Basic Statistical Concepts
Basic Statistical Concepts. Chapter 2 Reading instructions. 2.1 Introduction: Not very important 2.2 Uncertainty and probability: Read 2.3 Bias and variability : Read 2.4 Confounding and interaction : Read 2.5 Descriptive and inferential statistics : Repetition


Basic Statistical Concepts
E N D
Presentation Transcript
Chapter 2 Reading instructions • 2.1 Introduction: Not very important • 2.2 Uncertainty and probability: Read • 2.3 Bias and variability: Read • 2.4 Confounding and interaction: Read • 2.5 Descriptive and inferential statistics: Repetition • 2.6 Hypothesis testing and p-values: Read • 2.7 Clinical significance and clinical equivalence: Read • 2.8 Reproducibility and generalizability: Read
Bias and variability Bias: Systemtic deviation from the true value Design, Conduct, Analysis, Evaluation Lots of examples on page 49-51
-10 -10 -10 -7 -7 -7 -4 -4 -4 Bias and variability Larger study does not decrease bias Population mean ; bias Distribution of sample means: = population mean Drog X - Placebo Drog X - Placebo Drog X - Placebo mm Hg mm Hg mm Hg n=200 N=2000 n=40
Bias and variability There is a multitude of sources for bias Publication bias Positive results tend to be published while negative of inconclusive results tend to not to be published Selection bias The outcome is correlated with the exposure. As an example, treatments tends to be prescribed to those thought to benefit from them. Can be controlled by randomization Exposure bias Differences in exposure e.g. compliance to treatment could be associated with the outcome, e.g. patents with side effects stops taking their treatment Detection bias The outcome is observed with different intensity depending no the exposure. Can be controlled by blinding investigators and patients Analysis bias Essentially the I error, but also bias caused by model miss specifications and choice of estimation technique Interpretation bias Strong preconceived views can influence how analysis results are interpreted.
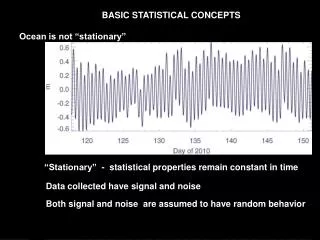
Bias and variability Amount of difference between observations True biological: Variation between subject due to biological factors (covariates) including the treatment. Temporal: Variation over time (and space) Often within subjects. Measurement error: Related to instruments or observers Design, Conduct, Analysis, Evaluation
Placebo DBP (mmHg) Drug X Baseline 8 weeks Raw Blood pressure data Subset of plotted data
Variation in observations Explained variation Unexplained variation = + Bias and variability
Drug A Drug B Bias and variability Is there any difference between drug A and drug B? Outcome
Model: Y=μB+βx μB Y=μA+βx μA x=age Bias and variability
Confounding Confounders Predictors of outcome Predictors of treatment A Treatment allocation Outcome B
Example Smoking Cigaretts is not so bad but watch out for Cigars or Pipes (at least in Canada) Cochran, Biometrics 1968 *) per 1000 person-years %
Example Smoking Cigaretts is not so bad but watch out for Cigars or Pipes (at least in Canada) *) per 1000 person-years % Cochran, Biometrics 1968
Example Smoking Cigaretts is not so bad but watch out for Cigars or Pipes (at least in Canada) *) per 1000 person-years % Cochran, Biometrics 1968
Confounding The effect of two or more factors can not be separated Example: Compare survival for surgery and drug Survival Life long treatment with drug R Surgery at time 0 Time • Surgery only if healty enough • Patients in the surgery arm may take drug • Complience in the drug arm May be poor Looks ok but:
A R M A B R Gender A B R F B Confounding Can be sometimes be handled in the design Example: Different effects in males and females Imbalance between genders affects result Stratify by gender Balance on average Always balance
A B Wash out R B A Interaction The outcome on one variable depends on the value of another variable. Example Interaction between two drugs A=AZD1234 B=AZD1234 + Clarithromycin
Interaction Example: Drug interaction AUC AZD0865: 19.75 (µmol*h/L) AUC AZD0865 + Clarithromycin: 36.62 (µmol*h/L) Ratio: 0.55 [0.51, 0.61]
Interaction Example: Treatment by center interaction Average treatment effect: -4.39 [-6.3, -2.4] mmHg Treatment by center: p=0.01 What can be said about the treatment effect?
Descriptive and inferential statistics The presentation of the results from a clinical trial can be split in three categories: • Descriptive statistics • Inferential statistics • Explorative statistics
Descriptive and inferential statistics Descriptive statistics aims to describe various aspects of the data obtained in the study. • Listings. • Summary statistics (Mean, Standard Deviation…). • Graphics.
Descriptive and inferential statistics Inferential statistics forms a basis for a conclusion regarding a prespecified objective addressing the underlying population. Confirmatory analysis: Hypothesis Results Conclusion
Descriptive and inferential statistics Explorative statistics aims to find interesting results that Can be used to formulate new objectives/hypothesis for further investigation in future studies. Explorative analysis: Results Hypothesis Conclusion?
Hypothesis testing, p-values and confidence intervals Objectives Variable Design Estimate p-value Confidence interval Statistical Model Null hypothesis Results Interpretation
Statistical model: Observations from a class of distribution functions Hypothesis test: Set up a null hypothesis: H0: and an alternative H1: Hypothesis testing, p-values Reject H0 if Significance level Rejection region p-value: The smallest significance level for which the null hypothesis can be rejected.
What is statistical hypothesis testing? A statistical hypothesis test is a method of making decisions using data from a scientific study. Decisions: Conclude that substance is likely to be efficacious in a target population. Scientific study: Collect data measuring efficacy of a substance on a random sample of patients representative of the target population
Formalizing hypothesis testing • We try to prove that collected data with little likelihood can correspond to a statement or a hypothesis which we do not want to be true! • Hypothesis: • The effect of our substance has no effect on blood pressure compared to placebo • An active comparator is superior to our substance • What do we want to be true then? • The effect of our substance has a different effect on blood pressure compared to placebo • Our substance is non-inferior to active comparator
Formalizing hypothesis testing cont. Formalizing it even further… As null hypothesis, H0, we shall choose the hypothesis we want to reject H0: μX = μplacebo As alternative hypothesis, H1, we shall choose the hypothesis we want to prove. H1: μX ≠ μplacebo (two sided alternative hypothesis) μ is a parameter that characterize the efficacy in the target population, for example the Mean.
Example, two sided H1: H0: Treatment with substance X has no effect on blood pressure compared to placebo 0 Difference in BP H1: Treatment with substance X influence blood pressure compared to placebo
Example: one sided H1 H0: Treatment with substance X has no effect on blood pressure compared to placebo Difference in BP 0 H1: Treatment with substance X decrease the blood pressure more than placebo
Structure of a hypothesis test Given our H0 and H1 Assume that H0 is true H0: Treatment with substance X has no effect on blood pressure compared to placebo (μX = μplacebo) 1) We collect data from a scientific study. 2) Calculate the likelihood/probability/chance that data would actually turn out as it did (or even more extreme) if H0 was true; P-value: Probability to get at least as extreme as what we observed given H0
How to interpret the p-value? P-value: Probability to get at least as extreme as what we observed given H0 P-value small: Correct: our data is unlikely given the H0. We don’t believe in unlikely things so something is wrong. Reject H0. Common language: It is unlikely that H0 is true; we should reject H0 P-value large: We can´t rule out that H0 is true; we can´t reject H0 A statistical test can either reject (prove false) or fail to reject (fail to prove false) a null hypothesis, but never prove it true (i.e., failing to reject a null hypothesis does not prove it true).
μX μplacebo μX = μplacebo How to interpret the p-value? Cont. From the assumption that if the treatment does not have effect we calculate: How likely is it to get the data we collected in the study? Expected outcome of the study for some H1 (μX < μplacebo ) Unlikely outcome if the treatments are equal: The p-value is small Expected outcome of the study if H0 is true (μX = μplacebo ) Likely outcome if the treatments are equal: The p-value is big
Risks of making incorrect decisions We can make two types of incorrect decisions: • Incorrect rejection of a true H0 “Type I error”; False Positive 2) Fail to reject a false null hypothesis H0 “Type II error”; False Negative These two errors can´t be completely avoided. We can try to control and minimize the risks of making error is several ways: 1) Optimal study design 2) Deciding the burden of evidence in favor of H1 required to reject H0
Misconceptions and warnings Easy to misinterpret and mix things up (p-value, size of test, significance level, etc). P-value is not the probability that the null hypothesis is true P-value says nothing about the size of the effect. A statistical significant difference does not need to be clinically relevant! A high p-value is not evidence that H0 is true
Distribution of average effect if Ho is true Example: H0: Treatment with substance X has no effect on blood pressure compared to placebo p=0.0156 Difference in BP Xobs=10.4mmHg 0 • If the null hypothesis is true it is unlikely to observe 10.4 • We don’t believe in unlikely things so something is wrong • The data is ”never” wrong • The null hypothesis must be wrong!
Example: Distribution of average effect if Ho is true H0: Treatment with substance X has no effect on blood pressure compared to placebo p=0.35 Difference in BP Xobs=3.2mmHg 0 • If the null hypothesis is true it is not that unlikely to observe 3.2 • Nothing unlikely has happened • There is no reason to reject the null hypothesis • This does not prove that the null hypothesis is true!
A confidence set is a random subset covering the true parameter value with probability at least . Let (critical function) Confidence intervals Confidence set: The set of parameter values correponding to hypotheses that can not be rejected.
Example • We study the effect of treatment X on change in DBP from baseline to 8 weeks • The true treatment effect is: d = μX – μplacebo • The estimated treatment effect is: • How reliable is this estimation?
Hypothesis testing • Test the hypothesis that there is no difference between treatment X and placebo • Use data to calculate the value of a test function: High value -> reject hypothesis, since it is unlikely given not true difference • For a long time it was enough to present the point estimate and the result of the test • Previous example: The estimated treatment effect is 7.5 mmHg, which is significantly different from zero at the 5% level.
Famous (?) quotes “We do not perform an experiment to find out if two varieties of wheat or two drugs are equal. We know in advance, without spending a dollar on an experiment, that they are not equal” (Deming 1975) “Overemphasis on tests of significance at the expense especially of interval estimation has long been condemned” (Cox 1977) “The continued very extensive use of significance tests is alarming” (Cox 1986)
Estimations + Interval Better than just hypothesis test • The estimation gives the best guess of the true effect • The confidence interval gives the accuracy of the estimation, i.e. limits within which the true effect is located with large certainty • One can decide if the result is statistically significant, but also if it has biological/clinical relevance • Now required by Regulatory Authorities, journals, etc Neyman, Jerzy (1937). "Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability". Philosophical Transactions of the Royal Society of London. Series A.
Model: Drug X Placebo σ σ μXμplacebo Example • The 95% confidence interval is [-9.5, -4.9] mmHg (based on a model assuming normally distributed data) • With great likelihood (95%), the interval [-9.5, -4.9] contains the true treatment effect μX – μplacebo • Provided that our model is correct… -9.5 -4.5 0
General principle • There is a True fixed value that we estimate using data from a clinical trial or other experiment • The estimate deviates from the true value (by an unknown amount) • If we were to repeat the study a number of times, the different estimates would be centred around the true value • A 95% confidence interval is an interval estimated so that if the study is repeated a number of times, the interval will cover the true value in 95% of these
General principle • Estimate a parameter, for example • Mean difference, • Relative risk reduction, • Proportion of treatment responders, etc • Calculate an interval that contains the true parameter value with large probability
General principle Depends on confidence level Estimate Quantile Variability ± * Of the estimate Model
General principle – Normal model 67% confidence level Mean 1 ± * SD of the mean Normal model, σ known
General principle – Normal model 95 % confidence level Mean 1.96 ± * SD of the mean Normal model, σ known
General principle – Normal model (1-α)% confidence level Mean t(1-α/2, n-1) ± * SDof the mean Normal model, σnot known
Width • The width of the confidence interval depends on: • Degree of Confidence (90%, 95% or 99%) • Size of the sample • Variability • Statistical model • Design of the study