二进制翻译下的多线程 Replay 系统
二进制翻译下的多线程 Replay 系统. 报告人:刘泽善 导师: 武成岗 时间: 2011 年 3 月. 论文贡献. 动态二进制翻译器平台下源输入程序的确定性 Replay 系统 记录 2.9/3.4/4.3X ,重放 1.9/3.8/7.9X 基于位标识的记录共享内存交互的算法 整数位标识读者集合 时间优势。无需合并向量。 空间优势 。 每个内存块一个向量。 8Thrd 512B 块: 120B/ 内存块,平均 <2M ,最大 14.6M 基于访存指令插桩的纯软件的 Replay 系统的 优化. 目录. 研究意义 背景知识和相关研究工作


二进制翻译下的多线程 Replay 系统
E N D
Presentation Transcript
二进制翻译下的多线程Replay系统 报告人:刘泽善 导师: 武成岗 时间: 2011年3月
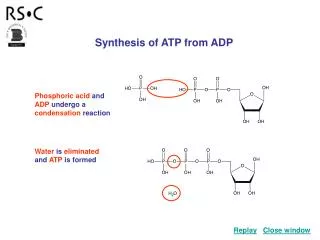
论文贡献 • 动态二进制翻译器平台下源输入程序的确定性Replay系统 • 记录2.9/3.4/4.3X,重放1.9/3.8/7.9X • 基于位标识的记录共享内存交互的算法 • 整数位标识读者集合 • 时间优势。无需合并向量。 • 空间优势。每个内存块一个向量。8Thrd512B块:120B/内存块,平均<2M,最大14.6M • 基于访存指令插桩的纯软件的Replay系统的优化
目录 • 研究意义 • 背景知识和相关研究工作 • 研究内容与贡献 • 系统评测与分析
研究意义 • Replay系统的应用广泛 • 程序调试。多线程程序的调试 • 反向调试。Time-Travel:reverse step/breakpoints/watchpoints • 并行化程序分析。在线Replay分离程序的执行和分析过程降低开销 cpu0 cpu1 cpu2 cpu3 cpu4 A Speculate! B C D
研究意义 • 入侵检测。重现入侵前、入侵时及之后整个系统的状态 • 错误容忍。ExtraVirt比较原执行和复制执行的输出来容忍处理器硬件的暂时性错误;发生灾难性错误而不能继续时由等价的重放执行重建最新的程序状态 • 计算机系统结构研究。ReTrace重放时生成Trace,实现Trace的有效收集和存储
目录 • 研究意义 • 背景知识和相关研究工作 • 研究内容与贡献 • 系统评测与分析
Thread 1 S1: if(thd->proc_info){ S2: fputs(thd->proc_info, …); } MySQL hd_innodb.cc Thread 2 … S3: thd->proc_info = NULL; … Buggy interleaving 背景知识和相关研究工作 • 本文Replay系统应用需求:辅助二进制翻译器的多线程错误调试 • 多线程错误 • Data race, atomicity violation, order violation
多线程程序调试 % gdba.out gdb> run Program received SIGSEGV. In get() at hash.c:45 45 a = bucket->d; • % gcchash.c • % a.out • Segmentation fault • % % gccpara-hash.c % a.out Segmentation fault % % gdb a.out gdb> run Program exited normally. gdb> % gccpara-hash.c % a.out Segmentation fault Race recorded in “log” % % gdba.out log gdb> run Program received SIGSEGV. In get() at para-hash.c:67 67 a = bucket->d;
背景知识和相关研究工作 • 二进制翻译的下多线程错误调试更加困难 • 源输入程序 • 二进制翻译系统 • 对源输入程序确定性记录和重放
多线程Replay系统关键问题 • 单线程程序 • 输入,中断(信号) • 多线程程序 • 共享内存访问顺序 • 单核执行:记录线程之间的调度顺序 • 多核执行:?每一条访存指令都可能与其他线程竞争 • 关键问题:如何高效的记录线程之间的共享内存交互
具有代表性的Replay系统-硬件 • FDR(ISCA’03) • Cache一致性协议的的一致性消息(coherence message)上附加额外信息来检测多核之间的访存依赖 • BugNet(ISCA’05) • 重放单个线程:每条读指令的结果一致 • Cache的每个字上增加了一个FLL (First Load Log)位 • 内存访问顺序:同FDR
具有代表性的Replay系统-硬件 • Lee等(MICRO’09) • 不需要检测和记录共享内存依赖,离线重构 • 修改BugNet的记录读指令结果的方法,Cache Miss时记录Cache Block的数据和指令计数 • Satisfiability Modulo Theory, SMT solver离线求解出每个内存事件的全局序及部分序
具有代表性的Replay系统-硬件 • LReplay(ISCA’10) • 多核处理器能够提供全局时钟 • 记录访存指令的pending period信息 • pending period不相交的两条指令存在物理时间序 • pending period相交的访存指令——直接记录下他们执行序
具有代表性的Replay系统-软件 • InstantReplay(IEEE Tras.’87) • 记录共享对象的访问顺序 • 假设没有数据竞争 • PinPlay(CGO’10) • 记录文件self-contained,记录重放跨操作系统 • 实现了GDB的调试接口 • 共享内存:FDR的软件实现——记录80~146X,重放26~36X
具有代表性的Replay系统-软件 • PRES和ODR(SOSP’09) • 只要求错误重现,并不要求的数据竞争情况一致 • 正式运行中只记录部分信息 • 重放:启发式的搜索算法不断的尝试 • SMP-ReVirt(VEE’08) • 多处理器虚拟机的记录和重放系统 • 硬件页保护机制检测共享内存的读写
具有代表性的Replay系统-软件 • Respec(ASPLOS’10) • Online replay, 2 Thrd 18%,4 Thrd 55% • external determinism:系统输出和最终机器状态一致 • speculative execution: 只记录共享内存交互的少量信息,重放不一致则回滚 • 修改内核和glibc
具有代表性的Replay系统-软件 Thread-parallel execution REPLAY Epoch-parallel execution RECORD (uniparallelism) CPU 0 CPU 1 CPU 2 CPU 3 CPU 4 CPU 5 CPU 6 CPU 7 • DoublePlay(ASPLOS’11) CPU 0 Ep 1 Initial Process State Ep 1 Ep 2 Ep 2 Syscalls Sync ops Signals Ep 3 Ep 3 Syscalls Sync ops Signals Ep 4 Ep 4
目录 • 研究意义 • 背景知识和相关研究工作 • 研究内容与贡献 • 系统评测与分析
研究内容与贡献 • 二进制翻译下多线程程序不确定性 • 基于位标识的记录共享内存交互的算法 • 基于访存指令插桩的纯软件的Replay系统的优化方法
不确定性的记录 • PinPlay(CGO’10)详尽的分析了影响多线程的不确定性因素 • 1. 起始栈位置的改变 • 2. 代码和数据位置的改变 • 3. 程序二进制码以及共享库代码的改变 • 4. 处理器特定指令行为的改变 • 5. 信号 • 6. 未初始化内存的读 • 7. 系统调用行为的改变 • 8. 共享内存访问顺序 DBT下不存在 静态编译避免 SPLASH2不存在
访存依赖 遵循依赖关系 访存依赖 Thread I Thread J Thread I Thread J ld A add ld A add st B st B st C st C st C Log st C ld B ld B ld D ld D st A st A sub sub st C st C ld B ld B st D st D Recording Replay Transitive Reduction消除了ld A st A
B.writer = (I, 2) C.writer =(J, 2) if (C.writer != I) log(WAW) foreachC.readers if (reader != I) log(WAR) C.readers.clear( ) C.writer = (I, 3) if (B.writer != J) log(RAW) B.readers.add(J,3) … 访存依赖关系的检测 A.readers A.writer Thread I Thread J A.readers.add(I, 1) 1 ld A add 1 st B st C 2 2 st C ld B 3 3 st A 4 Recording
B.writer = (I, 2) C.writer =(J, 2) if (C.writer != I) log(WAW) foreachC.readers if (reader != I) log(WAR) C.readers.clear( ) C.writer = (I, 3) if (B.writer != J) log(RAW) B.readers.add(J,3) … FDR的方法 A.readers A.writer Thread I Thread J A.readers.add(I, 1) 1 ld A add 1 st B st C 2 2 st C ld B 3 3 st A 4 Recording VIC VIC VIC VIC VIC VIC 3 0 4 1 3 2 0 2 0 2 0 2 0 2 0 0 0 2 3 2 2 0 1 4
FDR方法的不足 • 原因:减少硬件复杂性 Thread i Thread j Thread k 1: st A 2: ld B 1: st B 2: ld A 1: st B 2: st A FDR方法不能消除的访存依赖
TR算法的不足 • FDR的设计者徐旻的博士论文中提到的Transitive Reduction算法可以消除上述冗余 • 不足:每个内存块需要最多P+1个P维向量,P为线程数,内存开销大 VIC
TR算法的不足 • 依赖关系无论是否需要记录都有对两个向量的合并操作,时间开销大
基于位标识的方法 Data Structures: timestamp_t : array {int t1, int t2, ..., inttP};//P是线程数 block_history_t : structure {intwtid, intwic, intrmask, timestamp_trics} //内存块最近的写者wtid及其访存计数wic,最近的读者访存计数rics,有效读者标识rmask Variables: 线程i私有的: int IC;//访存指令计数 timestamp_t VIC;//VIC[j]线程传递依赖的线程j的最大IC, j != i 每个内存块关联的数据结构: block_history_t block; • 每个内存块只需一个向量
基于位标识的方法 ANALYSE(t, addr)//访存类型t: r, w, rw;访存地址addr 1 IC IC + 1 2 找到addr的关联数据结构block 3 if t & w 4 then if 0 == rmask//查看写者,记录WAW依赖 5 then if (block.wtid != i) && (block.wic > VIC[block.wtid]) 6 then VIC[block.wtid] block.wic 7 record dependence block.wtid:block.wic i:IC 8 elsetid 0 9 whileblock.rmask != 0//遍历所有的读者,记录WAR依赖 10 do if (block.rmask & 1) && (tid != i) 11 then ifblock.rics[tid] > VIC[tid] 12 then VIC[tid] block.rics[tid] 13 record dependence tid:block.rics[tid] i:IC 14 block.rmaskblock.rmask >> 1 15 tidtid + 1 16 block.wtidi 17 block.wic IC 18 block.rmask 0 19 else //记录RAW依赖 20 if (block.wtid != i) && (block.wic > VIC[block.wtid]) 21 then VIC[block.wtid] block.wic 22 record dependence block.wtid:block.wic i:IC 23 rmask |= (1 << i) 24 block.rics[i] IC 检测位标识整数的值,消除FDR不能消除的访存依赖 无需合并向量 Thread i Thread j Thread k 1: st A 2: ld B 1: st B 2: ld A 1: st B 2: st A FDR方法不能消除的访存依赖
基于位标识的方法 • 基于访存指令插桩的方法,原因 • 硬件方法:还没有在实际的处理器采用 • 需要内核支持以及修改glibc的方法:工作量太大 • 页保护的方法:假共享(false sharing)及页竞争的影响,线程数量多时性能不好 • 只记录少量信息,离线重构:重构算法复杂,可以做为将来的工作
基于访存指令插桩的Replay系统的优化方法 • 栈内存访问无需插桩 • 平均37% • 最高84%
基于访存指令插桩的Replay系统的优化方法 • 充分利用目标平台的寄存器资源 • 龙芯的寄存器资源相对于X86-32要充足得多 • caller-saved:18个,上下文切换开销大 • 翻译时利用富余寄存器手工编写插桩函数 • 专用的访存指令计数的寄存器
访存指令计数 • DoublePlay采用记录指令PC以及分支计数的方法记录线程调度序,分支计数硬件PMU提供 • PMU的计数并不区分线程 • 二进制翻译的影响很难做到精确的计数 • 龙芯寄存器资源充裕——专用寄存器计数
基于访存指令插桩的Replay系统的优化方法 • 访存地址关联数据结构优化查找 • 只需要~10指令 • 选择合适大小的内存块,空间开销不大
基于访存指令插桩的Replay系统的优化方法 • 访存依赖关系记录的优化 • 保存在线程私有缓存中,满时输出 • 减少文件竞争及I/O输出的开销 • 内存访问局部性优化 • 当前使用的关联数据结构很可能被下次内存访问使用 • 每个线程缓存当前指令访问的关联数据结构地址
目录 • 研究意义 • 背景知识和相关研究工作 • 研究内容与贡献 • 系统评测与分析
系统评测与分析 二进制翻译系统DigitalBridge
系统评测与分析 • 机器环境
系统评测与分析 • 测试集SPLASH-2
系统评测与分析 • Baseline:无Replay系统功能 • 记录运行 • 2.9/3.4/4.3 • 最大10.4 • <<PinPlay(80~146),但比较的意义不大
系统评测与分析 • 重放 • 1.9/3.8/7.9
系统评测与分析 • 空间开销 • 映射表项数 • 66/77/95 • 最大1047 • 512B内存块时0.39/0.68/1.39M • 最大14.6M
Thread i Thread j 1: ld A 2: ld B 1:st B 2:st A Thread i Thread j 1: ld A 2: ld B 1:st A 2:st B Thread i Thread j 2: ld A 1:st B 1. 记录数据大小无变化 2. 记录数据大小减少 3. 记录数据大小增多 Thread i A B i:2j:1 Thread j A B 系统评测与分析 • 内存块的影响 • 记录数据量 • 内存 • 竞争开销
系统评测与分析 • 不同内存块大小对记录运行的影响,8 Thrd • 512B块大小性能较好
总结 • 动态二进制翻译器平台下源输入程序的确定性Replay系统 • 记录2.9/3.4/4.3X,重放1.9/3.8/7.9X • 基于位标识的记录共享内存交互的算法 • 时间优势。无需合并向量。 • 空间优势。每个内存块一个向量。 • 基于访存指令插桩的纯软件的Replay系统的优化