Download

1 / 38
490 likes | 1.13k Views
Systolic Architectures. Nilda Quintana Ridhanie Suryawan Tom Tichy. Systolic Arrays. A class of parallel processors, named after the data flow through the array, analogous to the rhytmic flow of blood through human arteries after each heartbeat.

E N D
Systolic Architectures Nilda Quintana Ridhanie Suryawan Tom Tichy
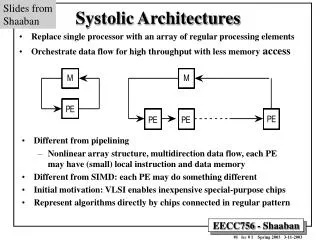
Systolic Arrays • A class of parallel processors, named after the data flow through the array, analogous to the rhytmic flow of blood through human arteries after each heartbeat. • The concept of systolic processing combines a highly parallel array of identical processor may span several integrated circuit chips. • A set of simple Processing Elements with regular and local connections takes external inputs and processes them in a predetermined manner in a pipelined fashion.
M PE M PE PE PE Systolic Arrays • Replace single processor with array of regular Processing Elements. • Orchestrate data flow for high throughput with less Memory access.
Generic Systolic Arrays • In Generic Systolic Arrays; processing units are connected in linear array. Each cell is connected with its immediate neighbours; each cell can exchange data and results with the outside. Furthermore, each cell can receive data from the top and transmit result to the bottom. (The WARP machine can be viewed as GSA of size 10) • It is also to possible to obtained 2-dimensional arrays by stacking several linear arrays and adequately connecting channels together. Other topologies (Ring, Cylinder, Torrus) can be obtained in a similar way.
Cell Pi admits three input channels; Pi can receive data from Pi-1 through channel LRi (Left to Right), from Pi+1 through RLi, and from the outside through Ui (Up). Pi has also three output channels, which allow transmission of results to the left and right neighbours and to the outside. Generic Systolic Arrays Ui U1 Un RLi-1 RLi RL0 RLn-1 RL1 RLn … … P1 Pi Pn LR2 LRi LRn+1 LR1 LRi+1 LRn Di D1 Dn
Ui B[i] C[i] G[i] RLi-1 RLi A[i] E[i] F[i] LRi LRi+1 Di Generic Systolic Arrays
Generic Systolic Arrays • The internal memory of cell Pi contains six communica-tions registers, denoted A[i] , B[i], C[i], E[i], F[i] and G[i]. The remaining part of the memory is denoted M[i] ; its size is independent from the size n of the network. • The program executed by every cell is a loop, whose body is finite, partially ordered by set of statement that specify three kinds of actions: • Receiving values (data) from some input channels, • Performing computations within the internal memory, • Transmitting values (results) to output channels.
Generic Systolic Arrays • The processing units acts with high synchronism (often provided by a global, broadcasted clock). But this can lead to implementation problems. • Another solution is the synchronization by communication, named rendezvous. Value can be transmitted from a cell to another only when both cells are prepared to do so. • During communication phase, only input registers A, C and G are changed; during computation phase, only storage register M and the output registers B, E and F are changed.
Generic Systolic Arrays • Communication Scheme: an order between the internal computation, the reception of data, and the transmission of results. communication ; computation • Other communication scheme with less restrictive: input ; computation ; output • The internal computation phase is not restricted; it can be modelled by function . More specifically, the computation phase consists in executing the assignment (F,E,B,M) := (A,C,G,M).
Space-Time Methodology • The algorithms to be mapped is specified as a set of equations attached to integral points, and mapped on the architecture using a regular time and space allocation scheme. • Four main steps using this methodology: • The index localization (computations to be performed are defined by equation). • Uniformization (indicating where data need to be and where the results are being produced). • Space-Time Transformation (a time and a processor allocations functions are being chosen). • Interface Design (the loading of the data and the unloading of the results are considered).
Space-Time Methodology • The drawbacks of Space Time Methodology: • The algorithm must be specified as a set of recurrence equation, or nested do-loop instructions. Difficult to implement. • Location in space is associated to each index value (well suited for systhesis of regular arrays in which data will be introduced in a regular order). Eliminates possibility of synthesizing with other architectures. • Synthesis of initializations; initial algorithm are slightly modified.
Program-Oriented Methodology • Various attemps have been made to overcome the drawbacks of the space-time transformation methods. Those based on viewing systolic design as program design. • A program-oriented methodology to develop more adequate method of systolic design: • The specifications of the system are formalized with an input and an output predicates, just as in structured programming. • A couple (program and invariant) is deduced in an incremental way from the specification. • The sequential while-program is further transformed into a systolic program; the statement of this program are concurrent assignments. • The systolic array is (easily) obtained from the systolic program.
CryptographyBackground information • Cryptography – disguising messages so only certain people can read them • Cryptography will play an increasing role in future computer and communication system
Types of cryptography • Symmetric – same key used to encrypt and decrypt • Fast algorithm • Requires a one-time use of a secret channel for key exchange • Asymmetric (public key)– different keys to encrypt and decrypt the message • More secure • Slower algorithm
Cryptography RSA algorithm • Today’s systems (SSL, SSH, S/MIME,etc) are based on public key cryptosystem such as RSA • Proposed in 1978 • Based on difficulty of factoring large integers • Three keys – N, E and D • N = (P X Q); P, Q - large prime numbers • Choose a large number E such that it is coprime with (P-1)x(Q-1)
Cryptography RSA algorithm • Compute D such that E x D = 1 mod (P-1)x(Q-1) • The pair (E,N) is the public key • D is the private key • To encrypt a message M:C = ME mod (N) • To decrypt C back to M:M = CD mod (N)
Montgomery algorithm • Computations with integers of length > 500 are very complex and time-consuming • Montgomery algorithm(1985) • reduces modular exponentiation to a series of modular multiplications • Compute (A B) mod N without trial division (q (A B) / N) • Need for faster speed (increasing bit size) and stronger security leads to hardware implementation
Systolic Implementation • Goal: to create fast, secure and efficient way to perform modular multiplication • Number representation: X = i=0 xi r i • r = 2k is the radix • xi is the ith digit • n max no. of digits in any number n-1
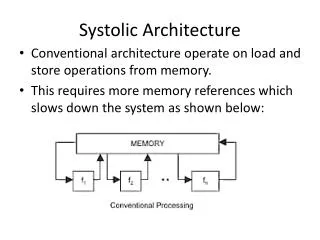
Systolic architectures • Bit-serial architecture • processes one input bit during a clock cycle. Is well suited for low speed applications. • Bit-parallel architecture • processes one input word during a clock cycle. Well suited for high-speed applications, but is area-inefficient • Digit-serial architecture • attempts to utilize the best of both worlds. The speed of bit-parallel and the relative simplicity of bit-serial.
Example: compute A x B • Use n digit multipliers to form aiB and add to a partial product P: P := 0 ; Fori := n1 downto 0do P := rP + aiB { Result: P = AB }
Example: compute A x B • Bit-serial – addition of aiB over n cycles pj+1 bj+1 pj bj pj-1 bj-1 ai ai ai ai time j+1 time j time j-1 carry carry carry carry pj+1 pj pj-1 P := P + aiB (bit-serial) Cell j computes aibj in cycle i+j
Example: compute A x B • Bit-Parallel –add ai xB in one clock cycle ai ai pj+1,s bj+1 pj,c pj,s bj pj-1,c pj-1,s bj-1 cell j+1 cell j cell j-1 pj+1,c pj+1,s pj,c pj,s pj-1,c pj-1,s P := P + aiB (bit-parallel) Cell j computes aibj in cycle i
Montgomery Algorithm P0:=0; q0:=0; For i:=0 to n do Pi+1:=[(Pi + qiN)/2) + biA; qi+1:=Pi mod 2; End P=Pn;
PE for Montogmery • At ith step, the term AiB+QiN is computed in the upper part. • Results are shifted, accumulated in the lower part • Calculations in first n cycles • Output in next n cycles • Zero bit interleaving enables synchronization with the next iteration of the algorithm
Digit-serial implementation • Width of processing elements is u • Only need n/u instead of n processing elements • N_reg (u bits): storage of the modulus • B-reg (u bits): storage of the B multiplier • B+N-reg (u bits): storage of intermediate result B+N • Add-reg (u+1 bits): storage of intermediate results • Control-reg (3 bits): multiplexer control/clock enable • Result-reg (u bits): storage of the result
Conclusion • The need for inexpensive hardware device for real-time RSA encryption/decryption will be rising. • Systolic computer architecture may offer an elegant and flexible solution.
Artificial Neural Networks Introduction The brain processes information extremely fast and accurately. To top that, the trained network still works even if certain neurons fail. For example, it is amazing how one can recognize a friend in a noisy football stadium. This ability of the brain (signal processing) to recognize information, literally buried in noise, and retrieve it correctly is one of the incredible processes that we wish that could be implement in machines. If a machine could be built with only 0.1 percent of the performance capacity of the brain we would already have an extraordinary information and controlling machine.
Artificial Neural Networks Introduction • A neural network is a processing device, either an algorithm, or actual hardware, whose design was motivated by the design and functioning of human brains and its components. • Neurons have elementary computational skills, but they operate in a highly parallel fashion. • An artificial neural network (ANN) can be described as a network of many very simple processors called "units", each possibly having a small amount of local memory or “weight”. The units are connected by unidirectional communication channels called "connections", which carry numeric, as opposed to symbolic, data. The units operate only on their local data and on the inputs they receive via the connections. • Existing neural networks offer improved performance over conventional technologies in areas which includes: Machine Vision, Robust Pattern Detection, Virtual Reality, Data Compression, Data Mining, Text Mining, Artificial Life and more.
Artificial Neural Networks Systolic architectures • Neural networks are non-linear static or dynamical systems that learn to solve problems from examples. Most of the learning algorithms require a lot of computing power and, therefore, could benefit from fast dedicated hardware. One of the most common architectures used for this special-purpose hardware is the systolic array. • There is an underlying similarity between the simple, special purpose computational units of a neural network, and the dedicated processing elements of a systolic array that apply a predefined computation on data elements as the data are pumped through the array.
Artificial Neural NetworksSystolic Arrays • S.Y. Kung and J.N. Hwang were the first researchers to publish a neural model using systolic architecture by devising a scheme to map neural algorithms into an iterative matrix operation. Several matrices mapping models have been proposed since and as technology improves so do the models. • These models have shown that the proper ordering of the elements of the weight matrix makes it possible to design a cascaded dependency graph for consecutive matrix-vector multiplication. • As the research documents accumulates it has become apparent that different systolic architectures have become useful to a very narrow and specific implementation. (e.g. systolic ring arrays and signal processing)
Artificial Neural NetworksSystolic Arrays • Since the early 80s numerous neural algorithms have been mapped into systolic arrays and have been created for systolic arrays. Among the later we have the one-dimensional systolic algorithm created in the 1980s. And the new two-dimensional systolic algorithm implemented in ten years later. • Feature: uses horizontal and vertical product-sum operations for the forward and backward path computing of a multi-layered network.
Artificial Neural NetworksSystolic Arrays: Multi-layered feed-forward neural network
Artificial Neural NetworksSystolic Arrays – backward path 2D