Download

1 / 25
380 likes | 849 Views
רשתות נוירונים. בדגש על: BackPropagation. כמה עובדות מעניינות על המוח: מסת המוח של אדם בוגר נע לרוב בין 1,400 ל-1,650 גרם ונפחו הממוצע הוא כ-1,600 סמ"ק. המוח מהווה רק 2% ממסת גוף, אך צורך כ20% מזרם הדם, ומאספקת החמצן (בזמן מנוחה). המוח של הגברים שוקל כ-100 גרם יותר מזה של הנשים!!!

E N D
רשתות נוירונים בדגש על: BackPropagation
כמה עובדות מעניינות על המוח: • מסת המוח של אדם בוגר נע לרוב בין 1,400 ל-1,650 גרם ונפחו הממוצע הוא כ-1,600 סמ"ק. • המוח מהווה רק 2% ממסת גוף, אך צורך כ20% מזרם הדם, ומאספקת החמצן (בזמן מנוחה). • המוח של הגברים שוקל כ-100 גרם יותר מזה של הנשים!!! וכמות התאים בו גדולה ב4% מהכמות אצל הנשים. (אין ראיות לכך שהבדלים במשקל המוח משפיעים על מידת האינטליגנציה או על היכולת המנטלית. ישנן טענות, שאדם ממוצע משתמש רק ב-3 עד 10 אחוז מיכולת המוח שלו.) • מחצית מתאי העצב המרכיבים את מוחו של תינוק מתים בתוך השנה הראשונה, עת נותרים במוח 100 מיליארד נוירונים. 1.6L Subaru Engine
בהשוואות מסוימות בין המוח לבין מחשבים, יש שמחשבים את החישוב הבא: ישנם מיליארדי תאי עצב במוח האנושי; ההערכות משתנות, אך מדובר בערך ב־1014 תאים כאלו. מכיוון שזמן הרגיעה של תאים אלה הוא בערך 10 מילי-שנייה, מהירות החישוב היא בערך 100Hz. לפיכך לכל המוח יש עוצמה חישובית של בערך1014 פעולות לוגיות לשנייה. אפשר להשוות זאת למחשב PC עם מעבד של 64 ביט בתדירות של 3 ג'יגה-הרץ, המבצע 1013 פעולות לוגיות בשנייה. אך יש לזכור שלכל תא עצב יכולים להיות יותר מעשרת אלפים חיבורים, ולפיכך הם מעבדים של ~10000 ביט ולא 64. הידעת? כאשר חקרו את מוחו של אלברט איינשטיין לאחר מותו, התברר שמשקל מוחו היה ממוצע,אולם, מספר הקשרים בין הנוירונים שבו היה גבוהה בהרבה מהממוצע
רשתות מלאכותיות • יכולת זיהוי והבחנה • חיקוי המוח האנושי • הרשת עוברת תהליך לימוד • זיהוי דפוסים • פתרון של בעיות pattern
ערכי הקלט ערכי הקלט שכבת נוירונים - הקלט מטריצת משקולות שכבת נוירונים - הקלט שכבת נוירונים נסתרת מטריצת משקולות שכבת נוירונים - הפלט מטריצת משקולות ערכי הפלט שכבת נוירונים נסתרת מטריצת משקולות שכבת נוירונים - הפלט ערכי הפלט המודל כדי להעביר את תכונות הנוירון הביולוגי לנוירון מלאכותי – ממוחשב, מתבצעת הפשטה של מונח הנוירון, ולא ממומשים במלואם כל המנגנונים הביולוגים לפרטיהם. הנוירון הממוחשב הוא יחידת עיבוד פשוטה, המקבלת קלט, מבצעת עיבוד ומספקת פלט. הקלט הוא מערך של פלטים של נוירונים אחרים. הפלט הוא אות בינארי בעוצמה קבועה. עוצמת הקשר בין פלט כלשהו לבין נקודת קלט הינה בעלת "משקל", ומתארת את מידת השפעת תוצאת החישוב של נוירון אחד על נוירון אחר המקבל קלט ממנו. על מנת להפעיל את רשת הנוירונים, יש להגדיר את המשקולות בקשרים בין כל נוירון לשכנו. נשים לב כי ברשת מלאכותית, בשונה מהמוח, ניתן לחבר כל נוירון לשכנו,כאשר משקל "0" בקשר ביניהם יהווה בפועל נתק. המודל הפשוט ("המנוון"), מדבר על נוירון כמבצע פעולת סכימה פשוטה, המייצר קלט על פי נקודת סף(threshold) מוגדרת.
דוגמא להרצה (Forward Propagation) sum= 0.5 * 1 + 0.3 * 1 = 0.8 out = sigmoid(0.8) = 0.69 1 0.5 sum=0.097 out=0.476 0.3 -0.5 sum=0.5 out=0.62 n.sum=0.7 n.out=0.672 -0.2 0.4 0.5 0.3 0.4 0 0.6 0.7 sum=-0.1 out=0.475 0.7 0.5- 0.4 sum=0.8 out=0.683 -0.1 1 bias
הרשת כמערך שכבות • במודל מפושט זה הידע נמצא במשקלות. • כדי להשתמש ברשת יש לבצע תהליך לימוד – כוונון מהשקולות. • בהינתן רשת מאומנת החישוב מתבצע ע"י הזנת הקלטים לשכבת הקלט וקבלת התוצאה שחלחלה ברשת לשכבת הפלט. • החלחול, כאמור, מתבצע ע"י סיכם משוקלל ומעבר סף תגובה.
רשת המשתמשת בשכבה אחת , תוכל לפתור בעיות ליניאריות (דיסקרטיות) בלבד, לכן נדרוש רשת בעלת מס. שכבות > 1 וכל זה בשביל פתרון בעיות לא דיסקרטיות.
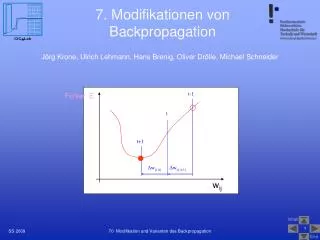
איך מאמנים רשת עצבית • לאחר שקובעים את מס' השכבות החבויות וגודל כל שכבה, יש צורך לקבוע את ערכי המשקולות כך שטעות הניבוי של הרשת תמוזער. • משטח הטעות ( error surface ) – כל אחת מהמשקולות (הפרמטרים החופשיים) תהווה מימד במרחב. המימד הנוסף יהיה טעות הרשת. • לכל קונפיגורציית משקלות אפשרית הטעות ניתנת לייצוג כמשטח במרחב זה. • מטרת תהליך הלימוד – למצאו את נקודת המינימום במשטח זה.
(w1,w2) (w1+w1,w2 +w2) גרדיאנט • בחשבון אינפיניטסימלי של מספר משתנים, גרדיאנט הינו וקטור של הנגזרות החלקיות .הדיפרנציאל שווה למכפלה הסקלרית של הגרדיאנט והשינוי בכל ציר
לימוד בשיטת Back Propagation (1) • זהו אלגוריתם הלימוד השימושי והידוע ביתר. • מתבסס על רעיון ה- gradient descent. • ז"א הליכה בצעדים קטנים (learning rate) בכיוון וקטור השיפוע.
לימוד בשיטת Back Propagation (2) • תהליך איטרטיבי: בכל איטרציה כל אחת מדוגמיות הלימוד מועברת דרך הרשת ומחושב ההבדל בין הפלט הרצוי למצוי (הטעות). • טעות זו יחד עם וקטור השיפוע של משטח הטעות משמשים לכוונון המשקלות ע"פ gradient descent. • עדכון זה מתבצע החל משכבת הפלט לאחור.
המבנה המתמטי של BP רצוי פחות מצוי האנרגיה של הטעות, כאשר C הם הנוירונים בOutput ממוצע תרומתו של כל נוירון לאנרגיה הכוללת של הטעות ,כאשר N הוא מספר הנוירונים אלגוריתם BP מחבר\מחסר את לכל משקולת לפי החלק היחסי של הנגזרת לפי
נגזרת מורכבת: *נגזרת של: *נגזרת של: *נגזרת של: *נגזרת של: קבוע הלימוד – נקבע בתחילת תהליך הלמידה , קבוע לכל הנוירונים. (סקלאר)
הוא הגרדיאנט. נבדיל בין 2 מקרים : כאשר מחושב על נוירון שנמצא בOutput ואז הוא תלוי בנגזרת והטעות כאשר מחושב על נוירון שנמצא בשכבות הפנימיות של הרשת ואז הוא תלוי בנגזרת ובסכום הטעויות שחושבו לפניו f’j(vj(n)) ej(n)
במקרה הפרטי של פונקצית אקטיבציה סיגמואיד נחזור לרגע לפונקצית האקטיבציה נגזור אותה ונקבל וכאשר משתמשים ב נקבל לפי הסיגמויד , המקסימום כאשר y=0.5, המינימום ב y=0,y=1 ולכן שינוי המשקלים הגדול יהיה מושפע מ"רוב" הנוירונים ולא במיעוט שנמצא בקצוות. בשביל נוירון בשכבת הOutput == בשביל כל נוירון בשכבה הפנימית קבוע קצב הלימוד (מומנטום)
קבוע הלימוד קצב הלימוד (מומנטום) לBP יש חסרון והוא – קצב לימוד איטי אם קטן, אם גדול ,קצב הלימוד יכול לטפס בצורה אקספוננציאלית ואז לפספס את המקסימום בעקומת הלימוד. בשביל לפתור את הבעיה , נוסיף את הקבוע הוא יקרא "מומנטום" (יהווה מין משקולת לקבוע הלימוד. מתי נדע שהרשת סיימה ללמוד?! • כאשר הנורמל האוקלידי של הגרדיאנט הגיע לערך מוסכם מראש • כאשר דלטא הטעות קטנה מספיק (מערך שנקבע מראש)
חישוב הטעות output = 0.672 error = 1-0.672 = 0.328 correct = 0.672* (1 - 0.672) * (1 -0.672) = 0.072296 (assume 1 was expected as output) sum=0.8 out=0.69 1 sum=0.097 out=0.476 0.5 -0.5 sum=0.5 out=0.62 0.3 -0.2 0.4 0.5 0.3 0.4 0 0.6 0.7 sum=-0.1 out=0.475 0.7 -0.5 0.4 sum=0.8 out=0.683 -0.1 1 bias LastNeuronError = DesiredOutput - Output LastNeuronCorrect = Output * (1-Output) * LastNeuronError
out=0.69 =-0.5 * 0.00901 + 0.3 * 0.01095 = -0.00122 correct = -0.00122 * (0.69 * (1 - 0.69)) = -0.00026 out = 0.476 = 0.036148 correct = 0.00901 out = 0.62 = 0.01017 correct = 0.00239 out = 0.683 = 0.0506072 correct = 0.01095 out = 0.475 = 0.00438 correct = 0.001092 Error back Propagation 1 0.5 -0.5 0.3 -0.2 correct=0.07229 0.4 0.5 0.3 0.4 0 0.6 0.7 0.7 -0.5 0.4 -0.1 1 bias
חישוב המשקולות מחדש out=0.69 correct = -0.00026 1 0.5 + 0.5 * 1 * -0.00026 = 0.49987 0.5 out = 0.476 correct = 0.00901 -0.49689 0.29987 -0.5 -0.19881 0.3 -0.2 out = 0.62 correct = 0.00239 0.40279 0.5172 correct=0.07229 0.4 0.30378 0.5 0.3 0.4 0 0.70119 0.6 0.7 0.7 0.60339 0.4026 0.72468 -0.5 0.4 out = 0.683 correct = 0.01095 -0.1 1 out = 0.475 correct = 0.00109 -0.09946 bias נניח כי אלפא = 0.5.
יכולת הניבוי • היתרון הגדול של רשת נוירונים היא יכולת הניבוי שלה. כאשר הרשת מורכבת, ולמדה מספיק מקרי בדיקה, היא תוכל לנבא תוצאת חישוב על קלט שהיא לא קיבלה מעולם. • במקרים אלו יש משקל רב לפער בין המקרה המחושב לבין מקרים קודמים שנלמדו. • ככל שהפער קטן יותר, יכולת הניבוי תהיה מדויקת יותר. • לכן, חשוב ללמד את הרשת בעזרת מגוון מקרי בדיקה, המייצגים ככל הניתן את מרחב אפשרויות הקלטים עליהם תופעל בעתיד הרשת.
בעיות וחסרונות • הרשת נתקעת • אין מספיק חופש תמרון • השכבות הנסתרות קטנות מדי • הלימוד לא יציב • יותר מדי חופש תמרון • השכבות הנסתרות גדולות או רבות מדי • Over-Fitting • יותר מדי דוגמאות ; מאבד את הפוקוס מבעיות כלליות שמאפיינות את סט הנתונים.
דוגמאות • http://www.cs.bgu.ac.il/~aharob/Ex4/