Download

1 / 15
150 likes | 168 Views
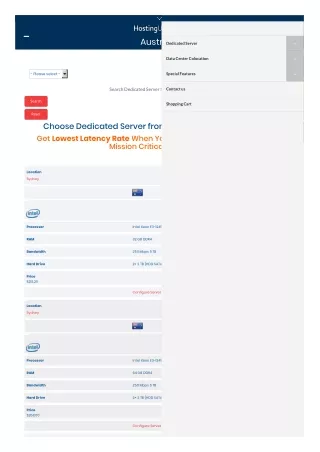
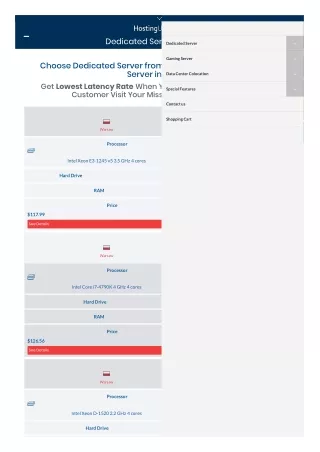
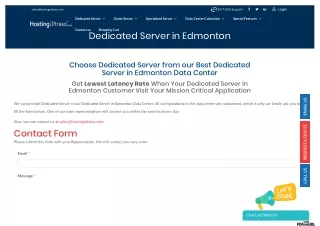
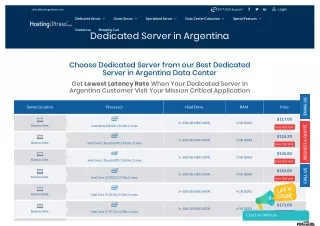
Server Firm Provide Dedicated Server in India Lowest price. Cheap Dedicated server.Best Dedicated server at lowest price. Unmanaged Dedicated server with excellent features at lowest cost. Our Dedicated Servers come made to measure to ensure you get the best results for your business. Provision them with a wide choice of RAM, SSD /HDD hard drives and bandwidth options.<br>High performance, Reliable, affordable dedicated servers. High bandwidth dedicated servers at lowest price. 24X7 supports. Best dedicated server provider.<br>We are providing various type dedicated servers:<br>u2022 Custom Dedicated servers(100% customizable)<br>u2022 Dedicated Server instant setup<br>Please visit website for more details:<br>more: https://server.firm.in <br>IT Monteur, B-71, Shalimar Garden Extn-2, Ghaziabad, UP, India-201005<br>Phone: 91-9582907788t<br> 91-9654016484<br>0120-2631048 <br>Mail: sales@itmonteur.net<br>

E N D
How we do HumanOps at Server Density www.server.firm.in
HumanOps came from experience of Server Density’s team being on call. In the early years, I was on call 24/7 for long periods of time. As the team grew, we implemented policies and processes to help share the load and deal with the challenges of being interrupted or woken up. Through building and selling a monitoring product that is designed to wake people up, we noticed that our customers were experiencing the same kinds of challenges with on call that we had experienced ourselves. Talking with customers revealed this was common within the industry so we examined our own approach and researched best practices within the industry. This led to creating a community to share and discuss a set of principles we called HumanOps. Just like transitioning technical practices to adopt the ideas of DevOps, bringing faster deployment, modern tooling and shared development / operations responsibilities, we are hoping HumanOps will help organization's adopt a human approach to building and operating systems. Here’s how the HumanOps principles work at Server Density. www.server.firm.in
Humans build and fix systems • At the heart of HumanOps are the humans building, running and maintaining the systems. It might be obvious but it’s important to state as the first principle because without acknowledging that running operations necessarily involves humans, it’s too easy to just think about the servers, cloud services and APIs. • In practice, this means ensuring that in all aspects of systems design and management, you think about how humans are involved from the beginning. Areas to consider include: • What aspects of the system operation can be automated? Removing humans from the day to day operation is ideal because they should only be involved when something goes wrong that the system cannot fix. • What alerts should you configure to involve humans? At what point does the system need someone to investigate a problem and is it critical, or something that can be resolved during working hours? • When humans do have to get involved, how is that involvement highlighted to the rest of the team and management? Are you keeping track of out of hours alerts, the frequency and long term trends? www.server.firm.in
2. Humans get tired and stressed, they feel happy and sad This is the starting point for improvements to your processes. When working with computers, you can reasonably expect them to perform in the same way regardless of the time of day. This is, of course, the key benefit of computer systems – they can reliably execute tasks without getting tired. A common mistake is applying the same logic to humans, or simply not thinking about how humans react differently in different situations. Emotions, stress and fatigue introduce variability so catering for this is an important part of designing the system. An example of this is dealing with human error. Computers don’t make mistakes. They won’t suddenly press the wrong button because they were too tired. Humans can, and without the right training and safeguards they probably will. Human error is a natural part of any system, and understanding how that can affect things is important. It should be considered a symptom rather than a problem, and encourage you to look deeper at the context that allowed a human to make the wrong decision. www.server.firm.in
Training is one to way to help here. The goal is for training to be as realistic as possible, so when the real thing happens it feels no different from training. This helps to reduce stress in difficult situations, because you know what you’re supposed to be doing. Stress arises from uncertainty coupled with the pressure of knowing the system is broken, so anything that can be done to alleviate that is beneficial. AtServer Density, we run war games to simulate common alert scenarios, so that everyone knows what they should do in each situation. 3. Systems don’t have feelings yet. They only have SLAs SLAs are a well understood method of defining what you should expect from a particular service or API. You should be able to easily determine whether a service is hitting its SLA or not, and what happens if it doesn’t. This makes it easy to gauge your expectations. www.server.firm.in
4. Humans need to switch off and on again Similar to #2, unlike computers which can run constantly for many months and years, humans need time to rest. Responding to alerts and dealing with complex systems quickly takes its toll, so time to rest and recover must be built into the processes. A human can only maintain focused concentration for 1.5 – 2 hours before needing a break or suffering from deteriorating performance. The way we deal with this at Server Density is through how we schedule our on call rotations. The primary/secondary roles cycle through the team and we have specific response time guidelines depending on whether you are primary or secondary. This helps to reduce the feeling of being tied to your laptop e.g. the secondary isn’t required to respond as quickly so doesn’t necessarily have to be close to their laptop at all times. Further, we have on call recovery time off booked automatically for the next working day whenever you respond to an alert out of hours. The responder has the choice to forgo that time off if they wish but the company will never ask them to do that. This ensures responders have sufficient time to recover and there is no pressure on them not to take it e.g. By asking them to actively request it vs it being given automatically. www.server.firm.in
5. The wellbeing of human operators impacts the reliability of systems Giving people time off after dealing with alerts overnight might sound like us just being nice to our team. However, as nice as it may seem there is also a business reason behind it – people who are tired make mistakes and there are many examples of major outages caused or made worse by operator fatigue. Just like insurance, it can be hard to show a direct benefit because you’re hoping you never have to use it. The benefit of reducing the chances of human error is that something bad does not happen. That can be hard to measure, but there is logical reasoning that if your human operators are happy, they will make better decisions. www.server.firm.in
6. Alert fatigue == Human fatigue Receiving too many alerts is known as alert fatigue. It’s when you receive so many that you tune out and ignore them, potentially missing something important. It defeats the point of alerting, which should be a rare event to notify humans that something serious is wrong. Solving this involves auditing your monitoring to ensure that the alerts you get are actually actionable, and should be actioned. www.server.firm.in
7. Automate as much as possible, escalate to a human as a last resort This is linked to #6 because alerts should only ever reach a human if the system can’t fix itself. Waking someone up to reboot a server or perform a simple manual action is not acceptable. Where something can be scripted, it should be. Humans should only ever be involved to diagnose complex issues and perform unusual actions which must have human decision or supervision. Unfortunately, this is difficult to solve after a system has gone into production. This is because with modern technologies such as Kubernetes and cloud APIs, it is possible to automate recovery of almost every type of failure but it is a lot of work to retrofit new technologies to legacy systems. Of course, there is a cost in both running redundant systems and the time required to implement, but it will repay itself with the time saved from your human team and the reliability offered to customers. The right principle to apply to building new infrastructure is that nothing in production should ever be done manually. Everything should be templated and scripted, so it can be handled automatically. When retrofitting legacy infrastructure, a balance has to be struck because it may not be realistic to rewrite major components into containers, for example. But there may be ways to achieve similar goals e.g. Moving a self-hosted database to a managed service such as AWS RDS. www.server.firm.in
8. Document everything. Train everyone. Nobody really likes writing documentation but it quickly becomes necessary as your team grows and as the system becomes more complex. You need sufficient documentation such that someone with limited knowledge of the detailed internals is able to resolve problems with checklists and run books. Training is just as important, and will help to reveal deficiencies in the documentation. Running realistic simulations in addition to walking people through how things work is essential for anyone on call. At Server Density we make use of Google Drive to help make our documentation easily accessible and searchable to the whole company, but there are plenty of other options for hosting your docs. www.server.firm.in
9. Kill the shame game Getting to the root cause of a problem will almost inevitably mean that you find that someone made a mistake, didn’t plan every scenario, made mistaken assumptions or introduced a bug. This is normal and people should not be shamed as a result because they will be less likely to want to help discover the problems next time. Nobody is perfect and everyone has broken production at least once! The important part is not blaming an individual, but learning how to make the system better and more resilient to those kinds of problems. It is almost never the case that someone deliberately caused a breakage and so people should be comfortable owning up to their mistakes as soon as they realize them, so a fix can be implemented quickly. Failures should be viewed as an opportunity to learn and get better as a team. The way to implement this is with the principle of blameless post-mortems. This involves completing an analysis of the incident to understand what went wrong right down to the root cause but without singling out an individual at fault. www.server.firm.in
10. Human issues are system issues There is a tendency to consider human and system issues separately. It is normal to be able to justify spending on additional system capacity and failover but managers are less used to thinking about human issues with the same priority. All the principles above highlight why human issues are just as important, and so they should be given the same time consideration and budget. When planning our development cycles at Server Density, we often prioritise tasks based on whether the fix will reduce the number of out of hours alerts. Implementing fixes for issues discovered in our incident post mortems becomes high priority if the issue is waking people up, or has the potential to in the future. www.server.firm.in
11. Human health impacts business heath The justification for #10 is that if our human health and wellbeing is impacting on our work and contributing to system problems, and system problems are causing loss of revenue or reputation, then human health is directly related to business health. Hiring is expensive and time consuming so looking after your team is just good business. www.server.firm.in
12. Humans > systems Although it is important to consider humans and systems to be the same in terms of level of impact they have on each other, and how interconnected they are, humans are ultimately the most important. After all, why does your business exist in the first place? To provide a service to other humans! And why do people do a particular job if not to help provide them with a living? Not only that but improving life for your own team is easily justifiable. To be able to hire and retain the best people, you must have good working practices. Constantly being woken up, blaming people for errors and not fixing problems will eventually take its toll on people. Increased stress levels over a prolonged period of time can have significant health impacts and has been linked to high blood pressure, heart disease, obesity and diabetes. Many organisations are unintentionally impacting the health of their employees in significant ways. www.server.firm.in
Server Firm Provide Dedicated Server in India Lowest price. Cheap Dedicated server.Best Dedicated server at lowest price. Unmanaged Dedicated server with excellent features at lowest cost. Our Dedicated Servers come made to measure to ensure you get the best results for your business. Provision them with a wide choice of RAM, SSD /HDD hard drives and bandwidth options.High performance, Reliable, affordable dedicated servers. High bandwidth dedicated servers at lowest price. 24X7 supports. Best dedicated server provider. We are providing various type dedicated servers:• Custom Dedicated servers(100% customizable)• Dedicated Server instant setupPlease visit website for more details: Website:- http://server.firm.in www.server.firm.in