Download
1 / 36
360 likes | 523 Views
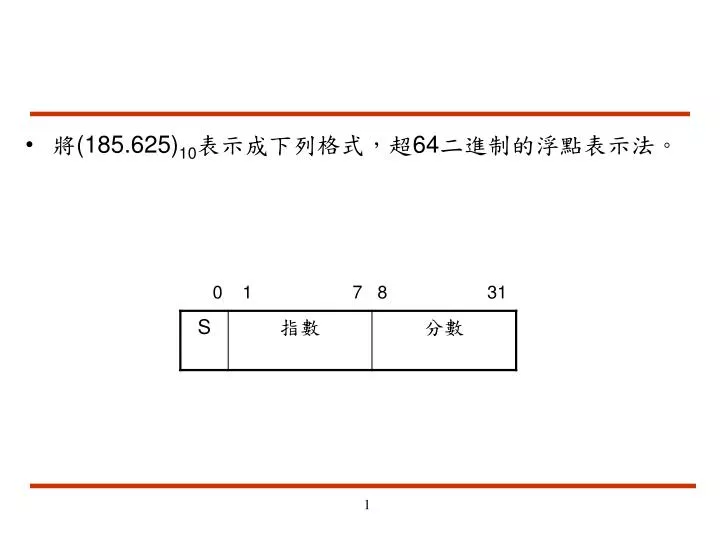
將(185.625) 10 表示成下列格式,超64二進制的浮點表示法。. 0 1 7 8 31. IEEE Single-Precision( 單精倍)浮點表示法如下: Number=(-1) s × 2 ( C-127 ) × ( 1. F) 1. 從記憶體讀出的十六進制值 C2C00000, 其所代表的時進制值為何? 2.若41 B20000 乘以 C1200000 的結果存在記憶體的格式為何?以十六進制表示。.

E N D
將(185.625)10表示成下列格式,超64二進制的浮點表示法。將(185.625)10表示成下列格式,超64二進制的浮點表示法。 0 1 7 8 31
IEEE Single-Precision(單精倍)浮點表示法如下: Number=(-1)s×2(C-127) ×(1.F) 1.從記憶體讀出的十六進制值C2C00000,其所代表的時進制值為何? 2.若41B20000乘以C1200000的結果存在記憶體的格式為何?以十六進制表示。 0 1 8 9 31
有一電腦其浮點表示法如下: • 最大的表示範圍為何? • 最小正數為何? • 十進制的有效位數? 0 1 5 6 15
正負數表示法 • 三種最常見的正負數表示法分別如下 • 『帶符號大小』 • 『1's補數』 • 『2's補數』 • 這三種表示法都必須事先固定位元長度 • 現代電腦使用的是『2's補數』表示法。 • 三種表示法的對照表如下(其中2's補數的負數表示法為1's補數負數+1):
帶符號大小(signed-magnitude) • 帶符號大小的正負數表示法,顧名思義,就是有一個位元用來表示該數值為正數還是負數。這個位元通常位於最左邊。 • 使用n個位元來表達正負整數時,數值的表達範圍就只剩n-1個位元可以使用 • 所以正整數的表達範圍是+0~+(2n-1-1) • 負整數的表達範圍是-(2n-1-1)~-0 • 明顯地,對於0而言,使用帶符號大小表示0的時候,+0與-0是不一樣的。 • 以8位元來表示正負整數時,若採用帶符號大小來表示,方法則如下所列: 8位元的帶符號表示法
1's補數(1's complement) • 1's補數(1's complement)和帶符號表示法的原理不太相同,在1's補數中,如果要表達負數,則必須先求得正整數,然後再將每個位元加以反相(inverse),就可以得到負整數了,所謂反相,其實就是將該位元由1變0或由0變1,如下圖範例: • 在上圖中,我們可以很明顯看到,1's補數的轉換機制是可逆的,換句話說,當您看到一個負的1's補數二進位數字時,如果想要知道該數值代表多少,同樣可以透過反相求出該負整數的絕對值。 1's補數的正負轉換
2's補數(2's complement) • 2's補數(2's complement)是一個最完美的正負二進位整數的表示法,它是基於1's補數演變而來(同樣必須限制表示的位元寬度),也就是當我們要將一個二進位整數變號時,只需要先將其1's補數求出,然後再加1,就可以得到2's補數了,如下圖所示: 2's補數的正負轉換
2's補數(2's complement) • 在上圖中,我們可以很明顯看到,其實2's補數的轉換機制對於『正整數轉負整數』或『負整數轉正整數』所使用的方法都是一樣的,例如,當您看到2's補數二進位負整數110010112時,也可以先將其反相(使用1's補數的方法),然後再加1,就可以得到該負整數的絕對值了。 • 2's補數是現今大多數電腦內部的邏輯電路所採用的整數表示法,因為它具有下列特點: • +0與-0的表示法相同。以8個位元來加以表示+0與-0,都是000000002。 • 可以透過最左邊的位元快速判定該數為正整數或負整數。(最左邊位元為0,一定是正整數或0)。 • 負整數的表達範圍更大,它可以表達的整數範圍是 +(2n-1-1) ~ -2n-1(位元寬度為n時)。而-2n-1的表示法就是1000…0002。 • 可以輕易地使用邏輯電路實作加/減法器,並且正負數轉換機制相同,因此不必額外設計一套電路。
文字資料表示法 • 前面章節介紹了數值資料在電腦的存放方式,而文字資料又是如何被放到記憶體的呢?由於每一個記憶體單元只能接受0、1等2進制的表示法,因此文字資料必須先經由編碼,使得不同的字元對應到唯一的位元圖樣(bit pattern),然後才能存入記憶體中。目前最普遍的編碼為ASCII,繁體中文則為Big5碼。此外,為了統一各國文字的編碼方式,另外也發展了Unicode編碼方式。 • 2.7.1 ASCII碼 • ASCII碼(American Standard Code for Information Interchange,唸做as-key)為美國國家標準局所制定的一種編碼方式,目的是提供一個各類電腦皆通用的編碼方式以便於使得這些電腦可以互通訊息。 • ASCII碼為7個bits,因此可以產生128種變化,每一個變化都可以用來表示一個特殊字符,其中的95個字符為可列印字符,而剩餘的字符則為不可列印的特殊控制字符,例如:換列、倒退鍵、歸位等。詳細的ASCII表如下:
ASCII碼 • 由於1個Bytes為8個Bits,因此留下剩餘的1個Bit並無任何作用,有時將該位元用來記錄同位檢查,或者將ASCII擴充為8個Bits,稱之為ASCII-8,可以產生256種變化。 • ASCII的應用實例非常多,例如您在個人電腦的鍵盤按下一個『H』鍵,它將會被轉換為4816,就是ASCII碼的01001000,然後再存入記憶體中。 • 雖然ASCII是目前最普遍的編碼系統,但並非所有的系統都採用這種編碼方式,例如IBM機器(非IBM PC)則採用8位元碼EBCDIC(Extended Binary Coded Decimal Interchange Code)或ASCII-9,以便表達較多的字元變化。 • 【同位位元檢查】 • 同位位元檢查(parity bit check)是一種偵測錯誤的技術,在送出資料之前,先加上一個同位位元(一般會加在前面),然後才將資料傳送出去,接收端於收到資料後,會檢查每個位元一共包含奇數個1或偶數個1,以便判斷傳輸過程中,是否發生錯誤。 • 因此,同位位元檢查又可以分為奇同位檢查(odd parity check)與偶同位檢查(even parity check)。顧名思義,奇同位檢查的資料位元與同位位元合計一共應該有奇數個1;偶同位檢查的資料位元與同位位元合計一共應該有偶數個1,若接收端發現資料不符合此項規則,則代表資料在傳輸過程中發生了錯誤。(但並非符合規則就是沒有錯誤)
ASCII碼 • 假設,我們採用奇同位檢查,傳送大寫英文字母Q與U,其ASCII碼分別為1010001(Q)與1010101(U),在傳送資料之前,必須先將同位位元加在前面,也就是01010001(Q)與11010101(U),使得位元圖樣共有奇數個1,如下圖所示。 • 對於接收端而言,當它收到01010001與11010101資料時,會先檢查是否每一筆位元圖樣都恰好有奇數個1,如果確實如此,則視為正確,便將同位位元去除,取出原始資料1010001(Q)與1010101(U);如果發現位元圖樣出現偶數個1,則視為資料錯誤,此時可以要求重新再送一次資料,或產生錯誤訊息。 奇同位檢查
ASCII碼 • 使用同位檢查技術,對於所有的奇數個位元的錯誤而言,一定可以被檢測出來;但偶數個(兩個、四個‥‥)位元同時發生錯誤時,將無法發現錯誤。 • 由於同位位元只會使得原本的資料長度多一個位元(甚至不會浪費位元數,例如可以善用ASCII多餘的一個位元來當作同位位元),所以並不會太佔用空間。況且,由於硬體實作或軟體實作只需要使用XOR與NOT兩種邏輯運算即可實現同位檢查,因此雖然無法找出所有的錯誤,但同位檢查技術仍舊被許多應用所採用。 奇同位檢查運作流程
中文內碼 • 中文字與英文字差異極大,英文單字是由許多字母所組成,由於大小寫字母與標點符號加起來並不會超過128種變化,因此可以使用ASCII碼來表示,也就是使用1個位元組就可解決每一個字母的表示法。而中文字多達數萬字,因此必須使用2個位元組來加以儲存一個中文字型的內碼,通常我們將這種編碼方式稱為『雙位元組編碼』,就中文而言則稱為「中文內碼系統」。 • 初期國內發展中文系統時,發展了許多種的中文內碼,例如:BIG5(也可以寫作Big-5;稱為大五碼)、王安碼、CCCII碼(Chinese Character Code for Information Interchange)。 • 目前大多以資策會在1984年所制定的Big-5碼做為中文系統,Big-5碼共提供了五千多個常用字,七千多個次常用字,另外尚有499個特殊符號,因此一共約制訂一萬三千多個中文字內碼。一部份的Big-5碼如下表所列: • (完整的Big-5碼請至http://input.cpatch.org/code/big5.zip下載)
中文內碼 部分BIG5字元表-1
中文內碼 部分BIG5字元表-2
中文內碼 • 【深入探討Big5】 • Big5碼使用兩個位元組來存放資料,而ASCII使用一個位元組來存放資料,假設我們的文章中出現中英混雜的狀況時(例如:『m乘n 』),電腦是如何判斷哪些是中文字,哪些又是英文字母呢? • 為了解決這個問題,Big5的第一個位元組規定一定要比127還要大,如此使用Big5內碼的電腦發現第一個位元組超過127時,就可以判定為中文。 • 例如:『m乘n 』實際上的資料應該是『6DADBC6E』,電腦預定每次讀取一個位元組,當讀到『6D』時,發現比7F還要小,所以直接輸出『m』;當讀到『AD』時,發現比7F還要大,所以必須再讀取一個位元組『BC』,組成Big5碼『ADBC』後,透過查表對應到『乘』,然後才輸出『乘』;最後又讀取一個位元組,讀到『6E』,發現比7F還要小,所以直接輸出『n』,而成為我們看到的『m乘n 』。 • 事實上,128(即A016)也不會出現在Big5碼的第一個位元組,Big5碼的第一個位元組只可能出現(A116 - F916)的數值,同時也不是每一個數值都對應了中文字元(只有其中的3+35+49=87個數值有用),關於Big5的第一個位元組規定如下:
中文內碼 • 至於Big5的第二個位元組則介於4016 - FE16,並且也不是全部都有用到(只有其中的63+94=157個數值有用),關於Big5的第二個位元組規定如下: Big5的第一個位元組 Big5的第二個位元組
中文內碼 • 所以Big5共定義了87*157=13659個中文字。光是這些中文字夠用嗎? • 答案當然是不夠的,話說BIG5之所以叫BIG5,是因為該碼是在1984年由台灣五家電腦公司共同推動,事實上,在這之前,國字整理小組已經整理出七萬多個中文字,而BIG5只能容納一萬三千多個中文字,所以根本不夠用,而且連五家電腦公司之一的宏碁的「碁」都打不出來,更不用說,打不出游錫「堃」等字。 • 由於Big5不夠使用,因此後來又出現了一些改良版,如BIG5_Eten、BIG5-HKSCS、BIG-5E及BIG5_unicode等等,而原本的Big5碼則稱為BIG5_1984。 • 由於版本如此之多,因此也使得軟體支援Big5碼出現不統一的現象。而面對這個問題,大家似乎不想直接在Big5方面著手解決,而期望未來採用Unicode碼加以解決。
Unicode • 除了中文問題之外,事實上許多非英語系國家也面臨文字數量過多的問題,因此,為了統一解決這些問題,又發展了另一套編碼系統,稱之為Unicode。 • Unicode是依據ISO/IEC 10646標準所制定的一套通行全球的編碼系統,Unicode使用2個位元組來表示字元符號,因此可以產生65536個字元,其中最前面的128個字元與ASCII相同。使用Unicode將可以讓電腦處理目前人類所遭遇的所有語系文字,例如:英文、中文、日文、法文、拉丁文‥‥等等,而不需要為各種不同語系設計不同的編碼系統,因此在網際網路中,尤其容易見到。
Unicode • Unicode的優點 • 由於網際網路的發達,因此,跨國性的文件常常會被採用,例如:我們很可能會到大陸網站找尋資料。由於台灣使用的字集是繁體中文字集Big5,而大陸則使用簡體中文字集GB2312,因此,若使用繁體的瀏覽器閱讀簡體網頁時,會發生衝碼現象,也就是可能會出現一些亂碼和部分的繁體中文,這是由於簡體中文內碼恰好對應到某個繁體中文的內碼。 • 而瀏覽網頁發生衝碼現象,主要則是由於該網頁採用各國自行使用的內碼所致,若使用Unicode進行編碼的話,就不會發生這種現象,因為Unicode已經將各國編碼系統打亂,重新制定為單一的編碼系統。並且大多數的瀏覽器都已經支援了Unicode字集,以便顯示包含各國文字的網頁。
Unicode • UTF-16與UTF-8 • Unicode使用16位元進行各國文字的編碼,這種格式稱之為UTF-16。但是對於某些全部都是英文的文件而言,使用UTF-16的16個位元存放英文字母,顯得有些浪費,因此Unicode提供了另一種UTF-8的儲存格式。 • UFT-8的編碼長度並不是固定的8個位元,而是一種可變動式的編碼長度,例如,英文會以8個位元來儲存,但中文就會以24個位元來儲存,因此,如果是中文字出現頻率較高的文件,使用UTF-16格式儲存會比UTF-8來得節省空間。
資料壓縮–減小儲存一筆資料所需的空間大小 • 壓縮率–壓縮後資料大小除以原始資料大小 • 資料壓縮技術可以是資料取得時沒有漏失任何原始資訊的無漏失型,或是資料於壓縮過程會漏失某些資訊的漏失型。
文字壓縮 • 尋找有效率儲存文字以及在一部電腦與另一部之間有效率傳輸文字的方式是很重要的一件事。 • 關鍵字編碼 • 遊程長度編碼 • 霍夫曼編碼
關鍵字編碼 • 將使用頻繁的單字以一個單一字元取代。 例如:
關鍵字編碼(續) • 讓我們將下列段落加以編碼: • The human body is composed of many independent systems, such as the circulatory system, the respiratory system, and the reproductive system. Not only must all systems work independently, they must interact and cooperate as well. Overall health is a function of the well-being of separate systems, as well as how these separate systems work in concert.
關鍵字編碼(續) • 編碼後的段落如下: • The human body is composed of many independent systems, such ^ ~ circulatory system, ~ respiratory system, + ~ reproductive system. Not only & each system work independently, they & interact + cooperate ^ %. Overall health is a function of ~ %- being of separate systems, ^ % ^ how # separate systems work in concert.
關鍵字編碼(續) • 原始段落中包括空白與標點符號共有349個字元,編碼後的段落則有314個字元,結果共節省35個字元。這個範例的壓縮率是314/349或大約0.9 。 • 用來編碼的字元不能為原始文字的一部份。
遊程長度編碼 • 某個單一字元可能於長序列中一再重覆。這種重覆類型並不只是局限於英文文字,也經常發生在大資料流中。 • 遊程長度編碼中,一個序列的重覆字元是由一個旗標字元(flag character),緊接著這個重覆字元,再緊接著一個指示重覆多少次的單一數元來取代。
遊程長度編碼(續) • AAAAAAA 應該被編碼成: *A7 • *n5*x9ccc*h6 some other text *k8eee應該解碼成下列的原始文字: nnnnnxxxxxxxxxccchhhhhh some other text kkkkkkkkeee • 原始字串含有51個字元,編碼後的字串則含有35個字元,因此這個範例的壓縮率是35/51或者是大約0.68。 • 因為我們使用一個字元來計算重覆次數,我們似乎無法將重覆長度超過九個的字串編碼。計數字元以ASCII數元來詮釋可以被取代成以二進制數字來詮釋。
霍夫曼編碼 • 為什麼很少使用於文字的字元“X”應該與使用很頻繁的空白佔用相同的位元數目?霍夫曼使用可變長度位元的字串來表示每一個字元。 • 一些字元可能以五個位元表示,另外一些字元則以六個位元表示,但還沒有以七個位元來表示,之後的位元數目也是如此。
夫曼編碼(續) • 假使我們只使用一些字元來表示經常出現的字元且為不常出現的字元保留更長位元的字串,則整個文件大小就變小了。
夫曼編碼(續) • 例如
夫曼編碼(續) • DOORBELL 以二進制編碼應該為: 1011110110111101001100100. • 如果我們使用固定位元數目(8位元)的字串來表示每一個字元,則原始字串的二進制形式將是8個字元乘以8位元或64位元。這個字串的霍夫曼編碼是25個位元長,得到壓縮比為25/64或大約0.39。 • 霍夫曼編碼的一個重要特徵是,沒有用來表示一個字元的位元字串是其他任何也是用來表示一個字元的位元字串的字首。