Download
1 / 18
180 likes | 273 Views
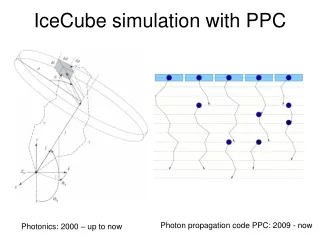
IceCube simulation with PPC. p hoton p ropagation c ode. Dmitry Chirkin, UW Madison. Direct photon tracking with PPC. p hoton p ropagation c ode. simulating flasher/standard candle photons same code for muon/cascade simulation

E N D
IceCube simulation with PPC photon propagation code Dmitry Chirkin, UW Madison
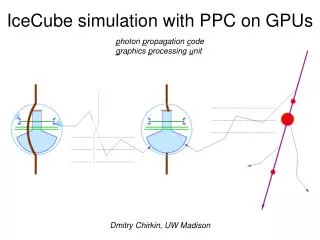
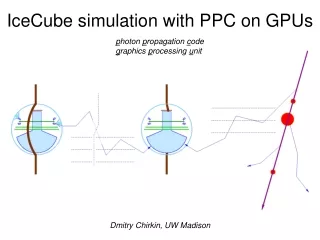
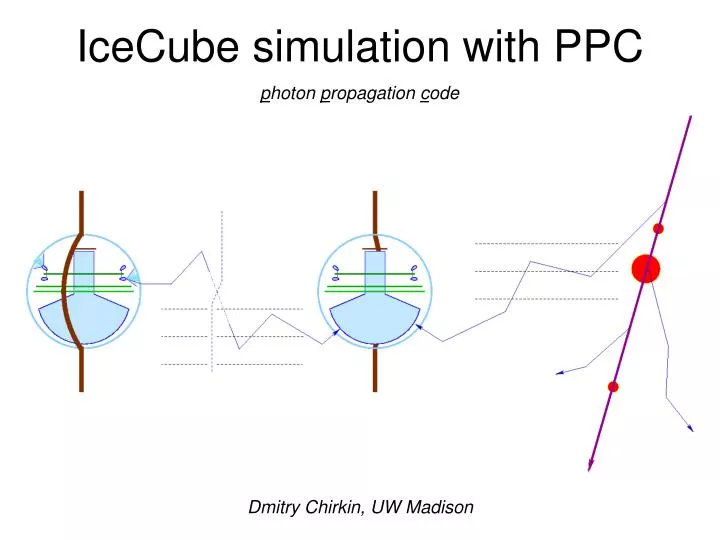
Direct photon tracking with PPC photon propagation code • simulating flasher/standard candle photons • same code for muon/cascade simulation • using precise scattering function: linear combination of HG+SAM • using tabulated (in 10 m depth slices) layered ice structure • employing 6-parameter ice model to extrapolate in wavelength • tilt in the ice layer structure is properly taken into account • transparent folding of acceptance and efficiencies • precise tracking through layers of ice, no interpolation needed • precise simulation of the longitudinal development of cascades and • angular distribution of particles emitting Cherenkov photons
Updates to ppc since last meeting • PPC: • LONG: simulate longitudinal cascade development • ANGW: smear cherenkov cone due to shower development • Corrected ice density to average at detector center • Made the code scalable with the number of GPU multiprocessors • The flasher simulation now uses the wavelength profile read from file wv.dat • Randomized the simulation based on system time (with us resolution) • Modified code to run CPU and GPU parts concurrently • Added option to disable a multiprocessor • Added the implementation of the simple approximate Mie scattering function • Added a configuration file "cfg.txt" • New oversized DOM treatment (designed for minimum bias compared to oversize=1): • oversize only in direction perpendicular to the photon • time needed to reach the nominal (non-oversized) DOM surface is added • re-use the photon after it hits a DOM and ensure the causality in the flasher simulation nominal DOM oversized DOM oversized ~ 5 times photon
Timing of oversized DOM MC xR=1 default 64-48 Flashing 63-50 63-48 xR=1 default do not track back to detected DOM do not track after detection no ovesize delta correction! do not check causality del=(sqrtf(b*b+(1/(e.zR*e.zR-1)*c)-D)*e.zR-h del=e.R-OMR 64-52
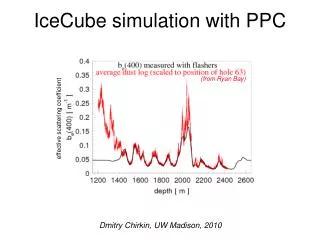
Photon angular profile from thesis of Christopher Wiebusch
New ice density: 0.9216 mwe T=221.5-0.00045319*d+5.822e-6*d2-273.15 (fit to AMANDA data) handbook of chemistry and physics T.Gow's data of density near the surface Fit to (1-p1*exp(-p2*d))*f(T(d))*(1+0.94e-12*9.8*917*d)
Simplified Mie Scattering Also known as the Liu scattering function Introduced by Jon Miller Single radius particles, described better as smaller angles by SAM
ppc icetray module • at http://code.icecube.wisc.edu/svn/projects/ppc/trunk/ • uses a wrapper: private/ppc/i3ppc.cxx, which compiles by cmake system into the libppc.so • it is necessary to compile an additional library libxppc.so by running make in private/ppc/gpu: • “make glib” compiles gpu-accelerated version (needs cuda tools) • “make clib” compiles cpu version (from the same sources!) • link to libxppc.so and libcudart.so (if gpu version) from build/lib directory • this library file must be loaded before the libppc.so wrapper library • These steps are automated with a resouces/make.sh script
ppc example script run.py if(len(sys.argv)!=6): print "Use: run.py [corsika/nugen/flasher] [gpu] [seed] [infile/num of flasher events] [outfile]" sys.exit() … det = "ic86" detector = False … os.putenv("PPCTABLESDIR", expandvars("$I3_BUILD/ppc/resources/ice/mie")) … if(mode == "flasher"): … str=63 dom=20 nph=8.e9 tray.AddModule("I3PhotoFlash", "photoflash")(…) os.putenv("WFLA", "405") # flasher wavelength; set to 337 for standard candles os.putenv("FLDR", "-1") # direction of the first flasher LED … # Set FLDR=x+(n-1)*360, where 0<=x<360 and n>0 to simulate n LEDs in a # symmetrical n-fold pattern, with first LED centered in the direction x. # Negative or unset FLDR simulates a symmetric in azimuth pattern of light. tray.AddModule("i3ppc", "ppc")( ("gpu", gpu), ("bad", bad), ("nph", nph*0.1315/25), # corrected for efficiency and DOM oversize factor; eff(337)=0.0354 ("fla", OMKey(str, dom)), # set str=-str for tilted flashers, str=0 and dom=1,2 for SC1 and 2 ) else:
ppc-pick and ppc-eff • ppc-pick: restrict to primaries below MaxEpri • load("libppc-pick") • tray.AddModule("I3IcePickModule<I3EpriFilt>","emax")( • ("DiscardEvents", True), • ("MaxEpri", 1.e9*I3Units.GeV) • ) • ppc-eff: reduce efficiency from 1.0 to eff • load("libppc-eff") • tray.AddModule("AdjEff", "eff")( • ("eff", eff) • )
Todo list from the last meeting • need to: • verify that it works for V02-04-00 of simulation • add code to treat high-efficient DOMs correctly • verify that it works for IC59 • improve flasher simulation (interface with photoflash) • figure out the best way to compile All done! Done?
ppc homepage http://icecube.wisc.edu/~dima/work/WISC/ppc
GPU scaling Original: 1/2.08 1/2.70 CPU c++: 1.00 1.00 Assembly: 1.25 1.37 GTX 295: 147 157 GTX/Ori: 307 424 C1060: 104 112 C2050: 157 150 GTX 480: 210 204 Uses cudaGetDeviceProperties() to get the number of multiprocessors, Uses cudaFuncGetAttributes() to get the maximum number of threads On GTX 295: 1.296 GHz Running on 30 MPs x 448 threads Kernel uses: l=0 r=35 s=8176 c=62400 On GTX 480: 1.401 GHz Running on 15 MPs x 768 threads Kernel uses: l=0 r=40 s=3960 c=62400 On C1060: 1.296 GHz Running on 30 MPs x 448 threads Kernel uses: l=0 r=35 s=3992 c=62400 On C2050: 1.147 GHz Running on 14 MPs x 768 threads Kernel uses: l=0 r=41 s=3960 c=62400
Kernel time calculation Run 3232 (corsika) IC86 processing on cuda002 (per file): GTX 295: Device time: 1123741.1 (in-kernel: 1115487.9...1122539.1) [ms] GTX 480: Device time: 693447.8 (in-kernel: 691775.9...693586.2) [ms] If more than 1 thread is running using same GPU: Device time: 1417203.1 (in-kernel: 1072643.6...1079405.0) [ms] 3 counters: 1. time difference before/after kernel launch in host code 2. in-kernel, using cycle counter: min thread time 3. max thread time Also, real/user/sys times of top: gpus 6 cpus 1 cores 8 files 693 Real 749m4.693s User 3456m10.888s sys 39m50.369s Device time: 245312940.1 216887330.9 218253017.2 [ms] files: 693 real: 64.8553 user: 37.8357 gpu: 58.9978 kernel: 52.4899 [seconds] 81%-91% GPU utilization
Concurrent execution time Thread 1: CPU GPU CPU GPU Thread 2: GPU CPU GPU CPU Create track segments CPU CPU CPU CPU One thread: GPU GPU GPU GPU Process photon hits Copy photon hits from GPU However: have 2 buffers: 1 on host and 1 on GPU! Just need to synchronize before the buffers are re-used Need 2 buffers for track segments and photon hits Copy track segments to GPU
BAD multiprocessors (MPs) clist cudatest 0 1 2 3 4 5 cuda001 0 1 2 3 4 5 cuda002 0 1 2 3 4 5 cuda003 0 1 2 3 4 5 #badmps cuda001 3 22 cuda002 2 20 cuda002 4 10 Configured: xR=5 eff=0.95 sf=0.2 g=0.943 Loaded 12 angsens coefficients Loaded 6x170 dust layer points Loaded 16028 random multipliers Loaded 42 wavelenth points Loaded 171 ice layers Loaded 3540 DOMs (19x19) Processing f2k muons from stdin on device 2 Total GPU memory usage: 83053520 photons: 13762560 hits: 991 Error: TOT was a nan or an inf 1 times! Bad MP #20 photons: 13762560 hits: 393 photons: 13762560 hits: 570 photons: 13762560 hits: 501 photons: 13762560 hits: 832 photons: 13762560 hits: 717 CUDA Error: unspecified launch failure [dima@cuda002 gpu]$ cat mmc.1.f2k | BADMP=20 ./ppc 2 > /dev/null Configured: xR=5 eff=0.95 sf=0.2 g=0.943 Loaded 12 angsens coefficients Loaded 6x170 dust layer points Loaded 16028 random multipliers Loaded 42 wavelenth points Loaded 171 ice layers Loaded 3540 DOMs (19x19) Processing f2k muons from stdin on device 2 Not using MP #20 Total GPU memory usage: 83053520 photons: 13762560 hits: 871 … photons: 1813560 hits: 114 Device time: 31970.7 (in-kernel: 31725.6...31954.8) [ms] Total GPU memory usage: 83053520 photons: 13762560 hits: 938 Error: TOT was a nan or an inf 9 times! Bad MP #20 #20 #20 #20 photons: 13762560 hits: 442 photons: 13762560 hits: 627 CUDA Error: unspecified launch failure Disable 3 bad GPUs out of 24: 12.5% Disable 3 bad MPs out of 720: 0.4%! Failure rates:
Typical run times • corsika: run 3232: 10493 10.0345 sec files • ic86/spx/3232 on cuda00[123] (53.4 seconds per job) • 1.2 days of real detector time in 6.5 days • nugen: run 2972: 9993 200000-event files; E^-2 weighted • ic86/spx/2972 on cudatest (25.1 seconds per job) • entire 10k set of files in 2.9 days this is enough for an atmnu/diffuse analysis! • Considerations: • Maximize GPU utilization by running only mmc+ppc parts on the GPU nodes • still, IC40 mmc+ppc+detector was run with ~80% GPU utilization • run with 100% DOM efficiency, save all ppc events with at least 1 MC hit • apply a range of allowed efficiencies (70-100%) later with ppc-eff module