Streamlining SNP Data Control: Error Elimination and Haplotype Prediction Workflow
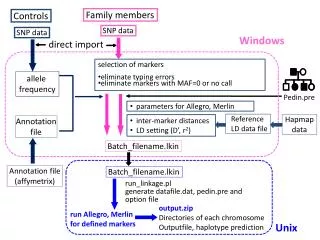
This document outlines a systematic approach for managing SNP data using Windows for direct import. It focuses on selecting markers while eliminating typing errors and those with a minor allele frequency (MAF) of 0 or no call. The parameters required for Allegro and Merlin, as well as the reference linkage disequilibrium (LD) data from HapMap, are specified. Key processes include calculating inter-marker distances, setting LD parameters, generating annotation files, and preparing data files for haplotype prediction. The workflow ensures efficient organization of output files across chromosomes.

Streamlining SNP Data Control: Error Elimination and Haplotype Prediction Workflow
E N D
Presentation Transcript
Family members Controls SNP data SNP data Windows direct import • selection of markers • eliminate typing errors • eliminate markers with MAF=0 or no call allele frequency Pedin.pre • parameters for Allegro, Merlin Reference LD data file Hapmap data • inter-marker distances • LD setting (D’, r2) Annotation file Batch_filename.lkin Annotation file (affymetrix) Batch_filename.lkin run_linkage.pl generate datafile.dat, pedin.pre and option file output.zip Directories of each chromosome Outputfile, haplotype prediction run Allegro, Merlin for defined markers Unix