Download

1 / 1
10 likes | 290 Views
All-Frequency Precomputed Radiance Transfer for Glossy Objects interactive rendering of shadows, both sharp and soft, on non-diffuse objects. Xinguo Liu, MSRA Peter-Pike Sloan, DirectX Harry Shum, MSRA John Snyder MSR. all-frequency, diffuse lighting=6x32x32 env. map transfer=1x6144 matrix.

E N D
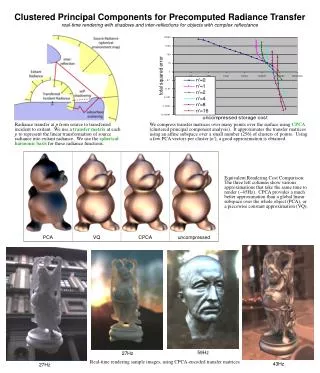
All-Frequency Precomputed Radiance Transfer for Glossy Objects interactive rendering of shadows, both sharp and soft, on non-diffuse objects Xinguo Liu, MSRA Peter-Pike Sloan, DirectX Harry Shum, MSRA John Snyder MSR all-frequency, diffuse lighting=6x32x32 env. map transfer=1x6144 matrix all-frequency, glossy lighting=6x32x32 env. map transfer=10x6144 matrix low-frequency, glossy lighting=5th order spherical harmonics (25 coefs) transfer=25x25 matrix PRT Formulation L = lighting coefficients Mp = transfer matrix (p = surface point) G(v) = view map (v = view vector) good accuracy with m=10 – 10D vector G(v) and 10 rows in matrix Mp uses BRDF factorization: original m=5, error=10% m=10, error=2.1% PRT Clustering/Compression divide lighting env. into 16x16 segments use Clustered Principal Component Analysis on 24 segments (each 2560D) like Vector Quantization but uses a linear subspace (16D) in each cluster lighting segment 1 lighting segment 2 lighting segment 3