Download

1 / 33
330 likes | 544 Views
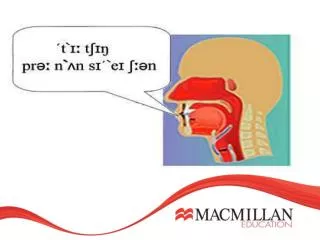
Pronunciation Modeling. Lecture 11 Spoken Language Processing Prof. Andrew Rosenberg. What is a pronunciation model?. Audio Features. Word Hypothese. Acoustic Model. Pronunciation Model. Language Model. Phone Hypothese. Word Hypothese. Why do we need one?.

E N D
Pronunciation Modeling Lecture 11 Spoken Language Processing Prof. Andrew Rosenberg
What is a pronunciation model? Audio Features Word Hypothese Acoustic Model Pronunciation Model Language Model Phone Hypothese Word Hypothese
Why do we need one? • The pronunciation model defines the mapping between sequences of phones and words. • The acoustic model can deliver a one-best, hypothesis – “best guess”. • From this single guess, converting to words can be done with dynamic programming alignment. • Or viewed as a Finite State Automata.
Simplest Pronunciation “model” • A dictionary. • Associate a word (lexical item, orthographic form) with a pronunciation. ACHE EY K ACHES EY K S ADJUNCT AE JH AH NG K T ADJUNCTS AE JH AN NG K T S ADVANTAGE AH D V AE N T IH JH ADVANTAGE AH D V AE N IH JH ADVANTAGE AH D V AE N T AH JH
Finite State Automata view • Each word is an automata over phones EY K EY K S AH D V AE N T I JH
Size of whole word models • these models get very big, very quickly START END EY K EY K S AH D V AE N T I JH
Potential problems • Every word in the training material and test vocabulary must be in the dictionary • The dictionary is generally written by hand • Prone to errors and inconsistencies ACHE EY K ACHES EY K S ADJUNCT AE JH AH NG K T ADJUNCTS AE JH AN NG K T S ADVANTAGE AH D V AE N T IH JH ADVANTAGE AH D V AE N IH JH ADVANTAGE AH D V AE N T AH JH
Composition • From the word graph, we can replace each phone by its markov model
Automating the construction • Do we need to write a rule for every word? • pluralizing? • Where is it +[Z]? +[IH Z]? • prefixes, unhappy, etc. • +[UH N] • How can you tell the difference between “unhappy”, “unintelligent” and “under” and “
Is every pronunciation equally likely? • Different phonetic realizations can be weighted. • The FSA view of the pronunciation model makes this easy. ACAPULCO AE K AX P AH L K OW ACAPULCO AA K AX P UH K OW THE TH IY THE TH AX PROBABLY P R AA B AX B L IY PROBABLY P R AA B L IY PROBABLY P R AA L IY
Is every pronunciation equally likely? • Different phonetic realizations can be weighted. • The FSA view of the pronunciation model makes this easy. ACAPULCO AE K AX P AH L K OW 0.75 ACAPULCO AA K AX P UH K OW 0.25 THE TH IY 0.15 THE TH AX 0.85 PROBABLY P R AA B AX B L IY 0.5 PROBABLY P R AA B L IY 0.4 PROBABLY P R AA L IY 0.1
Collecting pronunciations • Collect a lot of data • Ask a phonetician to phonetically transcribe the data. • Count how many times each production is observed. • This is very expensive – time consuming, finding linguists.
Collecting pronunciations • Start with equal likelihoods of all pronunciations • Run the recognizer on transcribed speech • forced alignment • See how many times the recognizer uses each pronunciation. • Much cheaper, but less reliable
Out of Vocabulary Words • A major problem for Dictionary based pronunciation is out of vocabulary terms. • If you’ve never seen a name, or new word, how do you know how to pronounce it? • Person names • Organization and Company Names • New words “truthiness”, “hypermiling”, “woot”, “app” • Medical, scientific and technical terms
Collecting Pronunciations from the web • Newspapers, blog posts etc. often use new names and unknown terms. • For example: • Flickeur (pronounced like Voyeur) randomly retrieves images from Flickr.com and creates an infinite film with a style that can vary between stream-of-consciousness, documentary or video clip. • Our group traveled to Peterborough (pronounced like “Pita-borough”)... • The web can be mined for pronunciations [Riley, Jansche, Ramabhadran 2009]
Grapheme to Phoneme Conversion • Given a new word, how do you pronounce it. • Grapheme is a language independent term for things like “letters”, “characters”, “kanji”, etc. • With a phoneme to grapheme-to-phoneme converter, dictionaries can be augmented with any word. • Some languages are more ambiguous than others.
Grapheme to Phoneme conversion • Goal: Learn an alignment between graphemes (letters) and phonemes (sounds) • Find the lowest cost alignment. • Weight rules, and learn contextual variants.
Grapheme to Phoneme Difficulties • How to deal with Abbreviations • US CENSUS • NASA, scuba vs. AT&T, ASR • LOL • IEEE • What about misspellings? • should “teh” have an entry in the dictionary? • If we’re collecting new terms from the web, or other unreliable sources, how do we know what is a new word?
Application of Grapheme to Phoneme Conversion • This Pronunciation Model is used much more often in Speech Synthesis than Speech Recognition • In Speech Recognition we’re trying to do Phoneme-to-Grapheme conversion • This is a very tricky problem. • “ghoti” -> F IH SH • “ghoti” -> silence
Approaches to Grapheme to Phoneme conversion • “Instance Based Learning” • Lookup based on a sliding window of 3 letters • Helps with sounds like “ch” and “sh” • Hidden Markov Model • Observations are phones • States are letters
Machine Learning for Grapheme to Phoneme Conversion • Input: • A letter, and surrounding context, e.g. 2 previous and 2 following letters • Output: • Phoneme
Decision Trees • Decision trees are intuitive classifiers • Classifier: supervised machine learning, generating categorical predictions Feature > threshold? Class A Class B
Decision Tree Training • How does the letter “p” sound? • Training data • P loophole, peanuts, pay, apple • F physics, telephone, graph, photo • ø apple, psycho, pterodactyl, pneumonia • pronunciation depends on context
Decision Trees example • Context: L1, L2, p, R1, R2 R1 = “h” Yes No P loophole F physics F telephone F graph F photo P peanut P pay P apple ø apple ø psycho ø psycho ø pterodactyl ø pneumonia
Decision Trees example • Context: L1, L2, p, R1, R2 R1 = “h” Yes No P peanut P pay P apple ø apple ø psycho ø pterodactyl ø pneumonia P loophole F physics F telephone F graph F photo Yes No L1 = “o” P loophole F physics F telephone F graph F photo Yes No R1 = consonant P apple ø psycho ø pterodactyl øpneumonia P peanut P pay
Decision Trees example • Context: L1, L2, p, R1, R2 try “PARIS” R1 = “h” Yes No P peanut P pay P apple ø apple ø psycho ø pterodactyl ø pneumonia P loophole F physics F telephone F graph F photo Yes No L1 = “o” P loophole F physics F telephone F graph F photo Yes No R1 = consonant P apple ø psycho ø pterodactyl øpneumonia P peanut P pay
Decision Trees example • Context: L1, L2, p, R1, R2 Now try “GOPHER” R1 = “h” Yes No P peanut P pay P apple ø apple ø psycho ø pterodactyl ø pneumonia P loophole F physics F telephone F graph F photo Yes No L1 = “o” P loophole F physics F telephone F graph F photo Yes No R1 = consonant P apple ø psycho ø pterodactyl øpneumonia P peanut P pay
Training a Decision Tree • At each node,decide what the most useful split is. • Consider all features • Select the one that improves the performance the most • There are a few ways to calculate improved performance • Information Gain is typically used. • Accuracyis less common. • Can require many evaluations
Pronunciation Models in TTS and ASR • In ASR, we have phone hypotheses from the acoustic model, and need word hypotheses. • In TTS, we have the desired word, but need a corresponding phone sequence to synthesize.
Next Class • Language Modeling • Reading: J&M Chapter 4