Download
1 / 8
80 likes | 149 Views
D-TAU is a discriminative model that considers authors and users together in the generation process of social tags. By incorporating user-topic and author-topic distributions, this model advances tag generation and prediction. Parameters are updated using KL or JS divergence to improve tag prediction accuracy based on supervised information. Explore influencing Gibbs Sampling with supervised data for better tag specificity. Enhance resource comparison by analyzing tag space similarity.

E N D
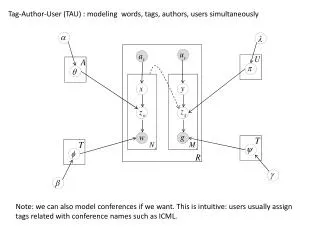
Tag-Author-User (TAU) : modeling words, tags, authors, users simultaneously Note: we can also model conferences if we want. This is intuitive: users usually assign tags related with conference names such as ICML.
Generation Process of D-TAU: For each author , draw author-topic distribution from Dir( ) For each user , draw user-topic distribution from Dir( ) For each topic , draw topic-word distribution from Dir( ) For each topic , draw topic-tag distribution from Dir( ) For each tag g , draw a prob value from Beta( ) For each word w ( ) (1) sample uniformly an author from (1) sample a topic from (1) sample w from 3. For each tag g ( ) (1) sample a situation from Binomial ( , 1.0 - ) (2) if s is “generate from text” a. uniformly sample a topic from a. sample g from (3) if s is “generate from user” a. sample uniformly a user from b. sample a topic from c. sample g from
Significance of TAU: No previous models have considered users and authors at the same time. Users and authors are two types of active selector for words or tags. Conferences: Some tags reflect the conference names: icml, sigir 3. When assigning tags, users may check the authors and conferences. Therefore, it makes sense to consider these factors in the generation process of social tags.
Discriminative TAU (D-TAU): represent in a discriminative, rather than generative, manner
Generation Process of D-TAU: For each author , draw author-topic distribution from Dir( ) For each user , draw user-topic distribution from Dir( ) For each topic , draw topic-word distribution from Dir( ) For each topic , draw topic-tag distribution from Dir( ) For each word w ( ) (1) sample uniformly an author from (1) sample a topic from (1) sample w from 3. For each tag g ( ) only consider “generate from user” (1) sample uniformly a user from (2) sample a topic from (3) sample g from
After each updating: To find the parameters w: KL-divergence or JS-divergence Comments: Use the P(g|r) as supervised information to guide the discriminative process. Problem: How can we influence Gibbs Sampling using P(g|r) ?
Specifity of a tag: An interesting minor point I would like to incorporate into our tasks. But have not figured out how. The similarity of two resources, can be examined in the space of tags





















