Download
1 / 37
380 likes | 556 Views
Tertiary Structure Prediction. Fold Recognition and Fragment Assembly. Topic 15. Chapter 31-32, Du and Bourne “Structural Bioinformatics”. Fold Recognition. Fold recognition methods can be broadly divided into two types:

E N D
Tertiary Structure Prediction Fold Recognition and Fragment Assembly Topic 15 Chapter 31-32, Du and Bourne “Structural Bioinformatics”
Fold Recognition • Fold recognition methods can be broadly divided into two types: • Methods that derive a 1D profile for each structure in the fold library and align the target sequence to these profiles • Methods that consider the full 3D structure of the protein template • A simple example of a profile representation would be to take each amino acid in the structure and simply label it according to whether it is buried in the core of the protein or exposed on the surface. More elaborate profiles might take into account the local secondary structure (e.g. whether the amino acid is part of an alpha helix) or even evolutionary information (how conserved the amino acid is). • In the 3-D representation, the structure is modeled as a set of inter-atomic distances i.e. the distances are calculated between some or all of the atom pairs in the structure. This is a much richer and far more flexible description of the structure, but is much harder to use in calculating an alignment. • (Text from Wikipedia.com)
Profile-based fold recognition methods Search sequence db for distant homologs (i.e. PSI-BLAST) Multiple alignment Generate profile or HMM Search against template database
Model Protein Threading Make a structure prediction through finding an optimal placementof a protein sequence onto each known structure (template) Target Templates • * “placement” quality is measured by statistics-based energy functions • * best overall “placement” among all templates may give a model
Protein Threading 1. Use the unknown sequence as a query to search for known protein structures against a database of structural templates. Produce the best possible sequence alignment to multiple structure targets. Build a model of the protein backbone, taking the backbone of the template structure as a model. 2. Calculate “goodness of fit” for sequence-structure alignment. Many ways to do this, but most include at least two terms: pairwise terms (interactions between pairs of amino acids) and solvation terms(see next slide). Predicted structure is the one that minimizes the energy function.
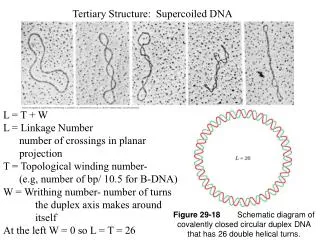
Two Seminal Papers on Protein Threading Residue solvent accessibility Science. 1991 Jul 12;253(5016):164-70 Pairwise structural contacts Nature. 1992 Jul 2;358:86-89
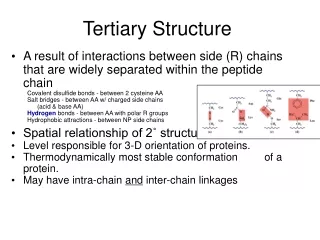
Key Components of Protein Threading • template library • energy functions • threading algorithms • confidence assessment total score: w1E_p + w2E_s + w3E_c + w4E_g + w5E_m +…..
A deeper look under the hood… In essence, the threading (sequence-structure alignment) is very similar to the pairwise (sequence-sequence) alignment problem; in each problem, the “best” set of corresponding amino acids must be identified. What makes threading more difficult is that the “energies” are much harder to calculate accurately. Threading energies are generally of the form: ETOTAL =ESTRUCT ENVIRONMENT+EPAIRWISE INTERACTION+EGAP + … The constituent parts are described using knowledge-based force fields. The coefficients are empirically determined scaling factors. Just like in structural alignment, a simple dynamic programming protocol will fail to find the minimum of this function because it can’t be cleanly broken down into a series of local evaluations (like sequence alignment can). And again, just like in structural alignment, there are a wide variety of heuristics to make this problem computationally tractable.
singleton pairwise mutation Gap sequence profile SS match score Energy Terms MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYTE how well a residue fits a structural environment: E_s how preferable to put two particular residues nearby: E_p sequence similarity between query and template proteins: E_c alignment gap penalty: E_g total score: w1E_p + w2E_s + w3E_c + w4E_g + w5E_m +….. Find a sequence-structure alignment to optimize this function
Mutation Energy--Substitution Matrices • amino acid substitution matrices account for the probability of one amino acid being substituted for another: frequency of substitution - genetic code tolerance for changes - natural selection • empirically derived from observed amino acid substitutions that occur between aligned residues in homologous sequences • use a matrix to penalize residues pairs that have a low probability of mutation in evolution and rewards pairs with a high probability • Two popular sets of matrices for protein sequences • 1. PAM (Percent Accepted Mutations) • The first substitution matrix introduced by Dayhoffet al., 1978. • 2. BLOSUM (BLOcksSUbstitutionMatrix) • Henikoff & Henikoff, 1992
Substitution Matrices PAM250 BLOSUM62 Which matrix to use? • Close homolog: high cutoffs for BLOSUM (up to BLOSUM 90) or lower PAM values. BLAST default: BLOSUM 62 • Remote homolog: lower cutoffs for BLOSUM (down to BLOSUM 10) or high PAM values (PAM 200 or PAM 250) . A threading best performer: PAM 250
Knowledge-based Singleton Energy Measures how well a residue fits into the structural environment Kim, D. Xu, D. Guo, J-T. et al. Protein Eng. 16(9), 641-650, 2003
Knowledge-based Pair-wise Interaction Energy ***Distance-dependent vs distance-independent pair potential Kim, D. Xu, D. Guo, J-T. et al. Protein Eng. 16(9), 641-650, 2003
Using Predicted Secondary Structures • Secondary structure prediction is mature and can achieve ~80% accuracy • The performance of using probabilities of the predicted three secondary structure states (-helices, -strand, and loop) is better • May have a risk of over-dependence on secondary structure prediction Conf: Confidence (0=low, 9=high) Pred: Predicted secondary structure (H=helix, E=strand, C=coil) AA: Target sequence # PSIPRED HFORMAT (PSIPRED V2.3 by David Jones) Conf: 966899999997542002357777557999999716898188034435788873356776 Pred: CCHHHHHHHHHHHHHHHCCCCCCCHHHHHHHHHHHCCCCCEEECCCCEEEEEEECCCCCC AA: MMWEQFKKEKLRGYLEAKNQRKVDFDIVELLDLINSFDDFVTLSSCSGRIAVVDLEKPGD 10 20 30 40 50 60 Conf: 777179998337888888988751235636899718261220179868899999998557 Pred: CCCCEEEEEECCCCCHHHHHHHHHCCCCCEEEEECCCEEEEECCCHHHHHHHHHHHHHCC AA: KASSLFLGKWHEGVEVSEVAEAALRSRKVAWLIQYPPIIHVACRNIGAAKLLMNAANTAG 70 80 90 100 110 120
Parameter Optimization • The contribution of each term (weight). • Based on threading performance on a training set (fold recognition and alignment accuracy). • Different weight for different classes? (superfamily, fold) pair-wise may contribute more for fold level threading mutation/profile terms dominate in superfamily level threading Etotal= mEmutation + sEsingleton + pEpairwise + gEgap + ssEss
Knowledge-based potentials Counting the observed (i,j) pairs is easy. The real difficulty in creating a knowledge-based potential is estimating the background expectation!
HHCCHHHHHCCCCCHHHHCCCEECCCCCCCCCCCCHHHHHHHHH MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYT… | | | | PELPEIETTRRRLRTLVLGQTLRQVVHRDPARYRNTALAEGRRI… CCHHHHHHHHHHHHHHHCCCEEEEEECCCCCCEECHHHHCCEEEE Protein Threading • Query sequence • MTYKLILNGKTKGETTTEAVDAATAEKVFQYANDNGVDGEWTYT… templates Score score1 score2 …… scorei model scorei+1 scorei+2
An uncommon, albeit real, result The realities of threading • Despite initially promising results, methods of fold recognition are not always accurate. • In the early days (circa 1998), the methods were found to be about 50 % accurate at best with respect to their ability to place a correct fold at the top of a ranked list. • Though many methods failed to detect the correct fold at the top of a ranked list, a correct fold was often found in the top 10 scoring folds. • Even when the methods were successful, alignments of sequence on to protein 3D structure were usually incorrect, meaning that comparative modeling performed using such models would be inaccurate. • Many of the current so-called threading algorithms are algorithms (using our definitions) actually hybrid fold recognition/threading.
Comparative modeling structure prediction flowchart Experimental Sequence Database Searching Structure Homolog? Secondary Structure Prediction YES NO Homology Modeling Final Structure Fold Prediction
ab initioStructure Prediction • An energy function to describe the protein • bond energy • bond angle energy • dihedral angel energy • van der Waals energy • electrostatic energy • Efficient and reliable algorithms to search the conformational space to minimize the function and obtain the structure. ***Not practical in general • Computationally too expensive • Accuracy is poor • Only applied to small proteins
ab initio Structure Prediction • Goal: Find a conformation that minimizes the energy function • An energy function to describe the protein • Efficient and reliable algorithms to search the conformational space • (backbone + sidechain) Currently, ab initio methods: • Accuracy is poor • Only applied to small proteins
Fragment assembly methods Now, what if I cannot find a template to build models: --it is a new fold --failed to identify the fold ab initio/de novo, fragment assembly. Problems: -- Must search through large(!) conformational space -- Must be able to distinguish good from bad conformations Bujnicki, JM. ChemBiochem, 2006, 7:19-27
Fragment Assembly and Rosetta ***One of the top performers in CASPs
Rosetta Algorithm • Construct a library of small structure fragments, eg. 6, 9 AA • Cut a target sequence to sequence fragments. For each sequence fragment, choose some candidate fragments from the fragment library. • Assemble the fragments by Monte Carlo simulation. • The potential used in Rosetta tries to capture multiple features seen in experimentally determined protein structures • The generated structures are grouped into some clusters. • Clusters are ranked by their energy.
Single and noise in Rosetta Each folding simulation results in a putative protein structure, called a decoy. A typical simulation generates between 1,000 and 100,000 decoys. The broadest minima is determined by cluster analysis.
Baye’s theorem • P(A) is the prior probability. It is "prior" in the sense that it does not take into account any information about B. • P(A|B)is the conditional probability of A, given B. It is also called the posterior probability because it is derived from or depends upon the specified value of B. • P(B|A) is the conditional probability of B given A, also called likelihood. • P(B) is the marginal probability of B.
A straightforward example of Bayes’ Theorem What is the probability of the Lakers winning assuming their opponents score less than 80 points?
The Rosetta Scoring Function: Bayes’ theorem However, in comparisons of different structures for the same sequence, Pr(sequence) is constant and can be neglected. The Pr(structure) is zero for structures with overlapping atoms, and proportional to Exp(-Radius of gyration)2 for all others configurations. Radius of gyration describes how much the structure spreads out from its center, meaning it’s a measure of compactness.
Independent of structure Easily determined from PDB Pr(sequence|structure)
One improvement on Rosetta Scoring Function Previously, Pr(structure) is independent on helix and strand propensities.
Further improvement on Rosetta Scoring Function • The first improvement was the incorporations of a filter that removes overly local, low contact order conformations. • The second was the incorporations of a filter that removes conformations with -strands not properly assembled into -sheets. • Re-parameterization of energy force field using only high resolution structures. • The methodology for picking fragments from the structure database was also improved by ensuring that an appropriate diversity of secondary structures is present in the fragment library for regions with weak propensity to adopt a single secondary structure.
Clustering and Model Selection • For each target, fragment libraries and sets of decoy structures were generated both for the target sequence and for up to three homologous sequences identified with PSI-BLAST. • Twice as many models were generated for the target sequence as for the homologues; the resulting models from the target and homologous sequences were pooled and then clustered. • For clustering to succeed, a sufficient number of native-like decoys must be present among the models generated. • As stated above, a filter was developed to account for unpaired β-strands. To improve model selection for proteins with at least three predicted -strands, a test set of mixed /proteins of >130 residues is used to develop a filter that is enriched for native-like structures in the model populations.
All-atom Refinement of Models • For targets under 100 residues, the submitted predictions were chosen without clustering, as follows. • The top 15% lowest-energy models were refined by using an improved version of the full-atom refinement protocol described previously, which couples Monte Carlo minimization of the backbone and side-chain conformations. • The full-atom energy function is dominated by Lennard-Jones interactions, an orientation-dependent hydrogen-bonding potential, and an implicit solvation model. • Typically, 5,000 to 20,000 decoys were refined, and the five decoys with the lowest energies that belonged to different clusters were submitted. Accuracy of domain prediction based on sequence is important to structure prediction
Rosetta Fragment Assembly Structure Prediction “Snapshot” of low resolution of fragment assembly (five 9-residue fragments) Final low resolution conformation by fragment assembly All-atom model produced after high-resolution refinement Das and Baker
Rosetta Design: Top7 • Perhaps one of the coolest structure bioinformatics applications ever presented was in the Kuhlman et al., Science, 2003. • Starting with a novel a/b-protein fold (never observed in Nature), Rosetta was used to design a sequence to fold into this fold. • The Rosetta Design process is fairly straightforward. • Thread a sequence onto the template using Rosetta • Minimize resultant structure using standard techniques • Use above structure as template for next round of threading • Continue till convergence X-ray vs. modeled Target