Download

1 / 4
40 likes | 161 Views
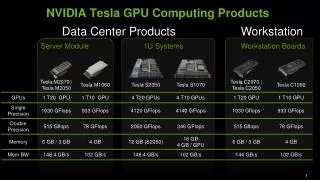
GPUs and Big Data Steve Scott NVIDIA Tesla CTO February 27, 2012. GPU Attributes. GPUs are Compute and Local Bandwidth powerhouses Lots of ( fl )ops Lots of memory bandwidth Lots of threads (latency tolerance) Expect sometime later this decade: Big memory capacity attached to the GPU

E N D
GPUs and Big Data Steve ScottNVIDIA Tesla CTO February 27, 2012
GPU Attributes • GPUs are Compute and Local Bandwidth powerhouses • Lots of (fl)ops • Lots of memory bandwidth • Lots of threads (latency tolerance) • Expect sometime later this decade: • Big memory capacity attached to the GPU • High-perf networks integrated into the GPUs • Global addressing (global latency tolerance)
GPUs for Big Data? • If it’s all data movement from disk (no temporal locality) • Don’t need GPUs (or CPUs for that matter) • (Unless data can live in memory, in which case GPUs could be great) • If you’ve got some serious computing to do on that data and you can distribute the problem (Map-Reduce-like) • GPUs can be great (allow more complex analysis) • E.g.: face recognition for photo data • If the problem has no locality (e.g.: Big Graph Analytics) • GPUs will be great later
A Few Examples of GPUs and Big Data • Document clustering: • k-means (11x, single node, large dataset) • http://www.inf.fu-berlin.de/lehre/SS10/SP-Par/download/k-means2.pdf • Flocking-based (30-50x, 16-node, linear scaling with dataset & cluster size) • Better algorithm, but much more computationally demanding • http://moss.csc.ncsu.edu/~mueller/ftp/pub/mueller/papers/ipdps10.pdf • Graph analytics (BFS, Centrality): • Great results, but mostly single node work at this point • http://research.nvidia.com/publication/scalable-gpu-graph-traversal • http://hipc.org/hipc2009/documents/HIPCSS09Papers/1569256361.pdf • Visual search (face recognition, object recognition) • http://nnguyenthanh.ucsd.edu/tan/publish/fccm_10.pdf • Lots of Big Compute problems are also Big Data: • E.g.: Reverse Time Migration in oil & gas • http://dx.doi.org/10.1190/1.3255428