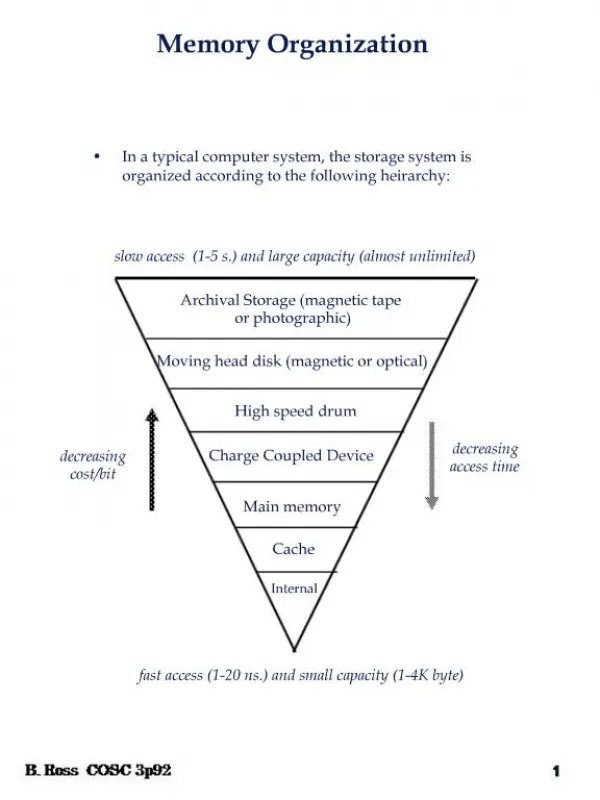
Download

1 / 31
360 likes | 607 Views
12.4 Memory Organization in Multiprocessor Systems. By: Melissa Jamili CS 147, Section 1 December 2, 2003. Overview. Shared Memory Usage Organization Cache Coherence Cache coherence problem Solutions Protocols for marking and manipulating data. Shared Memory. Two purposes

E N D
12.4 Memory Organization in Multiprocessor Systems By: Melissa Jamili CS 147, Section 1 December 2, 2003
Overview • Shared Memory • Usage • Organization • Cache Coherence • Cache coherence problem • Solutions • Protocols for marking and manipulating data
Shared Memory • Two purposes • Message passing • Semaphores
Message Passing • Direct message passing without shared memory • One processor sends a message directly to another processor • Requires synchronization between processors or a buffer
Message Passing (cont.) • Message passing with shared memory • First processor writes a message to the shared memory and signals the second processor that it has a waiting message • Second processor reads the message from shared memory, possibly returning an acknowledge signal to the sender. • Location of the message in shared memory is known beforehand or sent with the waiting message signal
Semaphores • Stores information about current state • Information on protection and availability of different portions of memory • Can be accessed by any processor that needs the information
Organization of Shared Memory • Not organized into a single shared memory module • Partitioned into several memory modules
Interleaving • Process used to divide the shared memory address space among the memory modules • Two types of interleaving • High-order • Low-order
High-order Interleaving • Shared address space is divided into contiguous blocks of equal size. • Two high-order bits of an address determine the module in which the location of the address resides. • Hence the name
Low-order Interleaving • Low-order bits of a memory address determine its module
Low-order Interleaving (cont.) • Low-order interleaving originally used to reduce delay in accessing memory • CPU could output an address and read request to one memory module • Memory module can decode and access its data • CPU could output another request to a different memory module • Results in pipelining its memory requests. • Low-order interleaving not commonly used in modern computers since cache memory
Low-order vs. High-order Interleaving • In a low-order interleaving system, consecutive memory locations reside in different memory modules • Processor executing a program stored in a contiguous block of memory would need to access different modules simultaneously • Simultaneous access possible but difficult to avoid memory conflicts
Low-order vs. High-order Interleaving (cont.) • In a high-order interleaving system, memory conflicts are easily avoided • Each processor executes a different program • Programs stored in separate memory modules • Interconnection network is set to connect each processor to its proper memory module
Cache Coherence • Retain consistency • Like cache memory in uniprocessors, cache memory in multiprocessors improve performance by reducing the time needed to access data from memory • Unlike uniprocessors, multiprocessors have individual caches for each processor
Cache Coherence Problem • Occurs when two or more caches hold the value of the same memory location simultaneously • One processor stores a value to that location in its cache • Other cache will have an invalid value in its location • Write-through cache will not resolve this problem • Updates main memory but not other caches
Cache coherence problem with four processors using a write-back cache
Solutions to the Cache Coherence Problem • Mark all shared data as non-cacheable • Use a cache directory • Use cache snooping
Non-Cacheable • Mark all shared data as non-cacheable • Forces accesses of data to be from shared memory • Lowers cache hit ratio and reduces overall system performance
Cache Directory • Use a cache directory • Directory controller is integrated with the main memory controller to maintain the cache directory • Cache directory located in main memory • Contains information on the contents of local caches • Cache writes sent to directory controller to update cache directory • Controller invalidates other caches with same data
Cache Snooping • Each cache (snoopy cache) monitors memory activity on the system bus • Appropriate action is taken when a memory request is encountered
Protocols for marking and manipulating data • MESI protocol most common • Each cache entry can be in one of the following states: • Modified: Cache contains memory value, which is different from value in shared memory • Exclusive: Only one cache contains memory value, which is same value in shared memory • Shared: Cache contains memory value corresponding to shared memory, other caches can hold this memory location • Invalid: Cache does not contain memory location
How the MESI Protocol Works • Four possible memory access scenarios: • Read hit • Read miss • Write hit • Write miss
MESI Protocol (cont.) • Read hit • Processor reads data • State unchanged
MESI Protocol (cont.) • Read miss • Processor sends read request to shared memory via system bus • No cache contains data • MMU loads data from main memory into processor’s cache • Cache marked as E (exclusive) • One cache contains data, marked as E • Data loaded into cache, marked as S (shared) • Other cache changes from state E to S • More than one cache contains the data, marked as S • Data loaded into cache, marked as S • Other cache states with data remain unchanged • One cache contains data, marked as M (modified) • Cache with modified data temporarily blocks memory read request and updates main memory • Read request continues, both caches mark data as S
MESI Protocol (cont.) • Write hit • Cache contains data in state M or E • Processor writes data to cache • State becomes M • Cache contains data in state S • Processor writes data, marked as M • All other caches mark this data as I (invalid)
MESI Protocol (cont.) • Write miss • Begins by issuing a read with intent to modify (RWITM) • No cache holds data, one cache holds data marked as E, or one or more caches hold data marked S • Data loaded from main memory into cache, marked as M • Processor writes new data to cache • Caches holding this data change states to I • One other cache holds data as M • Cache temporarily blocks request and writes its value back to main memory, marks data as I • Original cache loads data, marked as M • Processor writes new value to cache
Four-processor system using cache snooping and the MESI protocol
Conclusion • Shared memory • Message passing • Semaphores • Interleaving • Cache coherence • Cache coherence problem • Solutions • Non-cacheable • Cache directory • Cache snooping • MESI protocol