Download

1 / 20
210 likes | 448 Views
Kanat Bolazar February 2, 2010. Compiler Design 5 . Top-Down Parsing with a Recursive Descent Parser. Parsing. Lexical Analyzer has translated the source program into a sequence of tokens The Parser must translate the sequence of tokens into an intermediate representation

E N D
Kanat Bolazar February 2, 2010 Compiler Design5. Top-Down Parsingwith aRecursive Descent Parser
Parsing • Lexical Analyzer has translated the source program into a sequence of tokens • The Parser must translate the sequence of tokens into an intermediate representation • Assume that the interface is that the parser can call getNextToken to get the next token from the lexical analyzer • And the parser can call a function called emit that will put out intermediate representations, currently unspecified • The parser outputs error messages if the syntax of the source program is wrong
Parsing: Top-Down, Bottom-Up • Given a grammar such as: • E -> 0 | E + E • And a string to parse such as "0 + 0" • A parser can parse top-down, from start symbol (E above): • E -> E + E -> 0 + E -> 0 + 0 • Or parse bottom-up, grouping terminals into RHS of rules: • 0 + 0 <- E + 0 <- E + E <- E • Usually, parsing is done as tokens are read in: • Top-down: • After seeing 0, we don't yet know which rule to use; • After seeing 0 +, we can expandE to E + E • Bottom-up: 0 can be reduced to E right away, without seeing +
Parsing: Top-Down, Bottom-Up • Generally: • top-down is easier to understand, implement directly • bottom-up is more powerful, allowing more complicated grammars • top-down parsing may require changes to the grammar • Top-down parsing can be done: • programmatically (recursive descent) • by table lookup and transitions • Bottom-up parsing requires table-driven parsing • If the grammar is not complicated, the simplest approach is to implement a recursive-descent parser. • A recursive descent parser does not require backtracking to take alternative paths along the parse (derivation) path.
Recursive Descent Parsing • For every BNF rule (production) of the form <phrase1> Ethe parser defines a function to parse phrase1 whose body is to parse the rule E void parsePhrase1( ) { /* parse the rule E */ } • Where E consists of a sequence of non-terminal and terminal symbols • Requiresno left recursionin the grammar.
Parsing a rule • A sequence of non-terminal and terminal symbols, Y1 Y2 Y3 … Yn is recognized by parsing each symbol in turn • For each non-terminal symbol, Y, call the corresponding parse function parseY • For each terminal symbol, y, call a functionexpect(y)that will check if y is the next symbol in the source program • The terminal symbols are the token types from the lexical analyzer • If the variable currentsymbol always contains the next token: • expect(y): if (currentsymbol == y) • then getNextToken() • else SyntaxError()
Simple parse function example • Suppose that there was a grammar rule <program> ‘class’ <classname> ‘{‘ <field-decl> <method-decl> ‘}’ • Then: • parseProgram(): expect(‘class’); parseClassname(); expect(‘{‘); parseFieldDecl(); parseMethodDecl(); expect(‘}’);
Look-Ahead • In general, one non-terminal may have more than one production, so more than one function should be written to parse that non-terminal. • Instead, we insist that we can decide which rule to parse just by looking ahead one symbol in the input<sentence> -> 'if' '(' <expr> ')' <block>| 'while' '(' <expr> ')' <block> ... • Then parseSentence can have the formif (currentsymbol == "if") • ... // parse first rule • elsif (currentsymbol == "while") • ... // parse second rule ...
First and Follow Sets • First(E), is the set of terminal symbols that may appear at the beginning of a sentence derived from E • And may also include if E can generate an empty string • Follow(<N>), where <N> is a non-terminal symbol in the grammar, is the set of terminal symbols that can follow immediately after any sentence derived from any rule of N • In this grammar: • E -> 0 | E + E • First(0) = {0} First(E + E) = {0} First(E) = {0} • Follow(E) = {+, EOF}
Grammar Restriction 1 • Grammar Restriction 1 (for top-down parsing): • The First sets of alternative rules for the same LHS must be different (so we know which path to take upon seeing a first terminal symbol/token). • Notice: This is not true in the grammar above. Upon seeing 0 we don't know if we should take 0 or E + E path.
Recognizing Possibly Empty Sentences • In a strict context free grammar, there may be rules in which the rhs is , the empty string • Or in an extended BNF grammar, there may be the specification that some part of the rhs of the rule occurs 0 or 1 times <phrase1> … [ <phrase2> ] … • Then we recognize the possibly empty occurrence of phrase2 byif (currentsymbol is in First(<phrase2>)) then parsePhrase2()
Recognizing Sequences • In a context free grammar, you often have rules that specify any number of a phrase can occur <arglist> <arg> <arglist> | e • In extended BNF, we replace this with the * to indicate 0 or more occurrences <arg> * • We can recognize these sequences by using iteration. If there is a rule of the form <phrase1> … <phrase2>* …we can recognize the phrase2 occurrences bywhile (currentsymbol is in First(<phrase2>)) do parsePhrase2()
Grammar Restriction 2 • In either of the previous cases, where the grammar symbol may generate sentences which are empty, the grammar must be restricted • suppose that <phrase2> is the symbol that can occur 0 times • require that the sets First(<phrase2>) and Follow(<phrase2) be disjoint • Grammar Restriction 2: • If a nonterminal may occur 0 times, its First and Follow sets must be different (so we know whether to parse it or skip it on seeing a terminal symbol/token).
Multiple Rules • Suppose that there is a nonterminal symbol with multiple rules where each rhs is nonempty <phrase1> E1 | E2 | E3 | . . . | Enthen we can write ParsePhrase1 as follows: if (currentsymbol is in First( E1 )) then ParseE1 elsif (currentsymbol is in First( E2 )) then ParseE2 . . . elsif (currentsymbol is in First( En )) then ParseEn else Syntax Error • If any rhs can be empty, then don’t give the syntax error • Remember the first grammar restriction: • The sets First( E1 ), … , First( En ) must be disjoint
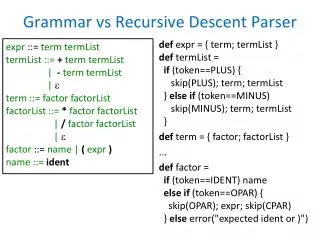
Example Expression Grammar • Suppose that we have a grammar <expr> <term> { <op> <term> }* <term> ‘const’ | ‘(‘ <expr> ‘)’ <op> ‘+’ | ‘-’ • Parsing functions: void parseTerm ( ) { if (cursym == ‘const’) then getNextToken() else if (cursym == ‘(‘) then { getNextToken(); parseExpr(); expect( ‘)’ ) } } void parseExpr ( ) { parseTerm(); while (cursym in First(<op>)) { getNextToken(); parseTerm(); } }
First Sets • Here we give a more formal, and more detailed, definition of a First set, starting with any non-terminal. • If we have a set of rules for a non-terminal, <phrase1> <phrase1> E1 | E2 | E3 | . . . | Enthen First(<phrase1>) = First(E1)+ . . . + First(En ) (set union) • For any right hand side, Y1 Y2 Y3 … Yn , we make cases on the form of the rule • First(aY2 Y3 … Yn) = a , for any terminal symbol a • First(N Y2 Y3 … Yn) = First(N), for any non-terminal N that does not generate the empty string • First([N]M) = First(N) + First(M) (0 or 1 occurrence of N) • First({N}*M) = First(N) + First(M) (0 or more occurrences) • First( ) =
Follow Sets • To define the set Follow(T), examine the cases of where the non-terminal T may appear on the rhs of a rule in the grammar. • N S T U or N S [T] U or N S {T}* U • If U never generates an empty string, then Follow(T) includes First(U) • If U can generate an empty string, then Follow(T) includes First(U) and Follow(N) • N S T or N S [ T ] or N S { T }* • Follow(T) includes Follow(N) • The Follow set of the start symbol should contain EOT, the end of text marker • Include the Follow set of all occurrences of T from the rhs of rules to make the set Follow(T)
Simple Error Recovery • To enable the parser to keep parsing after a syntax error, the parser should be able to skip symbols until it finds a “synchronizing symbol”. • E.g. in parsing a sequence of declarations or statements, skipping to a ‘;’ should enable the parser to start parsing the next declaration or statement
General Error Recovery • A more general technique allows the syntax error routine to be given a list of symbols that it should skip to. void syntaxError(String msg, Symbols StopSymbols) { give error with msg; while (! currentsymbol in StopSymbols) { getNextSymbol } } • assuming that there is a type called Symbols of terminal symbols • we may want to pass an error code instead of a message • Each recursive descent procedure should also take StopSymbols as a parameter, and may modify these to pass to any procedure that it calls • E.g. if there is a procedure to parse the parameter list of a method call, then it can have ‘)’ as a stop symbol
Stop Symbols • If the parser is trying to parse the rhs E of a non-terminal N Ethen the stop symbols are those symbols which the parser is prepared to recognize after a sentence generated by E • Remove anything ambiguous from Follow(N) • The stop symbols should always also contain the end of text symbol, EOT, so that the syntax error routine never tries to skip over symbols past the end of the program.