Download

1 / 19
190 likes | 242 Views
Learn about parsing algorithms such as LL and LR, top-down and bottom-up parsing examples, and the significance of LL(1) and LR(1) parsing methods in computer science. Explore grammar rules and algorithms for effective programming.

E N D
Categories of Grammar Rules • Declarationsordefinitions. AttributeDeclaration::= [ final ] [ static ][ access ] datatype [= expression ]{ , datatype [= expression ] } ; access::= ' public ' | ' protected ' | ' private ' • Statements. • assignment, if, for, while, do_while • Expressions, such as the examples in these slides. • Structuressuch as statement blocks, methods, and entire classes. StatementBlock ::='{' { Statement; }'}'
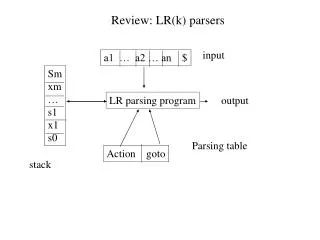
Parsing Algorithms (1) • Broadly divided into LL and LR. • LL algorithms match input directly to left-side symbols, then choose a right-side production that matches the tokens. This is top-down parsing • LR algorithms try to match tokens to the right-side productions, then replace groups of tokens with the left-side nonterminal. They continue until the entire input has been "reduced" to the start symbol • LALR (look-ahead LR) are a special case of LR; they require a few restrictions to the LR case • Reference: Sebesta, section 4.3 - 4.5.
Parsing Algorithms (2) • Look ahead: • algorithms must look at next token(s) to decide between alternate productions for current tokens • LALR(1) means LALR with 1 token look-ahead • LL(1) means LL with 1 token look-ahead • LL algorithms are simpler and easier to visualize. • LR algorithms are more powerful: can parse some grammars that LL cannot, such as left recursion. • yacc, bison, and CUP generate LALR(1) parsers • Recursive-descent is a useful LL algorithm that "every computer professional should know" [Louden].
Top-down (LL) Parsing Example For the input: z = (2*x + 5)*y - 7; tokens:ID = ( NUMBER * ID + NUMBER ) * ID - NUMBER ; Grammar rules (as before): assignment => ID = expression ; expression => expression + term | expression - term | term term => term * factor | term / factor | factor factor => ( expression ) | ID | NUMBER
Top-down Parsing Example (2) The top-down parser tries to match input to left sides. ID = ( NUMBER * ID + NUMBER )* ID - NUMBER ; assignment ID = expression ID =expression-term; ID =term -term; ID =term * factor -term; ID =factor * factor -term; ID = ( expression * factor -term; ID = ( expression +term ) * factor -term; ID = ( term +term ) * factor -term; ID = ( term * factor +term )* factor -term; ID = ( factor * ID+factor )* factor-term; ID = (NUMBER * ID + NUMBER)*factor-term; ID = (NUMBER * ID + NUMBER)* ID-factor; ID = (NUMBER * ID + NUMBER)* ID - ID ;
Top-down Parsing Example (3) • Problem in example:we had to look ahead many tokens in order to know which production to use. • This isn't necessary provided that we know the grammar is parsable using LL (top-down) methods. • There are conditions on the grammar that we can test to verify this. (see: The Parsing Problem) • Later we will study the recursive-descent algorithm which does top-down parsing with minimal look-ahead.
Bottoms-up (LR) Parsing Example (1) tokens: ID = ( NUMBER * ID + NUMBER ) * ID - NUMBER ; parser: ID ... read (shift) first token factor ... reduce factor = ... shift FAIL: Can't match any rules (reduce) Backtrack and try again ID = ( NUMBER ... shift ID = ( factor ... reduce ID = ( term* ... sh/reduce ID = ( term * ID ... shift ID = ( term * factor ... reduce ID = ( term ... reduce ID = ( term+ ... shift ID = ( expression + NUMBER ... reduce/sh ID = ( expression + factor ... reduce ID = ( expression + term ... reduce Action
Bottoms-up Parsing Example (2) tokens: ID = ( NUMBER * ID + NUMBER ) * ID -NUMBER; input: ID = ( expression ... reduce ID = ( expression) ... shift ID = factor ... reduce ID = factor* ... shift ID = term * ID ... reduce/sh ID = term * factor ... reduce ID = term ... reduce ID = term - ... shift ID = expression - ... reduce ID = expression - NUMBER ... shift ID = expression - factor ... reduce ID = expression -term ... reduce ID = expression ; shift assignment reduce SUCCESS!! Start Symbol
Bottoms-up Parsing Example (3) • LR parsing processes the input stream from the Left and tries to match the input to the Right side of a production. • When something matches, it reduces the expression to a left side non-terminal symbol. • Repeat the process until the entire input stream is matched. • This could potentially be an O(n3) task, but Knuth and others devised a table-based algorithm that is O(n).
The Parsing Problem • Top-down parsers must decide which production to use based on the current symbol, and perhaps "peeking" at the next symbol (or two...). • Predictive parser: a parser that bases its actions on the next available token (called single symbol look-ahead). • Two conditions are necessary: [see Louden, p. 108-110]
The Parsing Problem (cont.) Condition 1: the ability to choose between multiple alternatives, such as:A1 | 2|... | n • define First() = set of all tokens that can be the first token for any production cascade that produces symbol • then a predictive parser can be used for rule A if: First(1) First(2)... First(n) is empty. Condition 2: the ability of the parser to detect presence of an optional element, such as A[b]. • Can the parser detect for certain when bis present?
The Parsing Problem (cont.) Example: listexpr[list]. How do we know that list isn't part of expr? • define Follow( ) = set of all tokens that can follow the non-terminal some production. Use a special symbol ($) to represent the end of input if can be the end of input. • Example: Follow( factor ) = { +, -, *, /, ), $ } while Follow( term ) = { *, /, ), $ } • then a predictive parser can detect the presence of optional symbol b if First(b) Follow(b) is empty.
Lexics vs. Syntax vs. Semantics • Division between lexical and syntactic structure is not fixed: • number can be a token or defined by a grammar rule. • Implementation can often decide: • scanners are faster • parsers are more flexible • error checking of number format as regex is simpler • Division between syntax and semantics is not fixed: • we could define separate rules for IntegerNumber and FloatingPtNumber , IntegerTerm, FloatingPtTerm, ... in order to specify which mixed-mode operations are allowed. • or specify as part of semantics
Numbers: Scan or Parse? We can construct numbers from digits using the scanner or parser. Which is easier / better ? • Scanner: Define numbers as tokens: number: [-]\d+ • Parser: grammar rules define numbers (digits are tokens): number=>'-' unsignednumber | unsignednumber unsignednumber => unsignednumber digit|digit digit=>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |9
Is Java 'Class' grammar context-free? • A class may have static and instance attributes. • An inner class or local class have same syntax as top-level class, but: • may not contain static members (except static constants) • inner class may access outer class using OuterClass.this • local class cannot be "public" • Does this means the syntax for a class depends on context?
Alternative operator notation • Some languages use prefix notation: operator comes first expr=>+exprexpr|*exprexpr | NUMBER • Examples: *+ 2 3 4 means (2 + 3) * 4 + 2 * 3 4 means 2 + (3 * 4) • Using prefix notation, we don't have to worry about precedence of different operators in BNF rules !