Download

1 / 30
300 likes | 548 Views
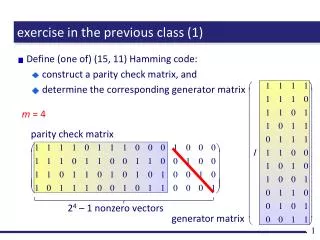
exercise in the previous class. Encode ABACABADACABAD by the LZ77 algorithm, and decode its result. back 4 positions copy 3 symbols. ( 0, 0, A), (0, 0, B ), ( 2, 1, C), (4, 3, D), (6, 6, *). A. B. A C. ABA D. ACABAD. back 2 positions copy 1 symbol. back 6 positions

E N D
exercisein the previous class Encode ABACABADACABAD by the LZ77 algorithm, and decode its result. back 4 positions copy 3 symbols (0, 0, A), (0, 0, B), (2, 1, C), (4, 3, D), (6, 6, *) A B AC ABAD ACABAD back 2 positions copy 1 symbol back 6 positions copy 6 symbols back 4 positions copy 3 symbols A B AC ABAD ACABAD back 2 positions copy 1 symbol back 6 positions copy 6 symbols
exercisein the previous class Survey what has happened concerning LZW algorithm. • UNISYS had the patent. • The patent was granted free of charge for non-commercial use. • Many people used LZW, for example in GIF format. in 1990s, the Web was born, and GIF can be a “business”: • UNISYS changed the policy; everybody needs to pay. • Much confusion in late 90’s... today: • The patent has been expired.
today’s class • think of “uncertainty” outside of the Information Theory “randomness” • random numbers, pseudo-random numbers (乱数,疑似乱数) • Kolmogorov complexity • statistical (統計的) test of pseudo-random numbers • 2-test (chi-square test) • algorithms for pseudo-random number generation
random numbers • A numeric sequence is said to be statistically random when it contains no recognizable patterns or regularities (Wikipedia). recognizable?regularities? • approach from statistics ( mid part of today’s talk) • approach from computation ( first part of today’s talk)
approach from computation For a finite sequence x, let (x) denote the set of programs which outputs x. • program...deterministic, no input, written as a sequence • “#include <stdio.h>; main(){printf(“hello”);}” (“hello”) • |p|...the size of the program p (in bytes, lines, etc.) • The Kolmogorov complexity (コルモゴロフ複雑さ) of x is (the size of the shortest program which outputs x)
example (1) x1 = “0101010101010101010101010101010101010101”, 40chars. • (x1) contains; • program p1: printf(“010101...01”); ...51chars. • program p2: for(i=0;i<20;i++)printf(“01”); ...30chars. K(x1) 30 < 40 x2 = “0110100010101101001011010110100100100010”, 40chars. • (x2) contains; • program p3: printf(“011010...10”); ...51chars. K(x2) 51
example (2) x3 = “11235813213455891442333776109871597...”, million chars. • (x3) contains; • program p4: printf(“1123...”); ... million + 11chars. • program p5: compute & print the Fibonacci sequence ... hundreds chars. K(x3) is about hundreds characters or less The Kolmogorov complexity K(x): measure of the difficultness to construct the sequencex
the relation to entropy TWO measures of uncertainty • entropy • measure of uncertainty respect to the statistical property • contributes to measure information • Kolmogorov complexity • measure of uncertainty respect to the mechanistic property • contributes to mathematical discussion
randomness, from the viewpoint of Kolmogorov A sequence x is random (in the sense of Kolmogorov) if K(x) ≥ |x|. • “to write down x, write x down directly” • “there is no alternative way (他の手段) to write x” • “x does not have more compact representation than itself” theorem: There exists a random sequence. before go to the proof, we assume that... • sequences (programs) are represented over {0, 1}. • the set of sequences of length n is written by Vn.
the proof theorem: There exists a random sequence. proof (by contradiction, 背理法) Assume that there is no random sequence of length n, then... for each xVn, there is a program px with px (x) and |px|<n. • |Vn|=2n • |V1|+|V2|+ ... +|V n–1|=2n – 1 contradiction, because (# of programs) < (# of sequences) V n V 1 V n–2 V n–1 px x 2n – 1 sequence 2n sequence
can we have a random sequence? There are random sequences, but how can we have them? • approach 1: make use of physical phenomena • toss coins, catch thermal noise, wait for quantum events... • we have “true” random sequences (真性乱数) • “expensive” • approach 2: construct a sequence using a certain procedure • use equations or computer program • cheap and efficient • not “true” random, but pseudo-random (疑似乱数) http://www.fdk.co.jp/
pseudo-random sequence (numbers) pseudo-random sequence (numbers): • a sequence of numbers generated by a deterministic rule (決定性の規則) • looks like random, but not “random in Kolmogorov’s sense” • easily constructible by computer programs Before discussing the algorithm, we should learn how to evaluate the randomness.
criteria of randomness there are two criteria to evaluate the randomness • unpredictability • how difficult is it to predict the “next” symbol? • important in cryptography and games • statistical bias • is there any anomalous (特異な) bias in the sequence? • sufficient for many applications In general, anomalous bias help prediction... unpredictability is more favorable, but difficult to obtain... we discuss statistical tests in this class.
2-test: idea 2-test (chi-square test, カイ2乗検定) • one of the most basic statistical tests • evaluate the distance between “a given sequence” and “a typical (ideal) sequence” sketch of idea: generate a sequence by rolling a dice • s1 = 1625341625163412 random like • s2= 1115121121131116 NOT random like, because the number of “1” seems too many expected distribution of the number of 1 in s ideal source s s1 s2
2-test: definition prepararation (準備)... • partition the set of possible symbols to classes C1, ..., Ck • pi: probability that a symbol in Ci is generated from ideal source • in the dice roll, C1 = {1}, ..., C6={6}, pi = 1/6, for example You are given a sequence s of length n... • ni: the number of symbols in Cioccuringin the sequence s • the 2 (chi-square) value of s:
what is this value? • If the sequence s is a typical output of an ideal source... • : the numerator (分子) → 0 • the 2-value → 0 The 2-value is the “distance” (not strict sense) of the given sequence to ideal sequences. smaller 2-value more close to the ideal output ...the expected number of symbols in Ci ...the observed numberof symbols in Ci
example consider sequences s1 and s2 over {1, ..., 6} of length n= 42: • if “ideal source = fair dice”, then pi= 1/6 ⇒ npi = 7 • s1= 145325415432115341662126421535631153154363 • n1 = 10, n2 = 5, n3 = 8, n4 = 6, n5 =8, n6 = 5 • 2= 32/7 + 22/7 + 12/7 + 12/7 + 12/7 + 22/7 = 20/7 • s2= 112111421115331111544111544111134411151114 • n1 = 25, n2 = 2, n3 = 3, n4 = 8, n5 =4, n6 = 0 • 2= 182/7 + 52/7 + 42/7 + 12/7 + 32/7 + 72/7 = 424/7 s1 is closer to the ideal output (true random) than s2
example (cnt’d) s3= 111111111111222222...666666 (assume length n = 72) • n1 = 12, n2 = 12, n3 = 12, n4 = 12, n5 =12, n6 = 12 • 2= 02/12 + 02/12 + 02/12 + 02/12 + 02/12 + 02/12 = 0 • Is s3 random? NEVER! • consider a block of length 2...n = 36 blocks • ideal: “11”, ..., “66” occur with probability 1/36, npi= 1 • n11 = 6, n12 = 0, ..., n22 = 6, ... • 2= (6 – 1)2/1 + (0 – 1)2/1 + ... = 180 ⇒ large! lesson learned : use as many different class partitions as possible
small 2-values good? Small 2-value is good, but the discussion is not so simple... • It is “rare” that the 2-value of the “real dice roll” becomes 0. • a sequence of n = 60000, n1 = ...= n6 = 10000 exactly too good, rather strange We need to know the distribution of 2-values of an ideal source. Theorem: If there are k classesC1, ..., Ck, then 2-values of an ideal source obey the 2-distribution of degree k – 1. degree 4 degree 6 degree 2 O 2
interpretation of 2-values s3= 111111111111222222...666666 (n = 72) • 2= 02/12 + 02/12 + 02/12 + 02/12 + 02/12 + 02/12 = 0 • 6 classes ⇒ should obey 2-distribution of degree 5 degree 5 The 2-values should be interpretedin the 2-distribution. 2 O 4 it is quite rare that 2 = 0
other statistical tests • KS test(Kolmogorov-Smirnov test) • “continuous” version of x2 test • run-length test • 2-test for the length of runs • ( # of runs of length l )= 0.5×( #runs of length l – 1 ) for a binary random sequence • porker test, collision test, interval test, etc. There is no simple yes/no answer. The interpretation of scores must be discussed.
generating pseudo-random sequences pseudo-random sequence generator (PSG) • procedure which produces a sequence from a given seed. • there are many different algorithms linear congruent method (線形合同法) • poor but simple example of PSG • determine numbers in a sequence according to a recurrence • typically, Xi+1 = aXi + c mod M, with a, c, M parameters • used in early implementations of rand( ) of C language PSG 0110110101... seed
properties of linear congruent method Xi+1 = aXi + c mod M • The period of the sequence cannot be more than M • M must be chosen sufficiently large. • Ifthe choice of M is bad, then the randomness is degraded. • The relation between a and M is important. • Choosing M from prime numbers is safe option. • There is some heuristics on the choice of a and c, also.
bad usage of linear congruent method You want to sample points on a plane uniformly and randomly. • If you use (Xi, Xi+1) as sampled points, then... • the value of Xi uniquely determines the value of Xi+1 • all points are on the line y= ax+ c mod M (X1 = 5) in case you use Xi+1= 5Xi + 1 mod 7: 6 5 4 3 2 1 random sampling is NOT realized O 1 2 3 4 5 6
connect or disconnect Xi Xi–p Xi–p+1 Xi–p+2 Xi–1 M-sequence method M-sequence method (M系列法) • generate a sequence using a linear-feedback register • if you use p registers⇒ there are 2p internal states • with carefully setting the feedback connection, we can go through all of 2p – 1 nonzero states. a sequence with period 2p – 1 (the Maximum with p registers)
about M-sequence • the connection is determined by a primitive polynomial • the generated sequence show good score for statistical tests • the difference of initial seed phase-shift • “shift additive” property • good “self-correlation” property applications in digital communication like as in CDMA
other PSG algorithms • Mersenne Twister algorithm (メルセンヌ・ツイスタ法) • M. Matsumoto (U. Tokyo), T. Nishimura (Yamagata U.) • make use of Mersennenumbers • efficiently generates a high-quality sequence • PSG with unpredictable property • important in cryptography and games • Blum method The PSG algorithms introduced in this class are predictable: don’t use them in security or game applications.
summary “randomness” • Kolmogorov complexity and randomness • statistical tests of pseudo-random numbers • 2-test (chi-square test) • algorithms for pseudo-random number generation • linear congruent, M-sequence
exercise • For s = 110010111110001000110100101011101100 (|s|=36), compute 2-values of s for block length with 1, 2, 3 and 4. • Implement the linear congruent method as computer program. • Generate a random number sequence with the program, and plot sampled points as in slide 24.
have nice holidays! NO CLASS on May 1 (TUE) / 5月1日(火)の講義は休講 repot assignment (レポート課題): http://apal.naist.jp/~kaji/lecture/report.pdf • available from the above URL by tomorrow, due May 8(TUE) • 明日までに公開予定,5/8 (火)までに提出