Distributed Shared Memory (DSM)
Distributed Shared Memory (DSM). Introduction Basically there are TWO IPC paradigms in DOS Message passing and RPC Distributed Shared Memory (DSM) The DSM provides to processes in a system with a shared address space


Distributed Shared Memory (DSM)
E N D
Presentation Transcript
Introduction • Basically there are TWO IPC paradigms in DOS • Message passing and RPC • Distributed Shared Memory (DSM) • The DSM provides to processes in a system with a shared address space • Processes use this address space in the same way as they use local memory • Primitives used are • data= Read(address) • Write(address, data)
The DSM in tightly coupled system is natural. • In loosely coupled systems there is no physically shared memory available to support DSM paradigm. The term DSM refers to the shared-memory paradigm applied to loosely coupled distributed-memory systems (Virtual Memory)
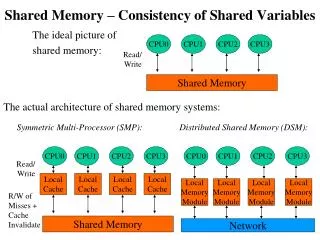
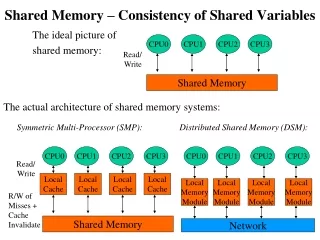
Distributed Shared Memory (Virtual) (Architecture) DSM Block diagram CPU 1 CPU 1 CPU 1 Memory Memory Memory CPU2 CPU2 CPU2 Memory mapping manager Memory mapping manager Memory mapping manager Node-1 Node-2 Node-n Communication Network
DSM architecture • DSM provides a virtual address space shared among processes on loosely coupled processors • DSM is basically an abstraction that integrates the local memory of different machines in a network environment into a single logical entity shared by cooperating processes executing on multiple sites. • The shared memory exists only virtually, hence it is also called (DSVM) • In DSM each node of the system has one or more CPUs and a memory unit. • The nodes are connected by a high-speed communication network. • The DSM abstraction presents a large shared-memory space to the processors of all nodes.
A software memory-mapping manager routine in each node maps the local memory onto the shared virtual memory. • To facilitate the mapping operation, the shared-memory space is partitioned into blocks. • The idea of data caching is used to reduce network latency • The main memory of individual nodes is used to cache blocks of the shared-memory space.
DSM operation when a process on a node wants to access some data from a memory block of the shared memory space • The local memory-mapping manager takes charge of its request. • If the memory block containing the accessed data is resident in the local memory, the request is satisfied. • Otherwise, a network block fault is generated and the control is passed to the operating system. • The OS then sends a message to the node on which the desired memory block is located to get the block.
The missing block is migrated from the remote node to the client process’s node and the OS maps it into the application address space. • Data blocks keep migrating from one node to another on demand basis, but no communication is visible to the user processes. • Copies of data cached in local memory eliminate network traffic. • DSM allows replication/migration of data blocks
Design and Implementation issues of DSM • Granularity: • Refers to the block size of a DSM system • Unit of sharing data or unit of data transfer across network. • Proper block size explores the granularity of parallelism and the amount of network traffic generated by network block faults. • Structure of shared-memory space • Refers to the layout of the shared data in memory. • Depending on the type of application that the DSM system is intended.
Memory coherence and access synchronization • In DSM system, the replication/copies of shared data is available in all nodes, coherence/consistency of accessing of data in particular node is very difficult. • Concurrent access of shared data requires synchronization primitives such as semaphores, event count, lock etc.
Data location and access • To share data in DSM, it is necessary to locate and retrieve the data accessed by a user process. • Replacement strategy • If the local memory of a node is full, the data block of local memory is replaced with the shared data block. • Cache replacement strategy is necessary in DSM
6 Thrashing • In a DSM system, data blocks migrate between nodes on demand. • If two nodes compete for write access to a single data item, the corresponding data block is forced to transfer back and forth at such a high rate that no real work can get done. • The DSM which use a policy to avoid this situation is called thrashing. 7 Heterogeneity • The DSM system is designed to take care of the heterogeneity so that it functions properly with machines with different architectures.
Granularity • Factors influencing block size selection • Paging overhead • Shared-memory programs provide locality of reference, a process is likely to access a large region of its shared address space in a small amount of time. • Paging overhead is less for large block sizes as compared to small blocks. • Directory size • Larger the block size, the smaller the directory • Reduces directory management for larger block sizes. • Thrashing • Thrashing problem may occur with any block size • Different regions in the same block may be updated by processes on different nodes • More prevalent with large block sizes • False sharing • It occurs when two different processes access two unrelated variables that reside in the same data block. • In this situation, even though the original variables are not shared, the data block appears to be shared by two processes.
P1 access data in this area p1 • The larger is the block size, the higher is the probability of false sharing. • False sharing of a block may lead to a thrashing problem. • Using page size as block size • A suitable compromise in granularity adopted in DSM is to use the typical page size of a virtual memory as the block size. • Advantages: • It allows the use of existing page-fault schemes. • Memory coherence problem may be resolved • It allows the access control to be readily integrated into the functionality of the memory management unit. • As long as page can fit into a packet, page size( data block) do not impose undue communication overhead. • Memory contention is resolved. False sharing P2 access data in this area p2 Data block
Structure of shared-memory space • It defines the abstract view of the shared-memory space to be represented to the application programmers of a DSM system • It can be viewed as a storage of data objects. Three approaches used for structuring shared-memory space • No structuring : It is simply a linear array of words • It chooses suitable page size as the unit of sharing and fixed grain size is used for all applications. • Simple and easy to design and implement with any data structure. • Structure by data byte • Memory space is structured as a collection of data objects • The granularity defines the size of objects or variable. • Complicates the design and implementation. • Structure as a data base • The shared memory space is ordered as an associative memory • Memory is addressed as content rather name or address (Tuple space) • Processes select tuples by specifying the number of their fields and values or types • Access to shared data is Nontransparent
Consistency Models • Refers to the degree of consistency that has to be maintained for the shared-memory data to a set of applications. • Strict consistency model • Strongest form of memory coherence • Stringent consistency requirement. • If the value returned by a read operation on a memory address is always same as the value written by the most recent write operation to that address, irrespective of the locations of the processes performing read/write operations. • All write operations are visible to all processes. 2. Sequential consistency models • If all processes see the same order of all memory access operations on the shared memory. • No new memory operation is started until all the previous ones have been completed. • Uses single-copy(one-copy) semantics • Acceptable consistency model for Distributed applications
Causal consistency model • A memory reference operation (read/write) is said to be potentially causally related to another memory reference operation if the first one might have been influenced in any way by the second one. • Eg: Read operation followed by write operation • Write operations are not potentially causally related (w1, w2) • It keep tracks of which memory reference operation is dependent on which other memory reference operations. 4. Pipelined Random-Access memory consistency model (PRAM) • It ensures that all write operations performed by a single process are seen by all other processes in the order they were performed as if all the write operations performed by a single process are in a pipeline • It can be implemented by simply sequencing the write operations performed at each node independently. • All write operations of a single process are pipelined • Simple, easy to implement and has good performance.
Processor consistency model • It ensures that all write operations performed on the same memory location ( no matter by which process they are performed) are seen by all the processes in the same order. • Enhances memory coherence- For any memory location all processes agree on the same order of all write operations to that location. • Weak consistency model • It is not necessary to show the change in memory done by every write operation to other processes. • The results of several write operations can be combined and sent to other processes only when they needed it. • Isolated accesses to shared variables are rare. • Very difficult to show and keep track of the changes at time to time • It uses a special variable called a synchronization variable (SV)for memory synchronization (visible to all processes) Conditions to access synchronization variable (SV) • All accesses to synchronization variables must obey sequential consistency • All previous write operations must be completed before accessing SV. • All previous accesses to SV must be completed before accessing any other variables.
Release consistency model • All changes made to the memory by the process are propagated to other nodes. • All changes made to the memory by other processes are propagated from other nodes the process’s node. • Uses two synchronization variables (Acquire and Release) • Acquire-used by a process to tell the system about entering the critical section. • Release- used by a process to tell about exit from critical section. • Release consistency model uses synchronization mechanism based on barriers. • It defines the end of a phase of execution of a group of concurrent processes before any process is allowed to proceed. Conditions for Release consistency model • All accesses to acquire and release must obey the processor consistency • All previous acquires by a process must be completed before memory accessing by other processes. • All data access by a process must be completed before accessing release.
Implementing Sequential consistency model • Most commonly used consistency model in DSM • Protocols depends on whether the DSM system allows replication/migration of shared-memory blocks • Different strategies are • Non-Replicated, Non-Migrating blocks (NRNMBs) • Non-Replicated, Migrating blocks (NRMBs) • Replicated, Migrating blocks (RMBs) • Replicated, Non-Migrating blocks (RNMBs) • Non-Replicated, Non-Migrating blocks (NRNMBs) • Simplest strategy • Each block of the shared memory has a single copy whose location is always fixed. • All access requests to a block from any node are sent to the owner node of the block, which has the only copy of the block. • On receiving a request from a client node, the MMU and OS of the owner node return a response to the client. • Serializing data access creates a bottle neck • Parallelism is not possible • there is a singe copy of each block in the system • The location of the block never changes Request Owner node Client node Response
Non-Replicated, Migrating blocks • Each block of the shared memory has a single copy in the entire system, however, each access to a block causes the block to migrate from its current node to the node from where it is accessed. • The owner node of a block changes as soon as the block is migrated to a new node. • High locality of reference • It is prone to thrashing • Parallelism is not possible Data locating in NRMB strategy There is a single copy of each block and the location of a block changing dynamically • broadcasting: Each node maintains an owned blocks table that contains an entry for each block for which the node is the current owner. Block request Client node Owner node Block migration Node boundary Block address Block address Node-1 Node-m (Node) Current owner (Node) Current owner
centralized-server algorithm • A centralized server maintains a block table that contains the location information for all blocks in the shared memory space • The centralized sever extracts the location information and forwards it to the requested node. • Failure of server cause the DSM to stop functioning. • The location and identity of centralized server is well known to all nodes Node boundary Node boundary Owner node changes dynamically Block address Node-1 Node-m Contains an Entry for each block Block table
Fixed distributed-server algorithm • It is a direct extension of the centralized server scheme • It overcomes the problems of the centralized server scheme by distributing the role of centralized server. • It has a block manager on several nodes, and each block manager is given a predetermined subset of data blocks to manage. Node boundary Node boundary owner node (dynamic) Owner node (dynamic) Owner node (dynamic) Block address Block address Block address Contains an Entry for each block Contains an Entry for each block Contains an Entry for each block Node-1 Block table Node-2 Block table Node-m Block table
Dynamic distributed-server algorithm • It does not use any block manager and attempts to keep track of the ownership information of all blocks in each node. • Each node has a block table that contains the ownership information of all blocks (probable owner) • This field gives the node a hint on the location of the owner of a block probable node (dynamic) probable node (dynamic) Block address probable node (dynamic) Block address Block address Contains an Entry for each block Contains an Entry for each block Contains an Entry for each block Node-1 Block table Node-2 Block table Node-m Block table
3. Replicated Migrating blocks • To increase parallelism, all DSM systems replicate blocks • With replicated blocks, read operations can be carried out in parallel with multiple nodes, the average cost of read operation is reduced. • However, replication tends to increase the cost of write operations, because for a write to a block all its replicas must be invalidated or updated to maintain consistency. • Replication complicates the memory coherence protocol Basically there are two protocols for enhancing sequential consistency • Write-invalidate • In this scheme, all copies of a piece of data except one are invalidated before write operation can be performed on it. • When a write fault occurs, its fault handler copies the accessed block from one of the block’s to its own node and invalidates all other copies by sending a invalidate message. • The write operation is performed on own node • The own node holds the modified version of block and is replicated to other nodes.
Node-1 3. Invalidate block 1. Request block Write-Invalidate Client node 2. Replicate block Node-2 3. Invalidate block 3. Invalidate block Node-m Nodes having valid copies of the data before write operation Has the valid copy of the data block after write operation
write-update • A write operation is carried out by updating all copies of the data on which the write is performed. • When a write fault occurs at a node, the fault handler copies the accessed block from one of the block’s current nodes to its own node. • Updates all copies of the block by performing the write operation on the local copy . • Send the address of the modified memory location and its new value to the nodes having a copy of the block. • The write operation completes only after all copies of the block have been successfully updated. • After a write operation completes, all the nodes that had a copy of the block before the write also have a valid copy of the block after the write.
Node-1 3. Update block 1. Request block Write- Update Client node 2. Replicate block Node-2 3. Update block 3. Update block Node-m Nodes having valid copies of the data before and after write operation Has the valid copy of the data block after write operation
Global sequencing mechanism • Use a global sequencer to sequence the write operations to all the nodes. • The intended modification of each write operation is first sent to the global sequencer. • The global sequencer multicasts the modification to all the nodes where a replica of data block is located. Nodes 1 Sequenced modification Modification Sequenced modification Global Sequencer 2 Client node Sequenced modification Replica of data Sequenced modification n
Data locating in RMB strategy • The following issues are involved in the write-invalidate protocol • Locating the owner of a block • Keeping track of the nodes that currently have a valid copy of the block • Broadcasting • Each node has an owned blocks table • The block table of a node has an entry for each block for which the node is the owner • The table has a copy-set field that contains a list of nodes that currently have a valid copy of the corresponding block Node boundary Node-1 Node-2 Node-n Block address (dynamic) Copy-set (dynamic) Block address (dynamic) Copy-set (dynamic) Block address (dynamic) Copy-set (dynamic) Contains an entry for each block (owner) Contains an entry for each block (owner) Contains an entry for each block (owner) Owned blocks table Owned blocks table Owned blocks table
centralized-Server algorithm • In this method, each entry of the block table managed by the centralized server, has an owner-node field that indicates the current owner node of the block and a copy-set field that contains a list of nodes having a valid copy of the block. Node boundary Node boundary Node i Node-1 Node-n Block address (Fixed) Copy-set (dynamic) Owner node (dynamic) Contains an entry for each block Block table
Fixed distributed-server algorithm • The role of the centralized server is distributed to several distributed servers • There is a block manager on several nodes • Each block manager manages a predetermined subset of blocks, and a mapping function is used to map a block to a particular block manager and its corresponding node. Node boundary Node boundary Node-n Node-1 Node-2 Owner node (dynamic) Block address (fixed) Copy-set (dynamic) Block address (fixed) Owner node (dynamic) Block address (fixed) Owner node (dynamic) Copy-set (dynamic) Copy-set (dynamic) Contains entries for a fixed subset of all blocks Contains entries for a fixed subset of all blocks Contains entries for a fixed subset of all blocks Block table, Block manager Block table, Block manager Block table, Block manager
4. Dynamic distributed-server algorithm • Each node has a block table that contains an entry for all blocks • Each entry of the table has a probable-owner field that gives the node a hint on the location of the owner. • Each true owner block contains a copy-set field that provides a list of nodes having a valid copy of the block Node boundary Node boundary Node-n Node-1 Node-2 Probable Owner node (dynamic) Probable Owner node (dynamic) Probable Owner node (dynamic) Block address (fixed) Copy-set (dynamic) Block address (fixed) Block address (fixed) Copy-set (dynamic) Copy-set (dynamic) Entry for true owner node Contains an entry for each block Entry for true owner node Entry for true owner node Contains an entry for each block Contains an entry for each block Block table Block table Block table
Replicated Nonmigrating Blocks (RNBs) • In this strategy, a shared-memory block may be replicated at multiple nodes of the system • The location of replica is fixed • A read or write access to a memory address is carried out by sending the access request to one of the nodes having a replica of the block containing the memory address. • Write-update protocol is used • Sequential consistency is ensured by using a Global-sequencer.