Development of Services in the Fedora Service Framework
320 likes | 600 Views
Development of Services in the Fedora Service Framework. by Gert Schmeltz Pedersen gsp@dtv.dk. Development of Services in the Fedora Service Framework. Contents The Fedora Service Framework The Fedora Generic Search Service Considerations about a Peer-to-Peer Service for Fedora

Development of Services in the Fedora Service Framework
E N D
Presentation Transcript
Development of Services in the Fedora Service Framework by Gert Schmeltz Pedersen gsp@dtv.dk
Development of Services in the Fedora Service Framework • Contents • The Fedora Service Framework • The Fedora Generic Search Service • Considerations about a Peer-to-Peer Service for Fedora • Conclusion
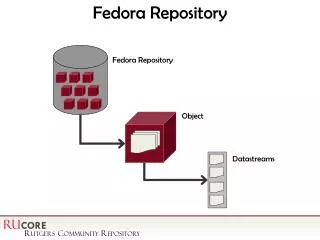
The Fedora Service Framework • Services are stand-alone web applications that run independently of the Fedora repository • Two main benefits to the service framework approach: • allows new functionality to be added as atomic, modular services that can interact with Fedora repositories, yet not be part of the repository, • makes co-development of new services for Fedora easier since each service can be independently developed and plugged into the framework. Flexible Extensible Digital Object Repository Architecture • Powerful digital object model • Extensible metadata management • Expressive inter-object relationships
The Fedora Service Framework • Fedora Object XML (FOXML) is a simple XML format that directly expresses the Fedora digital object model
Development of Services in the Fedora Service Framework • The Fedora Generic Search Service • Background • The DEF-XWS project • Zebra at work • Lucene in action • Approach and requirements • Current prototype (fedoragsearch) • Architectural snapshots • Configuration and customization • Further work • The work is funded by DEFF, Denmark's Electronic Research Library.
Open Archives Initiative Data Providers OAI Harvester Zebra server Zebra server OAI-PMH E X P O R T Web UI w/Z39.50 Web UI w/Z39.50 DEF Portal User OAI Manager E X P O R T Full set Full text retrieval Zebra server M Y S Q L SOAP/REST DEF-XWS Eprints User Batch ingest Web UI w/SOAP java Fedora server Z39.50 Web UI w/REST php DEF-XWS Eprints User AppXYZ w/SOAP perl InfoNetUser AppXYZ User Sub set Librarian Eprint Service Provider Background - DEF-XWS Eprints
Background - DEF-XWS Eprints • Purpose achieved • Fedora hands-on and experience • web services hands-on and experience • DEF-XWS Eprints available from web services • http://defxws.cvt.dk:8082/fedora/access/soap?wsdl • http://defxws.cvt.dk:8082/fedora/accessDEF-XWS/soap?wsdl • and to applications combining many web services • Lesson • Do not override field search, • provide generic search service instead ...
Zebra at work Features • Zebra is provided as open source by Index Data. • Written in portable C, so it runs on most Unix-like systems as well as Windows. • Modules zebraidx and zebrasrv • Searching supports a combination of boolean queries, relevance-ranking, truncation, masking, full regular expression matching and "approximate matching" (eg. spelling mistakes). • Z39.50 protocol support, recently also SRW/SRU and CQL • Configurable to understand many input formats... SGML, XML, ISO2709 (MARC), raw text. • Arbitrarily complex records. • Robust updating - records can be added and deleted “on the fly”. • Very large databases: logical files can be automatically partitioned over multiple disks.
”Lucene in Action” Figure 1.5 A typical application integration with Lucene dc.title:"Information retrieval" AND dc.creator:Staples Document http://lucene.apache.org/java/docs/queryparsersyntax.html Field
Approach and Requirements • Do iterations of requirements analysis and prototype development • allow various indexing-and-search engines to be configured or plugged in, initially Lucene and Zebra • implement as a webapp within the Fedora Service Framework • allow indexing of, and search in, all information in FOXML records for FedoraObjects, including full texts in datastreams and disseminator results • define interface for a set of operations, provide REST and SOAP access • basic operations: • updateIndex - indexing the contents of the Fedora repository • gfindObjects - search similar to Fedora findObjects • secondary operations: • browseIndex - browsing terms in a given index. • getRepositoryInfo - describing the properties of a repository • getIndexInfo - describing the properties of an index • allow multiple repositories to be indexed in one and the same index • allow multiple indexes to be generated from one repository
Current prototype - updateIndex • <foxml:digitalObject … PID="demo:21"> • <foxml:objectProperties> • <foxml:property NAME="http://www.w3.org/1999/02/22-rdf-syntax-ns#type" VALUE="FedoraObject"/> • <foxml:property NAME="info:fedora/fedora-system:def/model#state" VALUE="Active"/> • <foxml:property NAME="info:fedora/fedora-system:def/model#label" VALUE="Sample Document Object (FO to PDF)"/> • <foxml:property NAME="info:fedora/fedora-system:def/model#contentModel" VALUE="FO_TO_PDFDOC"/> • </foxml:objectProperties> • … • <foxml:datastream ID="DC" STATE="A" CONTROL_GROUP="X" VERSIONABLE="true"> • <foxml:datastreamVersion ID="DC1.0" LABEL="Dublin Core for the Document object" CREATED="2006-05-16T10:23:48.376Z" MIMETYPE="text/xml" SIZE="606"> • <foxml:xmlContent> • <oai_dc:dc xmlns:oai_dc="http://www.openarchives.org/OAI/2.0/oai_dc/" xmlns:dc="http://purl.org/dc/elements/1.1/"> • <dc:title>Advanced FO Sample from Apache FOP Distribution</dc:title> • <dc:creator>Apache Group</dc:creator> • </oai_dc:dc> • </foxml:xmlContent> • </foxml:datastreamVersion> • </foxml:datastream> • </foxml:digitalObject> transformation • <IndexDocument … > • <IndexField IFname="PID“ … >demo:21</IndexField> • <IndexField IFname="property.type“ … >FedoraObject</IndexField> • <IndexField IFname="property.state“ … >Active</IndexField> • <IndexField IFname="property.contentModel“ … >FO_TO_PDFDOC</IndexField> • <IndexField IFname="dc.title">Advanced FO Sample …</IndexField> • <IndexField IFname="dc.creator">Apache Group</IndexField> • <IndexField index="TOKENIZED" dsId="DS1" IFname="DS1.text"/> • </IndexDocument>
Architectural snapshots - basic - fedoragsearch • Contents • Lucene • Zebra • fedoragsearch • REST demo • architecture • installation and configuration • further customizations
Configuration and customization • Configuration examples: • fedoragsearch.properties • - soapBase = http://HOSTPORT/fedoragsearch/services • - repositoryNames = REPOSNAMES • - indexNames = INDEXNAMES • mimeTypes = MIMETYPES • INDEXNAME/index.properties • - operationsImpl = dk.defxws.fgslucene.OperationsImpl • defaultQueryFields = dc.description dc.title • REPOSNAME/repository.properties • - soapBase = http://FEDORAHOSTPORT/fedora/services • - fedoraObjectDir = FEDORAOBJECTDIR • Customization examples: • demoFoxmlToLucene.xslt • <IndexField IFname="DS2.text" dsId="DS2" index="TOKENIZED" store="YES" termVector="NO"> • </IndexField> • demoGfindObjectsToHtml.xslt • <script …AJAX-script … /> • <h2>gfindObjects</h2> • <form method="get" action="rest"> • Implement plugin for XyzEngine
Further work • From prototype to production version • Clean up • Give access • Make better Exceptions and error messages • Handle XACML • Notification mechanism • javaDoc • Junit test cases • Test on various platforms • Documentation • Ensuring that we obtain the same high quality as the Fedora code itself has • Takeover by core development team • Contributions from Fedora community
Development of Services in the Fedora Service Framework • Considerationsabout a Peer-to-Peer Service for Fedora • The Background: Alvis utilization activities • The EU project: Alvis - Superpeer Semantic Search Engine • Analysis of alternatives • Design of a Peer-to-Peer service for Fedora
The Background:Alvis utilization activities • The Alvis project is developing an open source prototype of a distributed, semantic-based search engine. • An important consideration in the Alvis project has been how to utilize Alvis results in the Digital Library context. • Therefore, a test case is established with the purpose to utilize Alvis results in the context of the Fedora repository system • (the assumption is that the experience and some principles will be applicable to other digital library systems) • The test plan for this test case has the following steps: • Analysis • Alternative 1: a document enrichment service • Alternative 2: a peer-to-peer service • Design of a peer-to-peer service for Fedora, so that Fedora may act as an Alvis superpeer • Involving the Fedora developer and user community • Implementation of the service • Evaluation of uses of the service
The Alvis EU project • The initial tasks • research in the design, use and interoperability of topic-specific search engines • development of an open-source prototype of a distributed, semantic-based search engine • building on content through automatic analysis of free text • advancing peer-to-peer technology
The Alvis EU project • Peer-to-Peer service • network-wide search • input system can include a crawler, an RSS reader, XML database extraction, etc. • document system does routine processing on documents prior to entry to the runtime system, such as tagging named entities. • maintenance system does processing at the full document collection level to update linguistic and semantic resources used in the document system. • superpeer runs the search engine at a node and provides the user interface. This represents an individual, possibly topic specific search engine. • p2p system provides a network-wide interface to a set of individual search engines using P2P. • Document enrichment service • semi-automatic tagging with semantic knowledge • Peer-to-peer (From Wikipedia, the free encyclopedia) • A peer-to-peer (or P2P) computer network is a network that relies primarily on the computing power and bandwidth of the participants in the network rather than concentrating it in a relatively low number of servers. • The P2P overlay network consists of all the participating peers as its nodes and has links between any two nodes that know each other • Structured P2P networks overcome the limitations of unstructured networks by maintaining a Distributed Hash Table (DHT) and by allowing each peer to be responsible for a specific part of the content in the network.
WP9 User interface SRU/Z39.50 WP8 WP5 Linguistic analysis WP2 Relevance analysis WP3 Indexing engine WP7 Crawler Linguistic format Relevance format Acquisition format WP4 Peer-to-peer WP6 Resource acquisition Chinese contribution Crawler, linguistic analysis and relevance analysis Analysis: Document enrichment service
Analysis: Document enrichment service • Functionality as a Fedora service • Topic-specific crawling based on subject hierarchies • Natural language analysis of content • Entity recognition • Classification of content • Addition of synonyms • Topic specific scores for customised rankings • Too many partners/modules/subsystems involved • Usages of enrichment not clarified
Analysis: Peer-to-Peer service • The initial vision • A set of heterogeneous servers connected into a search network • Each one is wrapped suitably, so as to act as Alvis Search Peers • In this view, Fedora repositories may be wrapped as well. wrapper
Design: alvisp2p service • The alvisp2p service shall implement the interfaces IndexingQuery and Retrieval for interacting with the P2P system, and • implement the necessary operations for interacting with the core Fedora repository service. • Seen from the ALVIS view point we will then have a thin superpeer, • seen from the Fedora view point we will have a Peer-to-Peer service.
Development of Services in the Fedora Service Framework • Conclusion • Two examples of services illustrating the issues in developing services for the Fedora Service Framework • Interaction with Fedora • Reuse from Fedora • Security • A promising development approach for Fedora • Promising in general for Digital Object Repository Systems in Digital Libraries? Thank you
For more information • A Peer-to-Peer Architecture for Information Retrieval Across Digital Library Collections, Technical report LSIR-REPORT-2006-005, March 2006. • Report on abstract model and P2P protocols, ALVIS Deliverable 4.1, 2006. • Beyond term indexing: A P2P framework for Web information retrieval, submitted to thr Informatica journal, December 2005. • Building a peer-to-peer full-text Web search engine with highly discriminative keys, Technical report LSIR-REPORT-2005-011, November 2005. • Using a layered Markov model for distributed web rank computation, ICDCS 2005, Columbus, Ohio, U.S.A., June 2005. • Towards A Common Framework for Peer-to-Peer Web Retrieval, Book Chapter of From Integrated Publication and Information Systems to Virtual Information and Knowledge Environments, EJN-Festschrift, Matthias Hemmje Ed., Springer LNCS 3379, November 2004. • An Architecture for Peer-to-Peer Information Retrieval, in 27th Annual International ACM SIGIR Conference (SIGIR 2004), Workshop on Peer-to-Peer Information Retrieval, July, 2004. • A Query-Adaptive Partial Distributed Hash Table for Peer-to-Peer Systems", in InternationalWorkshop on Peer-to-Peer Computing & DataBases (P2P&DB 2004), Crete, Greece, March 2004.
alvisp2p service scenario Logon to network Receive local query Deliver local hit list Publish document list Publish index Receive global hit list Publish query Logoff from network