Download

1 / 39
390 likes | 391 Views
This article discusses a different method for predicting protein function from structure using general structural features unique to protein families, without relying on homology. Examples include predicting new DNA-binding proteins and RNA structures.

E N D
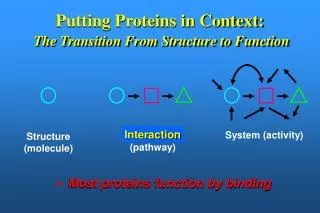
Given a protein structurecan we predict the function of a protein when we do not have a known homolog in the database ?
A different approach for predicting function from structure which does not rely on homology • To characterize the known protein structures belonging to a specific family • Find general structural features which are unique to the family • Use these features to predict new members of the family
EXAMPLE : Predicting new DNA-binding proteins p53 Many DNA-binding proteins are involved in cancer
Many different folds but all can bind DNA Helix-Turn-Helix Zinc-Finger Leucine zippers b-ribbon
While DNA-binding proteins have diverse folds they all share a common property: All have positive charged surfaces Complementing the negative charge of the DNA Positive (Blue) Negative (red)
DNA-binding proteins are characterized by positive charged surfaces Positive (Blue) Negative (red) But so do proteins that don’t bind nucleic acids
Strategy for predicting new DNA-binding proteins • Build a database of DNA-binding and non DNA-binding proteins • Extract the positive electrostatic patch in all proteins in Data Set. • Find features that could be used to discriminate the DNA-binding proteins from other proteins. 4. Use the features as a vector to train a machine learning algorithm to identify novel DNA-binding proteins
Machine learning algorithmfor predicting protein function from structural features • SVM (Support Vector Machine) is trained on a set of known proteins that have a common function such as DNA binding (red dots), and in addition, a separate set of proteins that are known not to bind DNA (blue dots)
? • Using this training set of DNA and non-DNA binding protein, an SVM would learn to differentiate between the members and non-members of the family • Having learned the features of the class (DNA binding proteins), the SVM could recognize a new protein as members or as non-members of the class based on the combination of its structural features.
100 Non- ‘DNA binding DNA binding 80 60 40 20 0 correct correct incorrect incorrect Testing the algorithm for predicting DNA-binding proteins TP, TN, FP, FN Sensitivity Specificity
protein RNA DNA According to the central dogma of molecular biology the main role of RNA is to transfer genetic information from DNA to protein
RNA has many other biological functions • Protein synthesis (ribosome) • Control of mRNA stability (UTR) • Control of splicing (snRNP) • Control of translation (microRNA) The function of the RNA molecule depends on its folded structure
Ribosome Nobel prize 2009
Protein structures RNA structures Total ~900 ~Total 90,000
RNA Structural levels Tertiary Structure Secondary Structure tRNA
3’ G A U C U U G A U C RNA Secondary Structure • RNA bases are G, C, A, U • The RNA molecule folds on itself. • The base pairing is as follows: G C A U G U hydrogen bond. Loop U U C G U A A U G C 5’ 3’ Stem 5’
Predicting RNA secondary Structure Most common approach: Search for a RNA structure with a Minimal Free Energy (MFE) U U C G U A A U G U G A U C U U G A U C C A U U G U G Low energy High energy
Free energy model Free energy of a structure is the sum of all interactions energies Free Energy(E) = E(CG)+E(CG)+….. Each interaction energy can be calculated thermodynamicly The aim: to find the structure with the minimal free energy (MFE)
Why is MFE secondary structure prediction hard? • MFE structure can be found by calculating free energy of all possible structures • BUT the number of potential structures grows exponentially with the number of bases Solution :Dynamic programming (Zucker and Steigler)
Simplifying Assumptions for RNA Structure Prediction • RNA folds into one minimum free-energy structure. • The energy of a particular base can be calculated independently • Neighbors do not influence the energy.
Sequence dependent free-energy Nearest Neighbor Model U U C G U A A U G C A UCGAC 3’ U U C G G C A U G C A UCGAC 3’ 5’ 5’ Free Energy of a base pair is influenced by the previous base pair (not by the base pairs further down).
Sequence dependent free-energy values of the base pairs (nearest neighbor model) U U C G U A A U G C A UCGAC 3’ U U C G G C A U G C A UCGAC 3’ 5’ 5’ These energies are estimated experimentally from small synthetic RNAs. Example values: GC GC GC GC AU GC CG UA -2.3 -2.9 -3.4 -2.1
Improvements to the MFE approach • Positive energy - added for destabilizing regions such as bulges, loops, etc. • More than one structure can be predicted
Free energy computation U U A A G C G C A G C U A A U C G A U A3’ A 5’ +5.9 4 nt loop -1.1 mismatch of hairpin -2.9 stacking +3.3 1nt bulge -2.9 stacking -1.8 stacking -0.9 stacking -1.8 stacking 5’ dangling -2.1 stacking -0.3 G= -4.6 KCAL/MOL -0.3
Improvements to the MFE approach • Positive energy - added for destabilizing regions such as bulges, loops, etc. • Looking for an ensemble of structures with low energy and generating a consensus structure WHY? RNA is dynamic and doesn’t always fold to the lowest energy structure
RNA fold prediction based on Multiple Alignment Information from multiple sequence alignment (MSA) can help to predict the probability of positions i,j to be base-paired. G C C U U C G G G C G A C U U C G G U C G G C U U C G G C C
Compensatory Substitutions Mutations that maintain the secondary structure can help predict the fold U U C G U A A U G C A UCGAC 3’ C G 5’
RNA secondary structure can be revealed by identification of compensatory mutations U C U G C G N N’ G C G C C U U C G G G C G A C U U C G G U C G G C U U C G G C C
Insight from Multiple Alignment Information from multiple sequence alignment (MSA) can help to predict the probability of positions i,j to be base-paired. • Conservation – no additional information • Consistent mutations (GC GU) – support stem • Inconsistent mutations – does not support stem. • Compensatory mutations – support stem.
From RNA structure to Function Many families of non coding RNAs which have unique functions are characterized by the combination of a conserved sequence and structure Rfam RNA Family database http://www.sanger.ac.uk/Software/Rfam/
MicroRNAs an example of an RNA family miRNA gene mature miRNA Target gene
The challenge for Bioinformatics: - Identifying new microRNA genes - Identifying the targets of specific microRNA
How to find microRNA genes? • Searching for sequences that fold to a hairpin ~70 nt • -RNAfold • -other efficient algorithms for identifying stem loops • Concentrating on intragenic regions and introns • - Filtering coding regions • Filtering out non conserved candidates • -Mature and pre-miRNA is usually evolutionary conserved
How to find microRNA genes? A. Structure prediction B. Evolutionary Conservation
Predicting microRNA targets MicroRNA targets are located in 3’ UTRs, and complementing mature microRNAs • Why is it hard to find them ?? • Base pairing is required only in the seed sequence (7-8 nt) • Lots of known miRNAs have similar seed sequences Very high probability to find by chance mature miRNA 3’ UTR of Target gene
Predicting microRNA target genes • General methods - Find motifs which complements the seed sequence (allow mismatches) • Look for conserved target sites • Consider the MFE of the RNA-RNA pairing ∆G (miRNA+target) • Consider the delta MFE for RNA-RNA pairing versus the folding of the target ∆G (miRNA+target )- ∆G (target)