Download

1 / 22
230 likes | 489 Views
Régression linéaire (STT-2400). Section 8 Valeurs aberrantes et influentes Version: 28 décembre 2007. Introduction. Pour certaines observations, il arrive que les valeurs de la variable réponse et/ou des préviseurs semblent se comporter différemment de la majorité des observations.

E N D
Régression linéaire (STT-2400) Section 8 Valeurs aberrantes et influentes Version: 28 décembre 2007
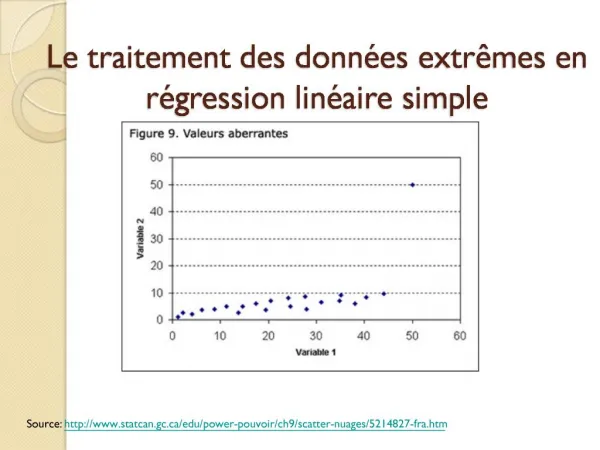
Introduction • Pour certaines observations, il arrive que les valeurs de la variable réponse et/ou des préviseurs semblent se comporter différemment de la majorité des observations. • En régression linéaire simple, ceci peut être apprécié visuellement: un graphique de la variable réponse versus le préviseur peut révéler que la majorité des points semble se répartir autour d’une droite, mais quelques observations peuvent s’en éloigner passablement. • Des observations qui ne suivent pas le même modèle (linéaire) que la majorité des données sont appelées des valeurs aberrantes (de régression). STT-2400; Régression linéaire
Introduction (suite) • Les valeurs aberrantes peuvent survenir pour diverses raisons, dont la plus évidente est lors d’erreurs de mesure, erreurs de transcription des données, etc. • Cependant, les valeurs aberrantes ne sont pas forcément erronées. Parfois, elles sont des valeurs qui révèlent un phénomène particulier qui peut être différent du modèle suivi par la majorité des observations. • La formulation d’un modèle vise à expliquer aussi bien que possible un phénomène général; il peut avoir ses propres limites et les valeurs aberrantes peuvent suggérer des pistes pour des modèles plus élaborés. STT-2400; Régression linéaire
Classification des valeurs aberrantes • Dans un contexte de régression, les valeurs aberrantes peuvent survenir de diverses manières: • Valeurs aberrantes dans la variable réponse mais pas dans les préviseurs (valeurs aberrantes dans la direction des Y); • Valeurs aberrantes dans les préviseurs mais pas dans la variable réponse (valeurs aberrantes dans la direction des X; points de leviers); • Valeurs aberrantes à la fois dans la direction des X et des Y (bon ou mauvais points de leviers). STT-2400; Régression linéaire
Points de levier et valeurs aberrantes de régression • Un point de levier est un type de valeur aberrante. • Cependant, les points de levier ne sont pas forcément des valeurs aberrantes de régression. • Lorsque les points de levier suivent la tendance linéaire générale de la majorité des observations, on parle de bons points de levier. • Il est souvent crucial de distinguer les bons points de levier des mauvais. STT-2400; Régression linéaire
Un simple test pour des valeurs aberrantes dans la direction des Y • Le modèle de la moyenne translatée peut être facilement mis en œuvre avec SAS afin de tester si une observation donnée est aberrante (en Y). • Dans ce modèle, si on soupçonne que l’observation i est aberrante (en Y), on présume que: • On désire tester l’hypothèse STT-2400; Régression linéaire
Mise en œuvre du test • Afin de mettre en œuvre le test, soupçonnant que l’observation i est aberrante, on procède comme suit: • On définit une variable indicatrice de l’observation i, en introduisant une variable U: • La variable U est donc 0 partout sauf pour l’observation i. • On régresse Y sur les préviseurs et la variable U. • L’estimateur du coefficient correspondant à U est l’estimateur de d dans le modèle. • On regarde la statistique-t associée à la variable U. STT-2400; Régression linéaire
Résidus standardisés • On rappelle que les résidus sont tels que: • Les résidus standardisés ont moyenne zéro et de même variance valant un: STT-2400; Régression linéaire
Calcul du test • Il peut être montré que la statistique de test est: • Cette valeur est appelée un résidu studentizé et est fournie par SAS sous la colonne RStudent lorsque l’option INFLUENCE est utilisée. • De plus, la distribution est: STT-2400; Régression linéaire
Ajustement du niveau • Si une observation particulière est soupçonnée être aberrantes, alors on peut faire le test de manière usuelle et utiliser la valeur-p fournie par SAS. • Cependant, une pratique courante consiste à examiner toutes les statistiques | ti | et déclarer la plus grande comme une valeur aberrante. Cependant, ceci revient à effectuer n tests. Si on effectue n tests de niveau a, alors le niveau global du test est bien supérieur à a. • Considérons n = 65, et soit un test Ti dont la région de rejet est: de telle sorte que . STT-2400; Régression linéaire
Ajustement du niveau (suite) • Alors si les n tests sont indépendants: • L’inégalité de Bonferroni dit que pour n tests de niveau a, la probabilité de faussement considérer au moins une observation comme aberrante n’est pas plus grande que na. • En pratique pour obtenir la valeur-p il suffit de multiplier la valeur-p fournit par SAS par n. STT-2400; Régression linéaire
Influence des observations • Une analyse de l’influence des observations est basée sur l’idée de comparer l’ajustement avec et sans des observations pouvant être qualifiées de douteuses. • Ainsi, on peut retirer la première observation, effectuer l’analyse, et comparer avec l’analyse reposant sur l’ensemble des données. • On procède ainsi pour chacune des observations du jeu de données. STT-2400; Régression linéaire
Calcul des estimateurs sans l’observation i • Introduisons la notation « (i) » qui veut dire: « sans l’observation i ». Ainsi, calculer l’estimateur des moindres carrés sans l’observation i donne: • On note que: STT-2400; Régression linéaire
Distance de Cook • On dispose de: • L’idée de Cook (Technometrics, 1977) est de comparer ces deux quantités. Cook a définit la mesure suivante: STT-2400; Régression linéaire
Interprétation des distances de Cook • La distance de Cook est essentiellement une mesure de distance standardisée qui permet de décrire le changement dans l’estimateur de b lorsque l’on retire l’observation i. • Une grande valeur de la distance de Cook suggère que l’observation i possède une grande influence. • On note la ressemblance avec l’ellipsoïde de confiance: STT-2400; Régression linéaire
Utilisation des distances de Cook • En pratique, les distances de Cook sont souvent comparées avec un. Une valeur grandement inférieure à un suggère que l’impact de l’observation i ne semble pas très important. • En revanche, une distance de Cook plus grande que un suggère que l’observation i possède un grand impact. STT-2400; Régression linéaire
Distance de Cook et une identité remarquable • Des arguments algébriques permettent de montrer la relation suivante: • On constate que la distance de Cook, pour p fixé, peut être grande si les résidus standardisés sont grands ou si les leviers sont grands (ou si les deux sont grands). STT-2400; Régression linéaire
D’autres mesures populaires: DFBETAS et DFFITS • SAS inclut d’autres mesures dans le même esprit que la distance de Cook. • Les mesures DFBETAS et DFFITS (noter le S supplémentaire) sont des mesures proprement standardisées (et indépendantes des systèmes d’unités). STT-2400; Régression linéaire
Quelques mots sur l’hypothèse de normalité • De manière générale, il est souvent reconnu que l’hypothèse de normalité joue un rôle mineur en analyse de régression. • De manière générale, l’hypothèse de normalité est utile à des fins d’inférence, surtout pour les petits échantillons. • Cependant, il est à noter qu’en présence de petits échantillons, la non-normalité peut être particulièrement difficile à diagnostiquer par un examen des résidus. STT-2400; Régression linéaire
Hypothèse de normalité (suite) • On rappelle les relations: • Pour des échantillons petits à modérés, le second terme peut dominer le premier. • En invoquant le théorème central limite, il peut être montré que la somme sera approximativement normale même si les erreurs originales ne sont pas normales. • Cependant, si n est assez grand, le second terme a une plus petite variance par rapport au premier terme et par conséquent est moins important. • Ainsi, pour n grand, les résidus peuvent être utilisés afin de cerner la normalité des erreurs (sauf que l’hypothèse de normalité n’est plus aussi importante!). STT-2400; Régression linéaire
« Normal Probability Plot » • Afin de vérifier l’hypothèse de normalité, on peut procéder comme suit. Soit: • On désire vérifier si les zi proviennent d’une loi normale • 1. On commence par ordonner les zi: • 2. Soit STT-2400; Régression linéaire
« Normal Probability Plot » (suite) • Les ui sont les valeurs moyennes des statistiques d’ordre qui seraient obtenues si les observations étaient vraiment normales N(0,1). • Il peut être montré que la ième statistique d’ordre espérée d’une N(0,1) est approximativement: • Si les zi étaient de loi normale: • 3. La régression des z(i) sur les u(i) devrait être une ligne droite sous l’hypothèse de normalité. Si ce n’est pas une ligne droite, on peut questionner l’hypothèse de normalité. STT-2400; Régression linéaire