BUILDING A HIGHLY ACCURATE MANDARIN SPEECH RECOGNIZER
10 likes | 96 Views
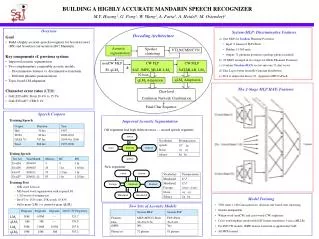
Acoustic segmentation. VTLN/CMN/CVN. Speaker clustering. CW MLP SAT,MLLR, LM 3. nonCW MLP SI, qLM 3. CW PLP SAT, fMPE, MLLR, LM 3. h. N-best. qLM 4 Adaptation. qLM 4 Adaptation. Char-level Confusion Network Combination. Final Char Sequence.

BUILDING A HIGHLY ACCURATE MANDARIN SPEECH RECOGNIZER
E N D
Presentation Transcript
Acoustic segmentation VTLN/CMN/CVN Speaker clustering CW MLP SAT,MLLR, LM3 nonCW MLP SI, qLM3 CW PLP SAT, fMPE, MLLR, LM3 h N-best qLM4 Adaptation qLM4 Adaptation Char-level Confusion Network Combination Final Char Sequence BUILDING A HIGHLY ACCURATE MANDARIN SPEECH RECOGNIZER M.Y. Hwang1, G. Peng1, W. Wang2, A. Faria3, A. Heidel4, M. Ostendorf1 1. Department of Electrical Engineering, University of Washington, Seattle, WA, USA 2. SRI International, Menlo Park, CA, USA 3. ICSI Berkeley, Berkeley, USA 4. Department of Electrical Engineering, National Taiwan University, Taipei, Taiwan Topic-based LM Adaptation Diphthongs for BC Fast Speech Phone-72 vs. Phone 81 on Dev07, nonCW PLP ML, SI, qLM3 Latent Dirichlet Allocation Topic Model One sentence • Training • One topic per sentence. • Train 64 topic-dep. 4-gram LM1 , LM2, … LM64. • Decoding • Top n topics per decoded sentence, where qi’ > threshold. MLP and Pitch Features on Eval04, nonCW ML (Hub4 Training), SI, qLM2 Decoding Architecture • fMPE for the Weaker CW PLP Model • Speaker-independent fMPE applied after speaker-dependent SAT feature transform. • HMM for computing ht is 3500 states x 32 Gaussians/state ML model. • For each frame, compute 5 neighboring frames of Gaussian posteriors: 3500x32x5 = 560K • M is MPE learned. LM Adaptation and CNC • PLP Models Experiments (Character Error Rates) Acoustic Segmentation on Eval06, nonCW MLP, SI, qLM3 • Use Phone-81 pronunciation. • 3500 states x 128 Gaussians/state, decision-tree based state clustering. • Gender-independent. • Cross-word triphone model with SAT feature transform, followed by fMPE feature transform. • MPE trained. Future Work • Topic-dep LM adaptation with fine topics, on either word graphs or word lattices. • Untie /I/ and /IH/ phones for the PLP model.