Download
1 / 7
70 likes | 157 Views
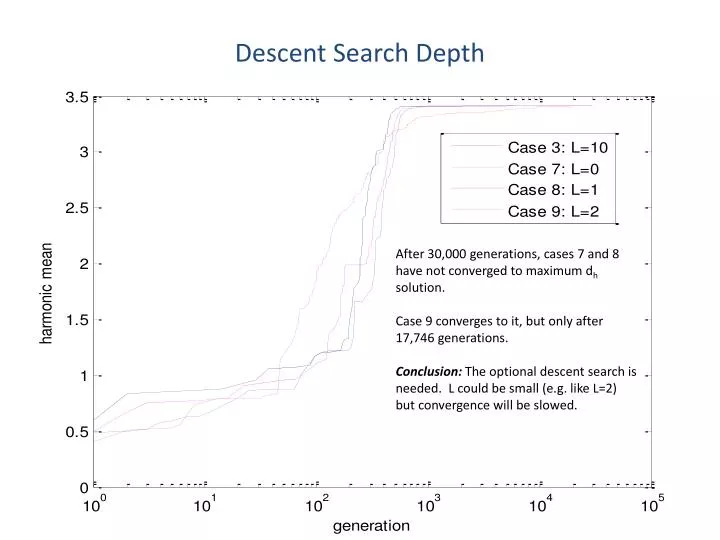
Descent Search Depth. After 30,000 generations, cases 7 and 8 have not converged to maximum d h solution. Case 9 converges to it, but only after 17,746 generations. Conclusion: The optional descent search is needed. L could be small (e.g. like L=2) but convergence will be slowed. Adaptive L.

E N D
Descent Search Depth After 30,000 generations, cases 7 and 8 have not converged to maximum dh solution. Case 9 converges to it, but only after 17,746 generations. Conclusion: The optional descent search is needed. L could be small (e.g. like L=2) but convergence will be slowed.
Adaptive L Case 10 converges to maximum dh solution after 8,987 generations. Conclusion: Though it takes more generations, the overall effort of adaptive approach could be less than using fixed L since fewer mutations will be performed.
Random vs. Preferred Parent Selection Case 1 converged in 12,181 generations to optimal value of 3.4102 Case 2 converged in 2,772 generations, but to suboptimal value of 3.4097 Conclusion: Preferential parent selection speeds convergence, but another mechanism may be needed to improve accuracy.
Culling with a Random Hop Case 3 converged in 2,905 generations to optimal value of 3.4102 Conclusion: “Hopping” slows down convergence, but increases accuracy due to more diversity of design
Increased Population Size After 7,872 generations, case 4 has still not converged. Conclusion: The larger population just slows down convergence. 100 seems to be sufficient.
Using TV for the Initial Populationand Replacements for Duplicates After 1,856 generations, TV population does not appear headed towards the maximum dh solution. Conclusion: Using TV as an initial population starts the algorithm with a higher dh, but replacing duplicates with TV seems to be inhibiting the algorithm from finding the maximum dh solution.
Using TV for the Initial Population whileReplacing Duplicates with Random Permuations Case 6 converges to maximum dh solution after 3,346 generations. Conclusion: By seeding with an initial population of TV designs, algorithm starts with at a local optimal with a higher dh . However, it takes time for the random replacements to pull the algorithm out of the local optimal, thereby slowing convergence.