o24qsk,zeln2o3qsk) & !$acc private(zcsdep,zcidep,zcslam,scau,scac,snuc,scfrz,simelt,sidep,ssdep,sdau,srim,sshed,sicri,srcri,sagg,siau,ssmelt,sev,srfrz) & !$acc private(zqvsi,zims,zimr) & !$acc private(zqvt,zqct,zqit) & !$acc private(qrg,qsg,qvg,qcg,qig,tg,ppg,rhog) & !$acc private(zcorr) & !$acc private(zpres,zdummy) loop_over_blocks: DO ib=1,nblock ! ********************************************************************* ! Loop from the top of the model domain to the surface to calculate the ! transfer rates and sedimentation terms ! ********************************************************************* ! Delete precipitation fluxes from previous timestep !CDIR BEGIN COLLAPSE prr_gsp (:,:,ib) = 0.0_ireals prs_gsp (:,:,ib) = 0.0_ireals zpkr (:,:) = 0.0_ireals loop_over_levels: DO k = 1, ke IF ( ildiabf_lh==1 ) THEN ! initialize temperature increment due to latent heat tinc_lh(:,:,k,ib) = tinc_lh(:,:,k,ib) - t(:,:,k,ib) ENDIF ic1 = 0 ic2 = 0 DO j = jstartpar, jendpar DO i = istartpar, iendpar qrg = qr(i,j,k,ib) qsg = qs(i,j,k,ib) qvg = qv(i,j,k,ib)
Tuning the kernel schedule • Tesla (T10) card, using single precision computation • Test case nx x ny x nz= 100 x 100 x 60, nstep = 100 • Try different block sizes by changing the vector(nv1) argument • Optimal execution time for nv1=128, te = 2.88 s. • Additional data transfer time is td = 2.1 s
Output from the compiler Generating copyout(prr_gsp(:,:)) Generating copyout(prs_gsp(:,:)) Generating compute capability 1.3 binary 780, Loop is parallelizable 789, Loop is parallelizable Accelerator kernel generated 780, !$acc do parallel, vector(16) 789, !$acc do vector(16) Cached references to size [10] block of 'mma' Cached references to size [10] block of 'mmb' Using register for 'prr_gsp' Using register for 'prs_gsp' CC 1.3 : 64 registers; 100 shared, 556 constant, 36 local memory bytes; 25 occupancy
Version 2 !$acc region, parallel, vector(16) !$acc copyin(rho,p,mma,mmb,dz) & !$acc copy(qs,qr,tinc_lh,t,qi,qc,qv) & !$acc copyout( prr_gsp,prs_gsp) loop_over_blocks: DO ib=1,nblock !$acc do kernel, vector(16) loop_over_xdim: DO i = istartpar, iendpar ! Delete precipitation fluxes from previous timestep prr_gsp (i,ib) = 0.0_ireals prs_gsp (i,ib) = 0.0_ireals zpkr = 0.0_ireals zpks = 0.0_ireals zprvr = 0.0_ireals zprvs = 0.0_ireals zvzr = 0.0_ireals zvzs = 0.0_ireals ! ********************************************************************* ! Loop from the top of the model domain to the surface to calculate the ! transfer rates and sedimentation terms ! ********************************************************************* loop_over_levels: DO k = 1, ke IF ( ildiabf_lh==1 ) THEN ! initialize temperature increment due to latent heat tinc_lh(i,k,ib) = tinc_lh(i,k,ib) - t(i,k,ib) ENDIF
Tuning the kernel schedule • vector(nv1), vector(nv2) arguments, and data format nvec can now be changed • Optimal execution time for nv1=nv2=16 and nvec=16, te = 0.64 s. • Speed up compare to version 1 is 4.5 • Data transfer time is again about 2 s, i.e. 3 time larger than execution time
Output from the compiler Generating copyout(prr_gsp(1:ie,1,1:nblock)) Generating compute capability 1.3 binary 791, Loop is parallelizable Accelerator kernel generated 791, !$acc do parallel, vector(256) Cached references to size [10] block of 'mma' Cached references to size [10] block of 'mmb' CC 1.3 : 64 registers; 100 shared, 1284 constant, 0 local memory bytes; 25 occupancy
Scaling with system size N=nx x ny nx x ny =100 x 100 not enough parallelism