Download
1 / 59
590 likes | 725 Views
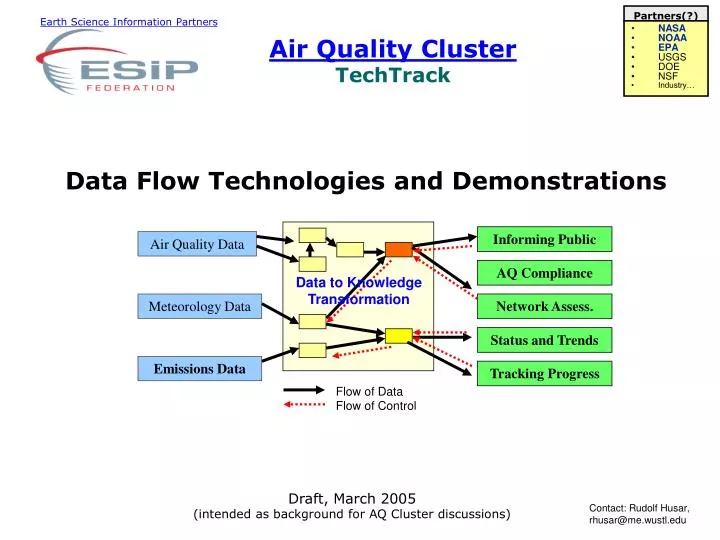
Informing Public. Air Quality Data. AQ Compliance. Data to Knowledge Transformation. Meteorology Data. Network Assess. Status and Trends. Emissions Data. Tracking Progress. Flow of Data. Flow of Control. Partners(?). NASA NOAA EPA USGS DOE NSF Industry….

E N D
Informing Public Air Quality Data AQ Compliance Data to Knowledge Transformation Meteorology Data Network Assess. Status and Trends Emissions Data Tracking Progress Flow of Data Flow of Control Partners(?) • NASA • NOAA • EPA • USGS • DOE • NSF • Industry… Earth Science Information Partners Air Quality ClusterTechTrack Data Flow Technologies and Demonstrations Draft, March 2005 (intended as background for AQ Cluster discussions) Contact: Rudolf Husar, rhusar@me.wustl.edu
Information ‘Refinery’ Value Chain Info. Quality Data Information Informing Knowledge Productive Knowledge Action Analyzing Separating Evaluating Interpreting Synthesizing Judging Options Quality Advantages Disadvantages Deciding Matching goals Compromising Bargaining Deciding Organizing Grouping Classifying Formatting Displaying Transform. Processes e.g. WG Reports Examples e.g. Langley IDEA, FASTNET, Forecast Modeling e.g. RPO Manager e.g. DAAC ESIP – Facilitation ? Sates, EPA, International Type of People: Engineers, Analysts, Decision Makers Machine To Human decision making Value Configuration: Chain, Network, Shop…Combination Info Quantity: petabytest to bytes Value Chain Based on Taylor, 1986: Value-Added Processes in Information Systems
Forecast AQ Identify Problems Change Behavior Set Standards Track Progress Scientists Find Data Gaps Public Research Env. Managers Set Funding Policy Makers Set Policy Fill Data Gaps Actions Analysis Audiences
Forecast AQ Identify Problems Change Behavior Set Standards Track Progress Scientists Find Data Gaps Public Research Env. Managers Set Funding Policy Makers Set Policy AQ Analysis–to-Actions • AQ decision-making is Analysis Decision Makers Actions
Track Progress Find Data Gaps Identify Problems Forecast AQ Analysis Set Standards Public Env. Managers Scientists Audiences Policy Makers Change Behavior Fill/Fund Data Gaps Set Funding Research Actions Set Policy
Assess EPA Progress Assess Indicators/ Gaps Establish Baseline Public Change Behavior Analysis Identify Emerging Issues Environmental Managers Decision Makers Scientists Policy Makers Fill/Fund Data Gaps Funding Decisions Decisions Research Make Better Decisions Policy Setting
Assess EPA Progress Assess Indicators/ Gaps Identify Emerging Issues Scientists Research Analyses Establish Baseline Public Environmental Managers Audiences Policy Makers Change Behavior Fill/Fund Data Gaps Funding Decisions Uses Make Better Decisions Policy Setting
Data Flow & Processing in AQ Management Data ‘Refining’ Processes Filtering, Aggregation, Fusion Primary Data Diverse Providers AQ Management Reports ‘Knowledge’ Derived from Data AQ DATA EPA Networks IMPROVE Visibility Satellite-PM Pattern Status and Trends AQ Compliance METEOROLOGY Met. Data Satellite-Transport Forecast model Network Assess. Exposure Assess. EMISSIONS National Emissions Local Inventory Satellite Fire Locs Tracking Progress
Informing Public AQ DATA AQ Compliance Data to Knowledge Transformation METEOROLOGY Network Assess. Status and Trends EMISSIONS DATA Tracking Progress Flow of Data Flow of Control Data Flow and Flow Control in AQ Management Provider Push User Pull Data are supplied by the provider and exposed on the ‘smorgasbord’ However, the choice of which data is used is made by the user Thus, data consumers, providers and mediators together form the info system
Air Quality Data Use(EPA Ambient Air Monitoring Strategy, 2004)
A Sample of Datasets Accessible through ESIP MediationNear Real Time (~ day) It has been demonstrated (project FASTNET) that these and other datasets can be accessed, repackaged and delivered by AIRNow through ‘Consoles’ MODIS Reflectance MODIS AOT TOMS Index MODIS Fire Pix GOES AOT GOES 1km Reflec NEXTRAD Radar NWS Surf Wind, Bext NRL MODEL
Web Services • A Web service is a software for interoperable machine-to-machine interaction over a network. • It has an interface described in a machine-processable format (specifically WSDL). • Web services communicate using SOAP-messages, • Typically conveyed using HTTP with an XML serialization in using Web-related standards.
AQ Data and Analysis: Challenges and Opportunities • Shift from primary to secondary pollutants. Ozone and PM2,5 travel 500 + miles across state or international boundaries and their sources are not well established • New Regulatory approach. Compliance evaluation based on ‘weight of evidence’ and tracking the effectiveness of controls • Shift from command & control to participatory management. Inclusion of federal, state, local, industry, international stakeholders. Challenges • Broader user community. The information systems need to be extended to reach all the stakeholders ( federal, state, local, industry, international) • A richer set of data and analysis. Establishing causality, ‘weight of evidence’, emissions tracking requires more data and air quality analysis Opportunities • Rich AQ data availability. Abundant high-grade routine and research monitoring data from EPA, NASA, NOAA and other agencies are now available. • New information technologies. DBMS, data exploration tools and web-based communication now allows cooperation (sharing) and coordination among diverse groups.
The Researcher’s Challenge “The researcher cannot get access to the data; if he can, he cannot read them; if he can read them, he does not know how good they are; and if he finds them good he cannot merge them with other data.” Information Technology and the Conduct of Research: The Users View National Academy Press, 1989 • These resistances can be overcome through • A catalog of distributed data resources for easy data ‘discovery’ • Uniform data coding and formatting for easy access, transfer and merging • Rich and flexible metadata structure to encode the knowledge about data • Powerful shared tools to access, merge and analyze the data
Recap: Harnessing the Winds • Secondary pollutants along with more open environmental management style are placing increasing demand on data analysis. Meanwhile, rich AQ data sets and the computer and communications technologies offer unique opportunities. • It appears timely to consider the development of a web-based, open, distributed air quality data integration, analysis and dissemination system. • The challenge is learn how to harness the winds of change as sailors have learned to use the winds for going from A to B
Uniform Coding and Formatting of Distributed Data • Data are now easily accessible through standard Internet protocols, but the coding and formatting of the data is very heterogeneous • On the other hand data sharing is most effective if the codes/formats/protocols are uniform (e.g. the Web formats and protocols ) • Re-coding and reformatting all the heterogeneous data into universal form in their respective server is unrealistic • An alternative is enrich the heterogeneous data with uniform coding along the way from the provider to the user. • A third party ‘proxy’ server can perform the necessary homogenization with the following benefits: • The data user interfaces with a simple universal data query and delivery system (interface, formats..) • The data provider does not need to change the system; gets additional security protection since the data data accessed by the proxy • Reduced data flow resistances results in increased overall data flow and data usage.
DataFed Servcies • Dvoy Services offer a homogeneous, read-only access mechanism to a dynamically changing collection of heterogeneous, autonomous and distributed information sources. • Data access uses a global multidimensional schema consisting of spatial, temporal and parameter dimensions, suitable for data browsing and online analytical processing, OLAP. The limited query capabilities yield slices through the spatio-temporal data cubes. • The main software components of Dvoy are wrappers, which encapsulate sources and remove technical heterogeneity, and mediators, which resolve the logical heterogeneity. • Wrapper classes are available for geo-spatial (incl. satellite) images, SQL servers, text files,etc. The mediator classes are implemented as web services for uniform data access, transformation and portrayal.
DVOY Interfaces Data Input • Data input Data Output - Browser • The DVOY interface is composed of data viewers and controllers, all displayed on a webpage • The web services and the preparation of the webpage interface is through .NET(Microsoft) • The graphic data display on the webpage uses an SVG plugin (Adobe) • The DVOY controls are linked to the SVG plugin and the .NET through client-side JavaScript Data Output – Web Service • The DVOY outputs are XML formatted datasets suitable for chaining with processing or rendering services
NSF-NOAA-EPA/EMAP (NASA)? Project:Real-Time Aerosol Watch System Real-Time Virtual PM Monitoring Dashboard. A web-page for one-stop access to pre-set views of current PM monitoring data including surface PM, satellite, weather and model data. Virtual Workgroup Website. An interactive website which facilitates the active participation of diverse members in the interpretation, discussion, summary and assessment of the on-line PM monitoring data. Air Quality Managers Console. Helps PM managers make decisions during major aerosol events; delivers a subset of the PM data relevant to the AQ managers, including summary reports prepared by the Virtual workgroups.
Dvoy Federated Information System • Dvoy offers a homogeneous, read-only access mechanism to a dynamically changing collection of heterogeneous, autonomous and distributed information sources. • Data access uses a global multidimensional schema consisting of spatial, temporal and parameter dimensions • The uniform global schema is suitable for data browsing and online analytical processing, OLAP • The limited global query capabilities yield slices along the spatial, temporal and parameter dimensions of the multidimensional data cubes.
Mediator-Based Integration Architecture (Wiederhold, 1992) • Software agents (mediators) can perform many of the data integration chores • Heterogeneous sources are wrapped by translation software local to global language • Mediators (web services) obtain data from wrappers or other mediators and pass it on … • Wrappers remove technical, while mediators resolve the logical heterogeneity • The job of the mediator is to provide an answer to a user query (Ullman, 1997) • In database theory sense, a mediator is a view of the data found in one or more sources User Query View Busse et. al, 1999 Service Service Wrapper Wrapper
Data Chain 2 Chain 1 Service Control Chain 3 Chain 1 Data Chain 3 Chain 2 Catalog Data Service User Value-Added Processing in Service Oriented Architecture Data, services and users are distributed throughout the network Users compose data processing chains form reusable services Intermediate data are also exposed for possible further use Chains can be linked to form compound value-adding processes Peer-to-peer network representation Service chain representation User Tasks: Find data and services Compose service chains Expose output User Carries less Burden In service-oriented peer-to peer architecture, the user is aided by software ‘agents’
Dvoy Federated Information System • Dvoy offers a homogeneous, read-only access mechanism to a dynamically changing collection of heterogeneous, autonomous and distributed information sources. • Data access uses a global multidimensional schema consisting of spatial, temporal and parameter dimensions • The uniform global schema is suitable for data browsing and online analytical processing, OLAP • The limited global query capabilities yield slices along the spatial, temporal and parameter dimensions of the multidimensional data cubes.
Architecture of DATAFED Federated Data SystemAfter Busse et. al., 1999 • The main software components of Dvoy are wrappers, which encapsulate sources and remove technical heterogeneity, and mediators, which resolve the logical heterogeneity. • Wrapper classes are available for geo-spatial (incl. satellite) images, SQL servers, text files,etc. The mediator classes are implemented as web services for uniform data access to n-dimensional data.
Integration Architecture (Ullman, 1997) • Heterogeneous sources are wrapped by software that translates between the sources local language, model and concepts and the shared global concepts • Mediators obtain information from one or more components (wrappers or other mediators) and pass it on to other mediators or to external users. • In a sense, a mediator is a view of the data found in one or more sources; it does not hold the data but it acts as it it did. The job of the mediator is to go to the sources and provide an answer to the query. Information Integration Using Logical ViewsSource Lecture Notes In Computer Science; Vol. 1186 archiveProceedings of the 6th International Conference on Database Theory
Referencing Ullman(1) Source integration for data warehousing The main goal of a data warehouse is to provide support for data analysis and management's decisions, a aspect in design of a data warehouse system is the process of acquiring the raw data from a set of relevant information sources. We will call source integration system the component of a data warehouse system dealing with this process. The goal of a source integration system is to deal with the transfer of data from the set of sources constituting the application-oriented operational environment, to the data warehouse. Since sources are typically autonomous, distributed, and heterogeneous, this task has to deal with the problem of cleaning, reconciling, and integrating data coming from the sources. The design of a source integration system is a very complex task, which comprises several different issues. The purpose of this chapter is to discuss the most important problems arising in the design of a ource integration system, with special emphasis on schema integration, processing queries for data integration, and data leaningand reconciliation. Data integration under integrity constraints Data integration systems provide access to a set of heterogeneous, autonomous data sources through a so-called global schema. There are basically two approaches for designing a data integration system. In the global-as-view approach, one defines the elements of the global schema as views over the sources, whereas in the local-as-view approach, one characterizes the sources as views over the global schema. It is well known that processing queries in the latter approach is similar to query answering with incomplete information, and, therefore, is a complex task. On the other hand, it is a common opinion that query processing is much easier in the former approach. In this paper we show the surprising result that, when the global schema is expressed in the relational model with integrity constraints, even of simple types, the problem of incomplete information implicitly arises, making query processing difficult in the global-as-view approach as well. We then focus on global schemas with key and foreign key constraints, which represents a situation which is very common in practice, and we illustrate techniques for effectively answering queries posed to the data integration system in this case. MedMaker: A Mediation System Based on Declarative Specifications Ullman & co: Mediators are used for integration of heterogeneous information sources. We present a system for declaratively specifying mediators. It is targeted for integration of sources with unstructured or semi-structured data and/or sources with changing schemas. We illustrate the main features of the Mediator Specification Language (MSL), show how they facilitate integration, and describe the implementation of the system that interprets the MSL specifications Mediators in the Architecture of Future Information Systems Gio Wiederhold For single databases, primary hindrances for end-user access are the volume of data that is becoming available, the lack of abstraction, and the need to understand the representation of the data. When information is combined from multiple databases, the major concern is the mismatch encountered in information representation and structure. Intelligent and active use of information requires a class of software modules that mediate between the workstation applications and the databases. It is shown that mediation simplifies, abstracts, reduces, merges, and explains data. A mediator is a software module that exploits encoded knowledge about certain sets or subsets of data to create information for a higher layer of applications. A model of information processing and information system components is described. The mediator architecture, including mediator interfaces, sharing of mediator modules, distribution of mediators, and triggers for knowledge maintenance, are discussed.
Referencing Ullman (2) Extracting information from heterogeneous information sources using ontologically specified target views Being deluged by exploding volumes of structured and unstructured data contained in databases, data warehouses, and the global Internet, people have an increasing need for critical information that is expertly extracted and integrated in personalized views. Allowing for the collective efforts of many data and knowledge workers, we offer in this paper a framework for addressing the issues involved. In our proposed framework we assume that a target view is specified ontologically and independently of any of the sources, and we model both the target and all the sources in the same modeling language. Then, for a given target and source we generate a target-to-source mapping, that has the necessary properties to enable us to load target facts from source facts. The mapping generator raises specific issues for a user's consideration, but is endowed with defaults to allow it to run to completion with or without user input. The framework is based on a formal foundation, and we are able to prove that when a source has a valid interpretation, the generated mapping produces a valid interpretation for the part of the target loaded from the source Secure mediation: requirements, design, and architecture In mediated information systems clients and various autonomous sources are brought together by mediators. The mediation paradigm needs powerful and expressive security mechanisms considering the dynamics and conflicting interests of the mediation participants. Firstly, we discuss the security requirements for mediation with an emphasis on confidentiality and authenticity. We argue for basing the enforcement of these properties on certified personal authorization attributes rather than on identification. Using a public key infrastructure such personal authorization attributes can be bound to asymmetric encryption keys by credentials. Secondly, we propose a general design of secure mediation where credentials are roughly used as follows: clients show their eligibility for receiving requested information by the contained personal authorization attributes, and sources and the mediator guarantee confidentiality by using the contained encryption keys. Thirdly, we refine the general design for a specific approach to mediation, given by our prototype of a Multimedia Mediator, MMM. Among other contributions, we define the authorization model and the specification of query access authorizations within the framework of ODL, as well as the authorization and encryption policies for mediation, and we outline the resulting security architecture of the MMM. We also analyze the achievable security properties including support for anonymity, and we discuss the inevitable tradeoffs between security and mediation functionality Research Commentary: An Agenda for Information Technology Research in Heterogeneous and Distributed Environments Application-driven, technology-intensive research is critically needed to meet the challenges of globalization, interactivity, high productivity, and rapid adaptation faced by business organizations. Information systems researchers are uniquely positioned to conduct such research, combining computer science, mathematical modeling, systems thinking, management science, cognitive science, and knowledge of organizations and their functions. We present an agenda for addressing these challenges as they affect organizations in heterogeneous and distributed environments. We focus on three major capabilities enabled by such environments: Mobile Computing, Intelligent Agents, and Net-Centric Computing. We identify and define important unresolved problems in each of these areas and propose research strategies to address them.
IS Interoperability Information systems interoperability: What lies beneath? A comprehensive framework for managing various semantic conflicts is proposed - provides a unified view of the underlying representational and reasoning formalism for the semantic mediation process. The framework is used for automating the detection and resolution of semantic conflicts among heterogeneous information sources. We define several types of semantic mediators to achieve semantic interoperability. A domain-independent ontology is used to capture various semantic conflicts. A mediation-based query processing technique is developed to provide uniform and integrated access to the multiple heterogeneous databases. A usable prototype is implemented as a proof-of-concept for this work. Finally, the usefulness of our approach is evaluated using three cases in different application domains. Various heterogeneous datasets are used during the evaluation phase. The results of the evaluation suggest that correct identification and construction of both schema and ontology-schema mapping knowledge play very important roles in achieving interoperability at both the data and schema levels Mediation: Syntactic – Web services Semantic Dimensional - Global Data Model Ontotlogy, name spaces Semantic mediation is for content. Dimensional mediation is by the wrappers!! • In a recent research commentary March et al. [2000] identified semantic interoperability as one of the most important research issues and technical challenges in heterogeneous and distributed environments. • Semantic interoperability is the knowledge-level interoperability that provides cooperating businesses with the ability to bridge semantic conflicts arising from differences in implicit meanings, perspectives, and assumptions. Semantic interoperability creates semantically compatible information environment based on the agreed concepts among the cooperating entities. • Syntactic interoperability, is the application-level interoperability that allows multiple software components to cooperate even though their implementation languages, interfaces, and execution platforms are different. Emerging standards, such as XML and Web Services based on SOAP (Simple Object Access Protocol), UDDI (Universal, Description, Discovery, and Integration), and WSDL (Web Service Description Language), can resolve many application-level interoperability problems through technological means.
Referencing Ullman (3) Federated Information Systems: Concepts, Terminology and Architectures (1999) Busse & co: We are currently witnessing the emerging of a new generation of software systems: Federated information systems. Their main characteristic is that they are constructed as an integrating layer over existing legacy applications and databases. They can be broadly classified in three dimensions: the degree of autonomy they allow in integrated components, the degree of heterogeneity between components they can cope with, and whether or not they support distribution. Whereas the communication an IDB: Toward the Scalable Integration of Queryable Internet Data Sources As the number of databases accessible on the Web grows, the ability to execute queries spanning multiple heterogeneous queryable sources is becoming increasingly important. To date, research in this area has focused on providing semantic completeness, and has generated solutions that work well when querying over a relatively small number of databases that have static and well-defined schemas. Unfortunately, these solutions do not extend to the scale of the present Internet, let alone the Building Intelligent Web Applications Using Lightweight Wrappers (2000 The Web so far has been incredibly successful at delivering information to human users. So successful actually, that there is now an urgent need to go beyond a browsing human. Unfortunately, the Web is not yet a well organized repository of nicely structured documents but rather a conglomerate of volatile HTML pages. To address this problem, we present the World Wide Web Wrapper Factory (W4F), a toolkit for the generation of wrappers for Web sources, that oers: (1) an expressive language to specify the extraction of complex structures from HTML pages; (2) a declarative mapping to various data formats like XML; (3) some visual tools to make the engineering of wrappers faster and easier. A Unified Framework for Wrapping, Mediating and Restructuring Information from the Web The goal of information extraction from the Web is to provide an integrated view on heterogeneous information sources via a common data model and query language. A main problem with current approaches is that they rely on very different formalisms and tools for wrappers and mediators, thus leading to an "impedance mismatch" between the wrapper and mediator level. In contrast, our approach integrates wrapping and mediation in a unified framework based on an object-oriented data model which Wrappers translate data from different local languages to common format, mediators provide integrated VIEW of the data. Multi-Mediator Browser With the mediator/wrapper approach to data integration [Wie92] wrappers define interfaces to heterogeneous data sources while mediators are virtual database layers where queries and views to the mediated data can be defined. The mediator approach to data integration has gained a lot of interest in recent year [BE96,G97,HKWY97,LP97,TRV98]. Early mediator systems are central in that a single mediator database server integrates data from several wrapped data sources. In the work presented here, the integration of many sources is facilitated through a scalable mediator architecture where views are defined in terms of object-oriented (OO) views from other mediators and where different wrapped data sources can be plugged in. This allows for a component-based development of mediator modules, as early envisioned in [Wie92].
Distributed Programming: Interpreted and Compiled • Web services allow processing of distributed data • Data are distributed and maintained by their custodians, • Processing nodes (web-services) are also distributed • ‘Interpreted’ web-programs for data processing can be created ad hoc by end users • However, ‘interpreted’ web programs are slow, fragile and uncertain • Slow due to large data transfers between nodes • Fragile due to instability of connections • Uncertain due to failures of data provider and processing nodes • One solution is to ‘compile’ the data and processing services • Data compilation transforms the data for fast, effective access (e.g. OLAP) • Web service compilation combines processes for effective execution • Interpreted or compiled? • Interpreted web programs are simpler and up to date but slow, fragile, uncertain • Compiled versions are more elaborate and latent but also faster and more robust • Frequently used datasets and processing chains should be compiled and kept current
Point Access Point Grid Grid Render PtGrid Overlay Point Access Point Render Data Flow Control Flow Point Access Point Grid Grid Render PtGrid Overlay Point Render Interpreted and Compiled Service • Interpreted Service • Processes distributed • Data flow on Internet • Compiled Service • Processes in the same place • Data flow within aggregate service • Controllers, e.g. zoom can be shared
Services Program Execution:Reverse Polish Notation Writing the WS program: - Write the program on the command line of a URL call - Services are written sequentially using RPN - Replacements Connector/Adaptor: - Reads the service name from the command line and loads its WSDL - Scans the input WSDL - The schema walker populates the service input fields from: - the data on the command line - the data output of the upstream process - the catalog for the missing data Service Execution For each service Reads the command line, one service at a time Passes the service parameters to the above Connector/Adopter, which prepares the service Executes the service It also handles the data stack for RPN
Mediator-Based Integration Architecture (Wiederhold, 1992) • Software agents (mediators) can perform many of the data integration chores • Heterogeneous sources are wrapped by translation software local to global language • Mediators (web services) obtain data from wrappers or other mediators and pass it on … • Wrappers remove technical, while mediators resolve the logical heterogeneity • The job of the mediator is to provide an answer to a user query (Ullman, 1997) • In database theory sense, a mediator is a view of the data found in one or more sources User Query View Busse et. al, 1999 Service Service Wrapper Wrapper
An Application Program: Voyager Data Browser Controls • The web-programs consists of a stable core and adoptive input/output layers • The core maintains the state and executes the data selection, access and render services • The adoptive, abstract I/O layers connects the core to evolving web data, flexible displays and to the a configurable user interface: • Wrappers encapsulate the heterogeneous external data sources and homogenize the access • Device Drivers translate generic, abstract graphic objects to specific devices and formats • Ports connect the internal parameters of the program to external controls • WDSL web service description documents Ports Displays Data Sources App State Data Device Drivers Wrappers Flow Interpreter Core I/O Layer WSDL Web Services
Mediator Peers DataFed Topology: Mediated Peer-to-Peer Network, MP2P Mediated Peer-to Peer Network Broker maintains a catalog of accessible resources Peers find data and access instructions in the catalog Peers get resources directly from peer providers Source: Federal Standard 1037C Google Example: Finding Images on Network Topology Google catalogs the images related to Network Topology User selects an image from the cached image catalog User visits the provider web-page where the image resides
Generic Data Flow and Processing in DATAFED View Wrapper Abstract Data Access Process Data Portrayal/ Render Data Processed Data Portrayed Data Physical Data Abstract Data DataView 1 DataView 2 DataView 3 Physical Data Resides in autonomous servers; accessed by view-specific wrappers whichyield abstract data ‘slices’ Abstract Data Abstract data slices are requested by viewers; uniform data are delivered by wrapper services Processed Data Data passed through filtering, aggregation, fusion and other web services View Data Processed data are delivered to the user as multi-layer views by portrayal and overlay web services
Tight and Lose Coupled Programs They are self-contained, self-describing, modular applications that can be published, located, and invoked across the Web. Web services perform functions, which can be anything from simple requests to complicated business processes... SOA is the right mechanism—a transmission of sorts—for an IT environment in which data-crunching legacy systems must mesh with agile front-facing applications • Coupling is the dependency between interacting systems • Dependency can be real (the service one consumes) or artificial (language, platform…) • One can never reduce real dependency but itself is evolving • One can never get rid of artificial dependency but one can reduce artificial dependency or the cost of artificial dependency. • Hence, loose coupling describes the state when artificial dependency or the cost of artificial dependency has been reduced to the minimum.
The pathway to a service-oriented architectureBob Sutor, IBM • In an SOA world, business tasks are accomplished by executing a series of "services,“ • Services have well-defined ways of talking to them and well-defined ways in which they talk back • It doesn't really matter how a service is implemented, as long as it properly responds and offers the quality of service • The service must be secure, reliable and fast enough • SOA a suitable technology to use in an IT environment where software and hardware from multiple vendors is deployed • IBM identified four steppingstones on the path to SOA nirvana and its full business benefits • 1. Make applications available as Web services to multiple consumers via a middle-tier Web application server. • This is an ideal entry point for those wishing to deploy an SOA with existing enterprise applications • Target customer retention or operational efficiency projects • Work with multiple consumers to correctly define the granularity of your services • Pay proper attention to keeping the services and the applications loosely coupled. • 2. Choreography of web services • Create business logic outside the boundaries of any one application • Make new apps easy to adjust as business conditions or strategy require • Keep in mind asynchronous services and sequences of actions that don't complete successfully • Don’t forget managing the processes and services • 3. Leverage existing integration tools • leverage your existing enterprise messaging software; enterprise messaging and brokers • Web services give you an easy entry to SOA adoption • WS are not the gamut of what service orientation means; Modeling is likely required • Integration with your portal for "people integration" will also probably happen • 4. Be flexible, responsive on-demand business • Use SOA to gain efficiencies, better use of software and information assets, and competitive differentiation
ESIP AQ Cluster: Facilitate Better Use of AQ Information Providers maintain their private workspace and resources (data, tools, reports) Part of the private resources are computer-accessible for community use in the federation Data Info Users draw upon the rich resource pool to enable their projects, programs, agencies Shared (Federated) Resources Data, Services, Tools Other Feds, Portals The Federation aids resource (re)use: facilitation, interoperability, maintenance AQ Cluster Management Activities, Communication, Coord. Lead: S. Falke Shared Resources: Data, Services, Tools, Maintenance Lead: Community Sharing Infrastructure Architecture, Interop, Implementation Lead: R. Husar
The pathway to a service-oriented architecture Opinion by Bob Sutor, IBM Bob Sutor is IBM's director of WebSphere Infrastructure Software.DECEMBER 03, 2003 (COMPUTERWORLD) - I recently read through a large collection of analyst reports on service-oriented architecture (SOA) that have been published in the past year. I was pleasantly surprised at the amount of agreement among these industry observers and their generally optimistic outlook for the adoption of this technology. SOA is not really new -- by some accounts, it dates back to the mid-1980s -- but it's starting to become practical across enterprise boundaries because of the rise of the Internet as a way of connecting people and companies. Even though the name sounds very technical, it's the big picture behind the use of Web services, the plumbing that's now being used to tie together companies with their customers, suppliers and partners. In an SOA world, business tasks are accomplished by executing a series of "services," jobs that have well-defined ways of talking to them and well-defined ways in which they talk back. It doesn't really matter how a particular service is implemented, as long as it responds in the expected way to your commands and offers the quality of service you require. This means that the service must be secure, reliable and fast enough to meet your needs. This makes SOA a nearly ideal technology to use in an IT environment where software and hardware from multiple vendors is deployed. At IBM, we've identified four steppingstones on the path to SOA nirvana and its full business benefits. Unlike most real paths, this is one you can jump on at almost any point The first step is to start making individual applications available as Web services to multiple consumers via a middle-tier Web application server. I'm not precluding writing new Web services here, but this is an ideal entry point for those wishing to deploy an SOA with existing Java or Cobol enterprise applications, perhaps targeting customer retention or operational efficiency projects. You should work with multiple consumers to correctly define the granularity of your services, and pay proper attention to keeping the services and the applications using them loosely coupled. The second step involves having several services that are integrated to accomplish a task or implement a business process. Here you start getting serious about modeling the process and choreographing the flow among the services, both inside and outside your organization, that implement the process. The choreography is essentially new business logic that you have created outside the boundaries of any one application, therefore making it easier to adjust as business conditions or strategy require. As part of this, you will likely concern yourself with asynchronous services as well as compensation for sequences of actions that don't complete successfully. Your ability to manage the processes and services and their underlying implementations will start to become important as well. This entry point is really "service-oriented integration" and will probably affect a single department or a business unit such as a call center. If you already have an enterprise application integration infrastructure, you will most like enter the SOA adoption path at the third steppingstone. At this point, you are looking to use SOA consistently across your entire organization and want to leverage your existing enterprise messaging software investment. I want to stress here that proper SOA design followed by use of enterprise messaging and brokers constitutes a fully valid deployment of SOA. Web services give you an easy entry to SOA adoption, but they don't constitute the gamut of what service orientation means. Modeling is likely required at this level, and integration with your portal for "people integration" will also probably happen here if you didn't already do this at the previous SOA adoption point. The final step on the path is the one to which you aspire: being a flexible, responsive on-demand business that uses SOA to gain efficiencies, better use of software and information assets, and competitive differentiation. At this last level, you'll be able to leverage your SOA infrastructure to effectively run, manage and modify your business processes and outsource them should it make business sense to do so. You are probably already employing some SOA in your organization today. Accelerating your use of it will help you build, deploy, consume, manage and secure the services and processes that can make you a better and more nimble business.
Don Box, Microsoft • Integration in the Distributed Object Technology was by code injection. • This introduced deep technological dependency of the distributed objects • Web Services introduced protocol-based integration or service-orientation
Don Box, Microsoft • When we started working on SOAP in 1998, the goal was to get away from this model ofintegration by code injection that distributed object technology had embraced. Instead, we wanted an integration model that made as few possible assumptions about the other side of the wire, especially about the technology used to build the other side of the wire. We've come to call this style of integration protocol-based integration or service-orientation. Service-orientation doesn't replace object-orientation - I don't see the industry (or Microsoft) abandoning objects as the primary metaphor for building individual programs. I do see the industry (and Microsoft) moving away from objects as the primary metaphor for integrating and coordinating multiple programs that are developed, deployed and versioned independently, especially across host boundaries. In the 1990's, we stretched the object metaphor as far as we could, and through communal experience, we found out what the limits are. With Indigo, we're betting on the service metaphor and attempting to make it as accessible as humanly possible to all developers on our platform. How far we can "shrink" the service metaphor remains to be seen. Is it suitable for cross-process work? Absolutely. Will every single CLR type you write be a service in the future? Probably not - at some point you know where your integration points are and want the richer interaction you get with objects. • Code InjectionOne port-to-process mapping technique involves code injection, a technique where the mapping process writes code into the memory space of all running processes. Code injection is not only an unreliable method (incorrect and missing results can often occur, and many processes can't have code injected into their memory area anyway) but it is also a very dangerous practice (trojans even use it to bypass some personal firewalls) and can have adverse effects on the processes that have been injected, sometimes causing processes to malfunction or crash. In some cases, system instability and even blue-screens-of-death (BSOD) can result. Code injection usually fails on protected system services, and in many cases the code being injected is overwriting existing code. We advise against using such programs on your system for these reasons, or if you do use them then reboot your computer afterwards.
Data Processing in Service Oriented Architecture • Data Values • Immediacy • Quality • Lose Coupling of data • Open data processing – let competitive approaches deliver the appropriate products to the right place
OGC code Service Category Service class Description 0000 Human Interaction OGC web service [ROOT] Managing user interfaces, graphics, presentation. 1000 Human interaction Info. Management Managing and storage of metadata, schemas, datasets. 1100 Portrayal 1110 Geospatial viewer Workflow Services that support specific tasks or work-related activities. 1111 Animation Processing Data processing, computations; no data storage or transfer 1112 Mosaicing 1113 Perspective Communication Services that encode and transfer data across networks. 1114 Imagery Sys. Management Managing system components, applications, networks (access). 1120 Geospatial symbol editor 1130 Feature generalization editor 1200 Service interaction editor 1300 Registry browser 2000 Information Management 2100 Feature access 2200 Coverage access 2210 Real-time sensor 2300 Map access 2400 Gazetteer 2500 Registry 2600 Sensor access 2700 Order handling 3000 Workflow 3100 Chain definition 3200 Enactment 3300 Subscription 4000 Processing 4100 Spatial 4110 Coordinate conversion 4120 Coordinate transformation 4130 Representation conversion 4140 Orthorectification 4150 Subsetting 4160 Sampling 4170 Feature manipulation 4180 Feature generalization 4190 Route determination 41A0 Positioning 4200 Thematic 4210 Geoparameter calculation 4220 Thematic classification 4221 Unsupervised 4222 Supervised 4230 Change detection 4240 Radiometric correction 4250 Geospatial analysis 4260 Image processing 4261 Reduced resolution generation 4262 Image manipulation 4263 Image synthesis 4270 Geoparsing 4280 Geocoding 4300 Temporal 4310 Reference system transformation 4320 Subsetting 4330 Sampling 4340 Proximity analysis 4400 Metadata 4410 Statistical analysis 4420 Annotation 5000 Communication 5100 Encoding 5200 Format conversion 5300 Messaging 6000 System Management Major Service CategoriesAs envisioned by Open GiS Consortium (OGC)
SOAP and WSDL SOAP Envelope for message description and processing A set of encoding rules for expressing data types Convention for remote procedure calls and responses A binding convention for exchanging messages WSDL Message format Ports
Services in 500 words • Introduction • Search and Retrieve Web Service (SRW) and Search and Retrieve URL Service (SRU) are Web Services-based protocols for querying databases and returning search results. SRW and SRU requests and results are similar, their difference lies in the ways the queries and results are encapsulated and transmitted between client and server applications. • Basic "operations" • Both protocols define three and only three basic "operations": explain, scan, searchRetrieve. • explain. Explain operations are requests sent by clients as a way of learning about the server's database. At minimum, responses to explain operations return the location of the database, a description of what the database contains, and what features of the protocol the server supports. • scan. Scan operations enumerate the terms found in the remote database's index. Clients send scan requests and servers return lists of terms. The process is akin to browsing a back-of-the-book index where a person looks up a term in a book index and "scans" the entries surrounding the term. • searchRetrieve. - SearchRetrieve operations are the heart of the matter. They provide the means to query the remote database and return search results. Queries must be articulated using the Common Query Language. CQL queries range from simple freetext searches to complex Boolean operations with nested queries and proximity qualifications. Servers do not have to implement every aspect of CQL, but they have to know how to return diagnostic messages when something is requested but not supported. The results of searchRetrieve operations can be returned in any number of formats, as specified via explain operations. Examples might include structured but plain text streams or data marked up in XML vocabularies such as Dublin Core, MARCXML, MODS, etc. • Differences in operation • The differences between SRW and SRU lie in the way operations are encapsulated and transmitted between client and server as well as how results are returned. SRW is essentially as SOAP-ful Web service. Operations are encapsulated by clients as SOAP requests and sent to the server. Likewise, responses by servers are encapsulated using SOAP and returned to clients. • On the other hand, SRU is essentially a REST-ful Web Service. Parameters are encoded as name/value pairs in the query string of a URL. As such operations sent by SRU clients can only be transmitted via HTTP GET requests. The result of SRU requests are XML streams, the same streams returned via SRW requests sans the SOAP envelope. • Summary • SRW and SRU are "brother and sister" standardized protocols for accomplishing the task of querying databases and returning search results. If index providers were to expose their services via SRW and/or SRU, then access to these services would become more ubiquitous.
Lib Congress • SOAP Web Services (SWS) and URL Web Services (UWS) are protocols for querying and returning results from remote servers. The difference is in encapsulation of queries and results transmitted between clients and servers. • In SWS, the messages between the client and server are encapsulated in an XML SOAP envelope. • In UWS, the web service parameters are encoded as name/value pairs in the query string of a URL and transmitted via HTTP GET requests. The results are returned as XML streams or ASCII streams, without the SOPA envelope. • When providers expose their services via SWS or UWS, then the use of these services (data/processing/rendering, etc) can be become more ubiquitous.
REST Web Services • REST, unlike SOAP, doesn't require you to install a separate tool kit to send and receive data. Instead, the idea is that everything you need to use Web services is already available if you know where to look. HTTP lets you communicate your intentions through GET, POST, PUT, and DELETE requests. To access resources, you request URIs from Web servers. • Therefore, REST advocates claim, there's no need to layer the increasingly complicated SOAP specification on top of these fundamental tools. For more on REST, see the RESTwiki and Paul Prescod's pieces on XML.com. • There may be some community support for this philosophy. While SOAP gets all the press, there are signs REST is the Web service that people actually use. Since Amazon.com has both SOAP and REST APIs, they're a great way to measure usage trends. Sure enough, at OSCon, Jeff Barr, Amazon.com's Web Services Evangelist, revealed that Amazon handles more REST than SOAP requests. I forgot the exact percentage, but Tim O'Reilly blogged this number as 85%! The number I do remember from Jeff's talk, however, is 6, as in "querying Amazon using REST is 6 times faster than with SOAP". • The hidden battle between web services: REST versus SOAP • Is SOAP a washout? • Are more developers turning their backs on SOAP for Web services? Redmonk’s James Governor just posted this provocative thought at his MonkChips blogsite: • "Evidence continues to mount that developers can’ t be bothered with SOAP and the learning requirements associated with use of the standard for information interchange. It is often described as ‘lightweight’, but its RPC [remote procedure call] roots keep showing. …semantically rich platforms like flickr and Amazon are being accessed by RESTful methods, not IBM/MS defined ‘XML Web Services’ calls.“






















